Sistem terdistribusi kompleks dan membawa risiko terhadap stabilitas infrastruktur, logika aplikasi, serta operasi dan pemeliharaan, yang dapat menyebabkan kegagalan dalam sistem bisnis. Oleh karena itu, penting untuk membangun sistem terdistribusi dengan kemampuan toleransi kesalahan. Topik ini menjelaskan cara menggunakan Service Mesh (ASM) untuk mengonfigurasi timeout, retry, bulkhead, dan mekanisme pemutusan sirkuit guna membangun sistem terdistribusi yang tangguh.
Informasi latar belakang
Toleransi kesalahan adalah kemampuan sistem untuk tetap beroperasi selama sebagian komponen mengalami kegagalan. Untuk menciptakan sistem yang andal dan tangguh, semua layanan dalam sistem harus memiliki toleransi kesalahan. Sifat dinamis dari lingkungan cloud mengharuskan layanan untuk secara proaktif mengantisipasi kegagalan dan merespons insiden tak terduga dengan anggun.
Setiap layanan dapat mengalami permintaan gagal. Langkah-langkah penanganan yang sesuai harus dipersiapkan untuk mengatasi permintaan gagal tersebut. Gangguan pada satu layanan dapat menyebabkan efek domino yang serius bagi bisnis Anda. Oleh karena itu, penting untuk membangun, menguji, dan menerapkan ketahanan sistem. ASM menyediakan solusi toleransi kesalahan yang mendukung mekanisme timeout, retry, bulkhead, dan pemutusan sirkuit tanpa perlu memodifikasi kode aplikasi.
Pemrosesan timeout
Cara kerjanya
Ketika klien mengirimkan permintaan ke layanan upstream, layanan tersebut mungkin tidak merespons. Anda dapat mengatur periode timeout. Jika layanan upstream tidak merespons dalam periode timeout, klien akan menganggap permintaan gagal dan tidak lagi menunggu respons.
Setelah periode timeout diatur, aplikasi akan menerima kesalahan jika layanan backend tidak merespons dalam waktu yang ditentukan. Aplikasi kemudian dapat mengambil tindakan fallback yang sesuai. Pengaturan timeout menentukan waktu tunggu klien untuk respons layanan, namun tidak memengaruhi perilaku pemrosesan layanan. Dengan demikian, timeout tidak berarti bahwa operasi yang diminta telah gagal.
Solusi
ASM memungkinkan Anda mengonfigurasi kebijakan timeout untuk rute dalam layanan virtual guna menentukan periode timeout. Jika proxy sidecar tidak menerima respons dalam periode timeout, permintaan dianggap gagal. Setelah pengaturan timeout diterapkan pada rute, pengaturan tersebut berlaku untuk semua permintaan yang menggunakan rute tersebut.
apiVersion: networking.istio.io/v1beta1
kind: VirtualService
metadata:
name: httpbin
spec:
hosts:
- 'httpbin'
http:
- route:
- destination:
host: httpbin
timeout: 5stimeout: menentukan periode timeout. Jika layanan yang diminta tidak merespons dalam periode timeout yang ditentukan, kesalahan dikembalikan, dan klien tidak lagi menunggu respons.
Mekanisme retry
Cara kerjanya
Jika layanan mengalami kegagalan permintaan seperti timeout permintaan, timeout koneksi, atau gangguan layanan, Anda dapat mengonfigurasi mekanisme retry untuk mengulangi permintaan layanan.
Hindari melakukan retry terlalu sering atau terlalu lama, karena dapat menyebabkan kegagalan berantai.
Solusi
ASM memungkinkan Anda membuat layanan virtual untuk mendefinisikan kebijakan retry permintaan HTTP. Dalam contoh ini, layanan virtual dibuat untuk mendefinisikan kebijakan retry berikut: Ketika layanan dalam instance ASM meminta aplikasi httpbin, layanan tersebut akan mengulangi permintaan hingga maksimal tiga kali jika aplikasi httpbin tidak merespons atau layanan gagal membangun koneksi ke aplikasi httpbin. Periode timeout untuk setiap permintaan adalah 5 detik.
apiVersion: networking.istio.io/v1beta1
kind: VirtualService
metadata:
name: httpbin
spec:
hosts:
- 'httpbin'
http:
- route:
- destination:
host: httpbin
retries:
attempts: 3
perTryTimeout: 5s
retryOn: connect-failure,resetAnda dapat mengonfigurasi bidang berikut dalam struktur retries untuk menyesuaikan perilaku retry proxy sidecar untuk permintaan.
