Saat Anda mengonfigurasi service level objectives (SLO) untuk sebuah aplikasi di Service Mesh (ASM), sebuah aturan Prometheus akan dihasilkan secara otomatis. Aturan ini mendefinisikan recording rules untuk metrik SLO dan alerting rules untuk laju penggunaan error budget. Untuk mengaktifkan SLO tersebut, impor aturan yang dihasilkan ke dalam sistem Prometheus Anda.
Prosedur berikut mencakup cara mengimpor aturan tersebut ke instans Prometheus yang dikelola oleh Prometheus Operator serta memverifikasi bahwa metrik dan peringatan SLO berfungsi dengan benar.
Prasyarat
Sebelum memulai, pastikan Anda telah:
Mengaktifkan pemantauan Prometheus untuk kluster Container Service for Kubernetes (ACK). Untuk detailnya, lihat Gunakan Prometheus open source untuk memantau kluster ACK dan Pantau instans ASM menggunakan instans Prometheus yang dikelola sendiri.
Cara Prometheus Operator memilih aturan
Prometheus Operator menggunakan custom resource definitions (CRDs) untuk mengelola konfigurasi Prometheus. Untuk menambahkan recording rules dan alerting rules, buat custom resource (CR) PrometheusRule. Prometheus Operator menentukan objek PrometheusRule mana yang akan dimuat berdasarkan bidang ruleSelector dalam CR Prometheus:
Jika
ruleSelectormenentukanmatchLabels, makaPrometheusRuleharus memiliki label yang sama.Jika
ruleSelectordikosongkan, label bersifat opsional.
Jika penerapan Prometheus Anda tidak menggunakan Prometheus Operator, impor aturan yang dihasilkan menggunakan metode yang sesuai dengan konfigurasi Anda. Lihat dokumentasi Prometheus untuk panduan lebih lanjut.
Langkah 1: Dapatkan label ruleSelector
Periksa bidang ruleSelector dalam CR Prometheus untuk menentukan label apa yang dibutuhkan oleh Prometheus Operator pada objek PrometheusRule.
Masuk ke Konsol ACK. Di panel navigasi sebelah kiri, klik Clusters.
Pada halaman Clusters, klik nama kluster yang ingin Anda kelola, lalu pilih Workloads > Custom Resources di panel navigasi sebelah kiri.
Pada tab CRDs, klik PrometheusRule.
Pada tab Resource Objects, pilih monitoring dari daftar drop-down Namespace. Temukan ack-prometheus-operator-prometheus dan klik Edit YAML di kolom Actions.
Temukan bidang
ruleSelector. Konfigurasi khas terlihat seperti berikut: Pada contoh ini, setiapPrometheusRuleharus menyertakan kedua label (app: ack-prometheus-operatordanrelease: ack-prometheus-operator) agar dipilih.ruleSelector: matchLabels: app: ack-prometheus-operator release: ack-prometheus-operator
Langkah 2: Terapkan PrometheusRule
Buat file bernama
prometheusrule.yamldengan konten berikut:Atur bidang
labelsagar sesuai dengan nilaimatchLabelsdari Langkah 1.Ganti konten
specdengan aturan Prometheus yang dihasilkan dari Konsol ASM.
apiVersion: monitoring.coreos.com/v1 kind: PrometheusRule metadata: labels: app: ack-prometheus-operator release: ack-prometheus-operator name: asm-rules namespace: monitoring spec: # Ganti dengan aturan Prometheus yang dihasilkan.Terapkan
PrometheusRuleke kluster ACK:kubectl apply -f prometheusrule.yaml
Langkah 3: Verifikasi bahwa aturan telah dimuat
Setelah PrometheusRule diterapkan, pengontrol Prometheus Operator secara otomatis menulis konfigurasi aturan ke dalam ConfigMap Prometheus. Verifikasi hal ini melalui Konsol ACK atau command line.
Opsi A: Konsol ACK
Masuk ke Konsol ACK. Di panel navigasi sebelah kiri, klik Clusters.
Pada halaman Clusters, klik nama kluster yang ingin Anda kelola, lalu pilih Configurations > ConfigMap di panel navigasi sebelah kiri.
Pada halaman ConfigMap, pilih monitoring dari daftar drop-down Namespace, temukan ConfigMap Prometheus, lalu klik Edit YAML di kolom Actions.
Konfirmasi bahwa aturan SLO ASM muncul dalam ConfigMap. Gambar berikut menunjukkan impor yang berhasil.

Opsi B: Command line
Jalankan perintah berikut untuk menampilkan daftar resource PrometheusRule:
kubectl get prometheusrules -n monitoringOutput harus menyertakan PrometheusRule asm-rules.
Langkah 4: Verifikasi bahwa SLO aktif
Periksa recording rules dan alerting rules
Alihkan port lokal 9090 ke layanan Prometheus:
kubectl --namespace monitoring port-forward svc/ack-prometheus-operator-prometheus 9090Buka http://localhost:9090 di browser untuk mengakses Konsol Prometheus.
