Service Mesh (ASM) menyediakan algoritma penyeimbangan beban baru, puncak rata-rata bergerak dengan pembobotan eksponensial (peak EWMA), mulai versi 1.21. Algoritma ini menghitung rata-rata bergerak dari bobot statis, latensi, tingkat kesalahan, dan faktor lainnya untuk mendapatkan skor node, kemudian memilih node yang sesuai untuk penyeimbangan beban. Saat layanan backend perlu menangani trafik lonjakan, ASM dapat menggunakan algoritma peak EWMA untuk mempertimbangkan beban maksimum dan waktu respons real-time dari pod layanan backend, serta mendistribusikan trafik secara fleksibel ke pod yang sesuai guna menangani lonjakan trafik lebih baik. Topik ini menjelaskan cara mengonfigurasi dan menggunakan EWMA untuk menerapkan penyeimbangan beban berdasarkan latensi beban kerja.
Informasi latar belakang
ASM menyediakan berbagai algoritma penyeimbangan beban umum, termasuk round robin, permintaan paling sedikit, dan acak. Algoritma ini memenuhi persyaratan sebagian besar skenario bisnis dan menjamin kinerja tertentu. Namun, algoritma tersebut hanya memilih pod layanan backend berdasarkan aturan statis tanpa mempertimbangkan status dan kinerja real-time dari pod layanan backend.
Sebagai contoh, meskipun sumber daya pada host pod layanan backend digunakan oleh aplikasi lain, instance ASM yang menggunakan algoritma penyeimbangan beban default tetap memilih pod ini daripada pod lain yang idle. Akibatnya, layanan backend merespons permintaan dengan latensi lebih tinggi atau bahkan time out. Dalam kasus ini, jika algoritma penyeimbangan beban Anda dapat secara cerdas mengabaikan pod dengan kinerja yang menurun dan mengarahkan trafik ke pod lain yang idle, tingkat kesalahan keseluruhan dan latensi respons aplikasi dapat dikurangi secara signifikan.
Prasyarat
Instance ASM dengan versi 1.21 atau lebih baru telah dibuat. Untuk informasi lebih lanjut, lihat Buat Instance ASM.
Cluster Container Service for Kubernetes (ACK) telah ditambahkan ke instance ASM. Untuk informasi lebih lanjut, lihat Tambahkan Cluster ke Instance ASM dan Perbarui Instance ASM.
Klien kubectl terhubung ke cluster. Untuk informasi lebih lanjut, lihat Dapatkan File kubeconfig Cluster dan Gunakan kubectl untuk Terhubung ke Cluster.
Gunakan peak EWMA
Masuk ke Konsol ASM. Di panel navigasi di sebelah kiri, pilih .
Di halaman Mesh Management, klik nama instance ASM. Di panel navigasi di sebelah kiri, pilih . Di halaman yang muncul, klik Create from YAML.
Isi kode sampel berikut dan klik Create. Kode YAML sampel berikut menentukan algoritma penyeimbangan beban
PEAK_EWMAuntuk layanan simple-server di namespace default.apiVersion: networking.istio.io/v1beta1 kind: DestinationRule metadata: name: simple-server namespace: default spec: host: simple-server.default.svc.cluster.local trafficPolicy: loadBalancer: simple: PEAK_EWMA # Menggunakan algoritma penyeimbangan beban PEAK_EWMA dari ASM.
Contoh
Deskripsi
Dalam contoh ini, aplikasi simple-server adalah server. Aplikasi sleep berfungsi sebagai klien untuk mengirim trafik uji dan layanan simple-server.default.svc.cluster.local berdasarkan aplikasi simple-server berfungsi sebagai server. Layanan ini memiliki dua deployment dengan konfigurasi berbeda:
simple-server-normal: Latensi respons deployment ini berkisar antara 50 ms hingga 100 ms.
simple-server-high-latency: Latensi respons deployment ini berkisar antara 500 ms hingga 2000 ms. Deployment ini digunakan untuk mensimulasikan peningkatan latensi beberapa beban kerja layanan.
Langkah 1: Aktifkan pemantauan metrik untuk instance ASM
Untuk menunjukkan manfaat algoritma penyeimbangan beban peak EWMA secara visual, kami mengaktifkan pemantauan metrik untuk instance ASM dalam contoh ini untuk mengamati perubahan latensi respons keseluruhan layanan sebelum dan sesudah algoritma penyeimbangan beban peak EWMA diaktifkan. Untuk informasi lebih lanjut tentang cara mengaktifkan pemantauan metrik dan mengumpulkan metrik ke Application Real-Time Monitoring Service (ARMS), lihat Kumpulkan Metrik ke Managed Service for Prometheus.