Bidang | Deskripsi |
attempts | Menentukan jumlah maksimum retry untuk permintaan. Jika baik mekanisme retry maupun periode timeout untuk rute layanan dikonfigurasi, jumlah sebenarnya dari retry bergantung pada periode timeout. Misalnya, jika permintaan belum mencapai jumlah maksimum retry tetapi total waktu yang dihabiskan untuk semua retry melebihi periode timeout, proxy sidecar berhenti mencoba permintaan dan mengembalikan respons timeout. |
perTryTimeout | Menentukan periode timeout untuk setiap retry. Unit: milidetik, detik, menit, atau jam. |
retryOn | Menentukan kondisi di mana retry dilakukan. Pisahkan beberapa kondisi retry dengan koma (,). Untuk informasi lebih lanjut, lihat kondisi retry umum untuk permintaan HTTP dan kondisi retry umum untuk permintaan gRPC. |
Tabel berikut memberikan kondisi umum untuk retry permintaan HTTP.
Kondisi Retry | Deskripsi |
connect-failure | Retry dilakukan jika permintaan gagal karena koneksi ke layanan upstream gagal (seperti timeout koneksi). |
refused-stream | Retry dilakukan jika layanan upstream mengembalikan frame REFUSED_STREAM untuk mereset aliran. |
reset | Retry dilakukan jika terjadi pemutusan, reset, atau acara timeout baca sebelum layanan upstream merespons. |
5xx | Retry dilakukan jika layanan upstream mengembalikan kode respons 5XX, seperti 500 atau 503, atau layanan upstream tidak merespons. Catatan Kondisi retry 5xx mencakup kondisi retry connect-failure dan refused-stream. |
gateway-error | Retry dilakukan jika layanan upstream mengembalikan kode status 502, 503, atau 504. |
envoy-ratelimited | Retry dilakukan jika header x-envoy-ratelimited ada dalam permintaan. |
retriable-4xx | Retry dilakukan jika layanan upstream mengembalikan kode status 409. |
retriable-status-codes | Retry dilakukan jika kode status yang dikembalikan oleh layanan upstream menunjukkan bahwa retry diperbolehkan. Catatan Anda dapat menambahkan kode status valid ke bidang retryOn untuk menunjukkan bahwa retry diperbolehkan, seperti |
retriable-headers | Retry dilakukan jika header respons yang dikembalikan oleh layanan upstream berisi header yang menunjukkan bahwa retry diperbolehkan. Catatan Anda dapat menambahkan header |
gRPC menggunakan HTTP/2 sebagai protokol transfernya. Oleh karena itu, Anda dapat mengatur kondisi retry permintaan gRPC di bidang retryOn dari kebijakan retry untuk permintaan HTTP. Tabel berikut memberikan kondisi umum untuk retry permintaan gRPC.
Kondisi Retry | Deskripsi |
cancelled | Retry dilakukan jika kode status gRPC dalam header respons layanan gRPC upstream adalah cancelled (1). |
unavailable | Retry dilakukan jika kode status gRPC dalam header respons layanan gRPC upstream adalah unavailable (14). |
deadline-exceeded | Retry dilakukan jika kode status gRPC dalam header respons layanan gRPC upstream adalah deadline-exceeded (4). |
internal | Retry dilakukan jika kode status gRPC dalam header respons layanan gRPC upstream adalah internal (13). |
resource-exhausted | Retry dilakukan jika kode status gRPC dalam header respons layanan gRPC upstream adalah resource-exhausted (8). |
Konfigurasikan kebijakan retry default untuk permintaan HTTP
Secara default, layanan dalam ASM mengadopsi kebijakan retry default untuk permintaan HTTP ketika mereka mengakses layanan HTTP lainnya, meskipun tidak ada kebijakan retry yang didefinisikan menggunakan layanan virtual. Jumlah retry dalam kebijakan default adalah dua, tanpa periode timeout yang diatur. Kondisi retry default meliputi connect-failure, refused-stream, unavailable, cancelled, dan retriable-status-codes. Anda dapat mengonfigurasi kebijakan retry default untuk permintaan HTTP di halaman Basic Information di konsol ASM. Setelah konfigurasi, kebijakan retry default baru akan menggantikan kebijakan default asli.
Fitur ini hanya tersedia untuk instance ASM versi 1.15.3.120 atau lebih baru. Untuk informasi lebih lanjut tentang cara memperbarui instance ASM, lihat memperbarui instance ASM.
Masuk ke konsol ASM. Di panel navigasi kiri, pilih .
Di halaman Mesh Management, klik nama instance ASM. Di panel navigasi kiri, pilih .
Di bagian Config Info halaman Base Information, klik Edit di sebelah Default HTTP retry policy.
Di kotak dialog Default HTTP retry policy, konfigurasikan parameter terkait, dan klik OK.
Parameter
Deskripsi
Retries
Berkorespondensi dengan bidang attempts yang dijelaskan sebelumnya. Dalam kebijakan retry default untuk permintaan HTTP, bidang ini dapat diatur ke 0, yang menunjukkan bahwa retry permintaan HTTP dinonaktifkan secara default.
Timeout
Berkorespondensi dengan bidang perTryTimeout yang dijelaskan sebelumnya.
Retry On
Berkorespondensi dengan bidang retryOn yang dijelaskan sebelumnya.
Polanya Bulkhead
Cara kerjanya
Pola bulkhead membatasi jumlah maksimum koneksi dan jumlah maksimum permintaan akses yang dapat dimulai oleh klien ke layanan untuk menghindari akses berlebihan ke layanan tersebut. Jika ambang batas tertentu terlampaui, permintaan baru akan diputus. Pola bulkhead membantu mengisolasi sumber daya yang digunakan dalam layanan dan mencegah kegagalan sistem berantai. Jumlah maksimum koneksi bersamaan dan periode timeout untuk setiap koneksi adalah pengaturan koneksi umum yang berlaku untuk TCP dan HTTP. Jumlah maksimum permintaan per koneksi dan jumlah maksimum percobaan ulang permintaan hanya berlaku untuk koneksi HTTP1.1, HTTP2, dan Google Remote Procedure Call (gRPC).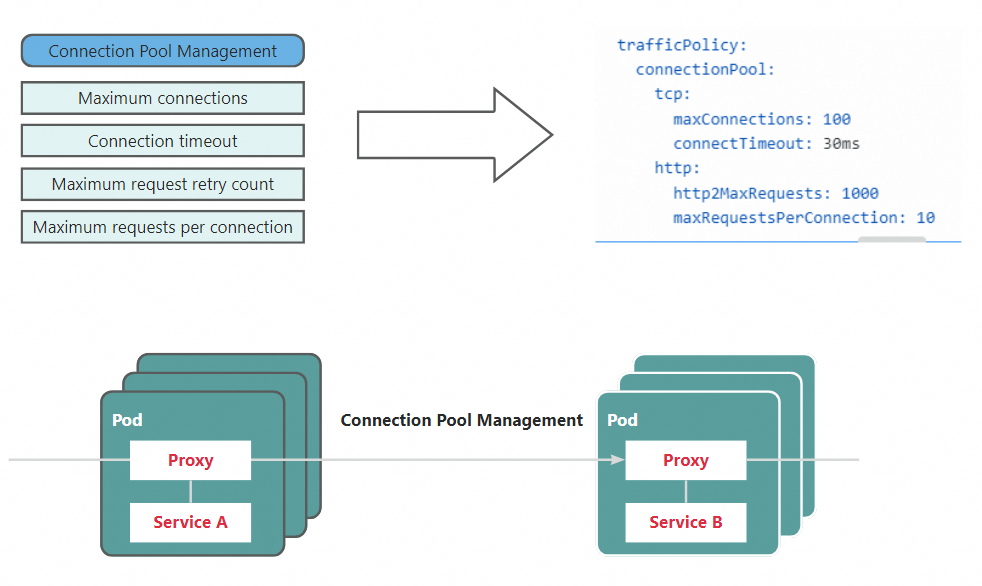
Solusi
ASM memungkinkan Anda membuat aturan tujuan untuk mengonfigurasi pola bulkhead. Dalam contoh ini, aturan tujuan dibuat untuk mendefinisikan pola bulkhead berikut: Ketika layanan meminta aplikasi httpbin, jumlah maksimum koneksi bersamaan adalah 1, jumlah maksimum permintaan per koneksi adalah 1, dan jumlah maksimum retry permintaan adalah 1. Selain itu, layanan menerima kesalahan 503 jika tidak ada koneksi ke aplikasi httpbin yang dibangun dalam 10 detik.
apiVersion: networking.istio.io/v1beta1
kind: DestinationRule
metadata:
name: httpbin
spec:
host: httpbin
trafficPolicy:
connectionPool:
http:
http1MaxPendingRequests: 1
maxRequestsPerConnection: 1
tcp:
connectTimeout: 10s
maxConnections: 1http1MaxPendingRequests: menentukan jumlah maksimum retry permintaan.
maxRequestsPerConnection: menentukan jumlah maksimum permintaan per koneksi.
connectTimeout: menentukan periode timeout untuk setiap koneksi.
maxConnections: menentukan jumlah maksimum koneksi bersamaan.