Langkah 2: Terapkan lingkungan yang diperlukan
Gunakan kubectl untuk terhubung ke cluster ACK berdasarkan informasi dalam file kubeconfig, dan buat file sleep.yaml yang berisi konten berikut:
Jalankan perintah berikut untuk menerapkan aplikasi sleep:
kubectl apply -f sleep.yamlBuat file simple.yaml yang berisi konten berikut:
Jalankan perintah berikut untuk menerapkan aplikasi simple-server-normal dan simple-server-high-latency:
kubectl apply -f simple.yaml
Langkah 3: Mulai pengujian dengan algoritma penyeimbangan beban default
Algoritma penyeimbangan beban default LEAST_REQUEST digunakan dalam pengujian ini untuk menghasilkan data dasar.
Jalankan perintah berikut untuk memulai pengujian. 100 permintaan dikirim untuk mengunjungi path
/hellodari layanan simple-server:kubectl exec -it deploy/sleep -c sleep -- sh -c 'for i in $(seq 1 100); do time curl simple-server:8080/hello; echo "request $i done"; done'Output yang Diharapkan:
hello this is port: 8080real 0m 0.06s user 0m 0.00s sys 0m 0.00s request 1 done hello this is port: 8080real 0m 0.09s user 0m 0.00s sys 0m 0.00s request 2 done ...... hello this is port: 8080real 0m 1.72s user 0m 0.00s sys 0m 0.00s request 100 doneSetelah perintah dijalankan, klik nama instance ASM yang diinginkan di halaman Mesh Management. Di panel navigasi di sebelah kiri, pilih . Klik tab Cloud ASM Istio Service dan konfigurasikan kondisi filter berikut:
Namespace:
defaultService:
simple-server.default.svc.cluster.localReporter:
destinationClient Workload Namespace:
defaultClient Workload:
sleepService Workload Namespace:
defaultService Workload:
simple-server-normal + simple-server-high-latency
Klik Client Workloads untuk melihat bagian Incoming Request Duration By Source.
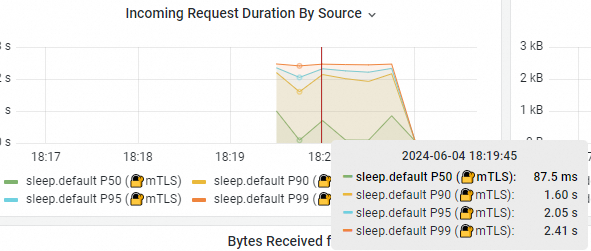
Ini menunjukkan bahwa latensi respons P50 dari permintaan dari aplikasi sleep ke layanan
simple-serveradalah 87,5 ms, dan latensi respons P95 meningkat secara signifikan menjadi 2,05 detik. Hal ini karena latensi respons aplikasisimple-server-high-latencylebih tinggi, yang meningkatkan waktu respons keseluruhan layanan simple-server.PentingHasil pengujian sebelumnya adalah nilai teoretis yang diperoleh dalam lingkungan eksperimental terkontrol. Hasil aktual mungkin bervariasi tergantung pada lingkungan bisnis Anda.
Langkah 4: Konfigurasikan algoritma penyeimbangan beban peak EWMA dan lakukan pengujian lagi
Buat aturan tujuan untuk mengonfigurasi algoritma penyeimbangan beban peak EWMA untuk layanan simple-server.
Gunakan konten YAML berikut untuk membuat aturan tujuan dengan mengacu pada langkah-langkah di Gunakan Peak EWMA:
apiVersion: networking.istio.io/v1beta1 kind: DestinationRule metadata: name: simple-server namespace: default spec: host: simple-server.default.svc.cluster.local trafficPolicy: loadBalancer: simple: PEAK_EWMAGunakan kubectl untuk terhubung ke cluster ACK berdasarkan informasi dalam file kubeconfig, dan jalankan perintah berikut untuk memulai pengujian lagi:
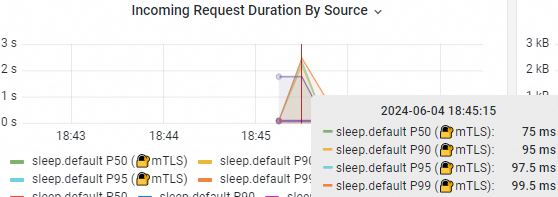
kubectl exec -it deploy/sleep -c sleep -- sh -c 'for i in $(seq 1 100); do time curl simple-server:8080/hello; echo "request $i done"; done'Amati hasil pengujian dengan mengacu pada Langkah 3. Hasilnya menunjukkan bahwa latensi P90, P95, dan P99 berkurang secara signifikan. Hal ini karena algoritma penyeimbangan beban peak EWMA menemukan bahwa latensi beban kerja simple-server-high-latency tinggi dan mengurangi bobot penyeimbangan bebannya. Akibatnya, lebih banyak permintaan diarahkan ke simple-server-normal dengan latensi lebih rendah. Dari sudut pandang layanan simple-server, latensi keseluruhan permintaan berkurang secara signifikan.