Pemutusan sirkuit
Cara kerjanya
Mekanisme pemutusan sirkuit bekerja sebagai berikut: Jika Service B tidak merespons permintaan dari Service A, Service A menghentikan pengiriman permintaan baru tetapi memeriksa jumlah kesalahan berturut-turut yang terjadi dalam periode waktu tertentu. Jika jumlah kesalahan berturut-turut melebihi ambang batas yang ditentukan, pemutus sirkuit memutus permintaan saat ini. Semua permintaan berikutnya gagal hingga pemutus sirkuit ditutup.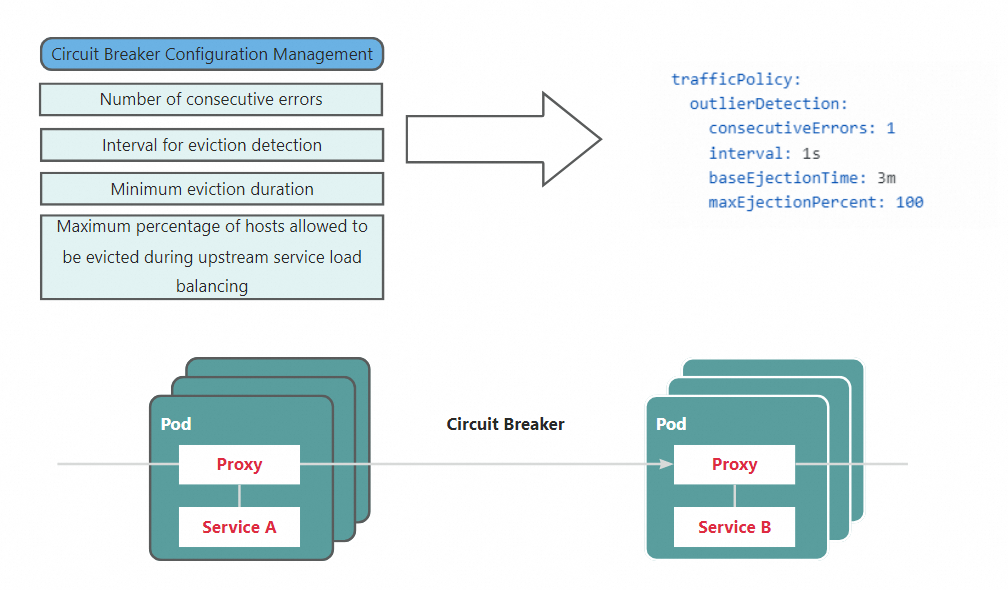
Solusi
ASM memungkinkan Anda membuat aturan tujuan untuk mengonfigurasi mekanisme pemutusan sirkuit tingkat host. Dalam contoh ini, aturan tujuan dibuat untuk mendefinisikan mekanisme pemutusan sirkuit berikut: Jika layanan gagal meminta aplikasi httpbin sebanyak tiga kali berturut-turut dalam 5 detik, permintaan dari layanan ini ke host yang sama dari aplikasi httpbin tidak diizinkan dalam 5 menit.
apiVersion: networking.istio.io/v1beta1
kind: DestinationRule
metadata:
name: httpbin
spec:
host: httpbin
trafficPolicy:
outlierDetection:
consecutiveErrors: 3
interval: 5s
baseEjectionTime: 5m
maxEjectionPercent: 100consecutiveErrors: menentukan jumlah kesalahan berturut-turut.
interval: menentukan interval waktu untuk deteksi ejection.
baseEjectionTime: menentukan durasi minimum ejection.
maxEjectionPercent: menentukan persentase maksimum host yang dapat dieject dari kolam load balancing.
Lihat metrik terkait pemutusan sirkuit tingkat host
Dalam skenario pemutusan sirkuit tingkat host, proxy sidecar klien mendeteksi tingkat kesalahan setiap host dari layanan upstream secara terpisah dan mengeject host dari kolam load balancing layanan jika host tersebut mengalami kesalahan berturut-turut. Mekanisme pemutusan sirkuit tingkat host ini berbeda dari mekanisme pemutusan sirkuit yang didefinisikan menggunakan bidang ASMCircuitBreaker.
Pemutusan sirkuit tingkat host dapat menghasilkan serangkaian metrik yang relevan. Ini membantu Anda menentukan apakah pemutusan sirkuit terjadi. Tabel berikut menjelaskan beberapa metrik yang relevan.
Metrik | Tipe | Deskripsi |
envoy_cluster_outlier_detection_ejections_active | Gauge | Jumlah host yang dieject |
envoy_cluster_outlier_detection_ejections_enforced_total | Counter | Jumlah kali terjadinya ejection host |
envoy_cluster_outlier_detection_ejections_overflow | Counter | Jumlah kali ejection host ditinggalkan karena persentase ejection maksimum tercapai |
ejections_detected_consecutive_5xx | Counter | Jumlah kesalahan 5xx berturut-turut yang terdeteksi pada host |
Anda dapat mengonfigurasi proxyStatsMatcher dari proxy sidecar untuk mengaktifkan proxy sidecar melaporkan metrik terkait pemutusan sirkuit. Setelah konfigurasi, Anda dapat menggunakan Prometheus untuk mengumpulkan dan melihat metrik terkait pemutusan sirkuit.
Anda dapat menggunakan proxyStatsMatcher untuk mengonfigurasi proxy sidecar melaporkan metrik terkait pemutusan sirkuit. Setelah Anda memilih proxyStatsMatcher, pilih Pencocokan Ekspresi Reguler dan atur nilainya menjadi
.*outlier_detection.*. Untuk informasi lebih lanjut, lihat bagian proxyStatsMatcher di Konfigurasikan proxy sidecar.Redeploy Deployment untuk aplikasi httpbin. Untuk informasi lebih lanjut, lihat bagian "(Opsional) Redeploy workload" di Konfigurasikan proxy sidecar.
Konfigurasikan pengumpulan metrik dan peringatan untuk pemutusan sirkuit tingkat host
Setelah Anda mengonfigurasi metrik terkait pemutusan sirkuit tingkat host, Anda dapat mengonfigurasi instance Prometheus untuk mengumpulkan metrik tersebut. Anda juga dapat mengonfigurasi aturan peringatan berdasarkan metrik kunci. Dengan cara ini, peringatan dihasilkan ketika pemutusan sirkuit terjadi. Bagian berikut menjelaskan cara mengonfigurasi pengumpulan metrik dan peringatan untuk pemutusan sirkuit tingkat host. Dalam contoh ini, Managed Service for Prometheus digunakan.
Dalam Managed Service for Prometheus, hubungkan kluster ACK pada bidang data ke komponen Alibaba Cloud ASM atau tingkatkan komponen Alibaba Cloud ASM ke versi terbaru. Ini memastikan bahwa metrik pemutusan sirkuit dapat dikumpulkan oleh Managed Service for Prometheus. Untuk informasi lebih lanjut tentang cara mengintegrasikan komponen ke ARMS, lihat Kelola komponen. (Jika Anda telah mengintegrasikan instance Prometheus yang dikelola sendiri untuk mengumpulkan metrik instance ASM dengan merujuk pada Pantau instance ASM menggunakan instance Prometheus yang dikelola sendiri, Anda tidak perlu melakukan langkah ini.)
Buat aturan peringatan untuk pemutusan sirkuit tingkat host. Untuk informasi lebih lanjut, lihat Gunakan pernyataan PromQL kustom untuk membuat aturan peringatan. Tabel berikut menjelaskan cara menentukan parameter kunci untuk mengonfigurasi aturan peringatan. Untuk informasi lebih lanjut tentang parameter lainnya, lihat dokumentasi sebelumnya.
Parameter
Contoh
Deskripsi
Pernyataan PromQL Kustom
(sum (envoy_cluster_outlier_detection_ejections_active) by (cluster_name, namespace)) > 0
Dalam contoh, metrik envoy_cluster_outlier_detection_ejections_active diquery untuk menentukan apakah host sedang dieject dalam kluster saat ini. Hasil query dikelompokkan berdasarkan namespace tempat layanan berada dan nama layanan.
Pesan Peringatan
Pemutusan sirkuit tingkat host dipicu. Beberapa workload mengalami kesalahan berulang kali dan host-host tersebut dieject dari kolam load balancing. Namespace: {$labels.namespace}}, Layanan tempat ejection host terjadi: {{$labels.cluster_name}}. Jumlah host yang dieject: {{ $value }}
Informasi peringatan dalam contoh menunjukkan namespace layanan yang memicu pemutusan sirkuit, nama layanan, dan jumlah host yang dieject.