Pada halaman Prometheus, masukkan
asm_slo_infoke dalam kotak kueri dan klik Execute. Jika kueri mengembalikan hasil, berarti recording rules aktif.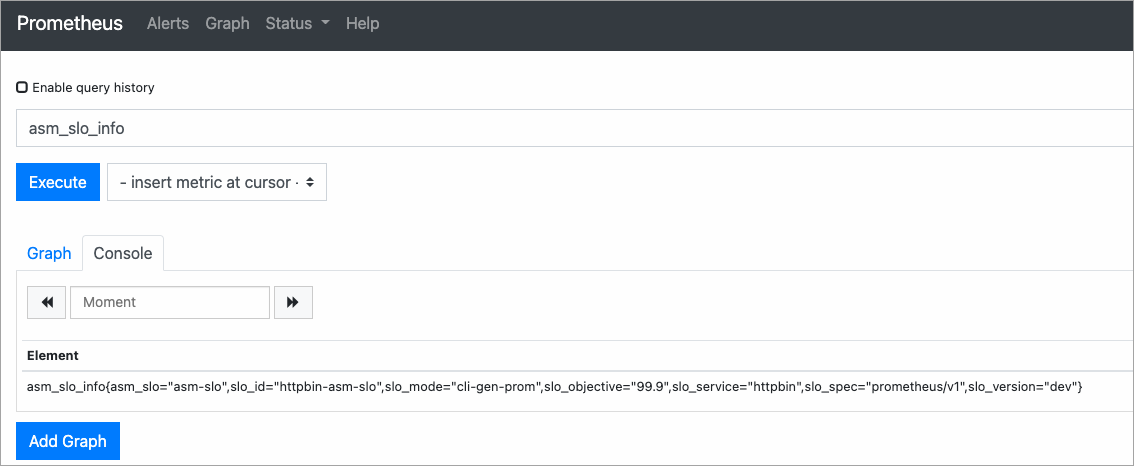
Di bilah navigasi atas, klik Alerts untuk memverifikasi bahwa alerting rules telah dimuat.

Simulasikan traffic untuk memvalidasi metrik SLO
Gunakan skenario berikut untuk memastikan metrik dan peringatan merespons dengan benar.
Skenario 1: Traffic normal (tingkat keberhasilan 99,5%)
Skrip ini mengirimkan 200 permintaan, dengan hanya satu yang mengembalikan error 500, sehingga mensimulasikan tingkat keberhasilan 99,5%:
#!/bin/bash
for i in $(seq 200)
do
if (( $i == 100 ))
then
curl -I http://<ingress-gateway-ip>/status/500;
else
curl -I http://<ingress-gateway-ip>/;
fi
echo "OK"
sleep 0.01;
done;Ganti <ingress-gateway-ip> dengan alamat IP gerbang masuk. Untuk detailnya, lihat Deploy an ingress gateway service.
Setelah skrip selesai dijalankan, kueri slo:period_error_budget_remaining:ratio di Konsol Prometheus untuk memeriksa sisa error budget. Nilai yang mendekati 1 menunjukkan sebagian besar budget masih tersedia.
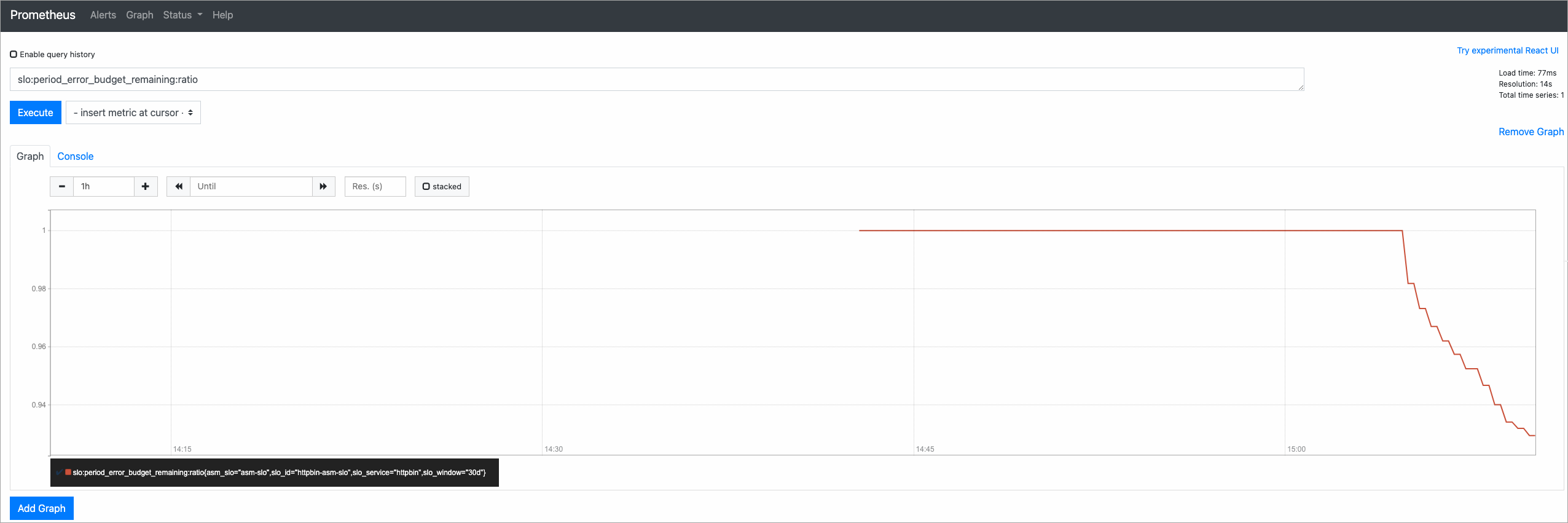
Skenario 2: Traffic error (tingkat kegagalan 50%)
Skrip ini mengirimkan permintaan sukses dan gagal secara bergantian untuk mensimulasikan tingkat error 50% dan memicu peringatan burn rate:
#!/bin/bash
for i in $(seq 200)
do
curl -I http://<ingress-gateway-ip>/
curl -I http://<ingress-gateway-ip>/status/500;
echo "OK"
sleep 0.01;
done;Setelah skrip selesai dijalankan, buka halaman Alerts di Konsol Prometheus. Jika burn rate melebihi ambang batas, peringatan akan muncul.
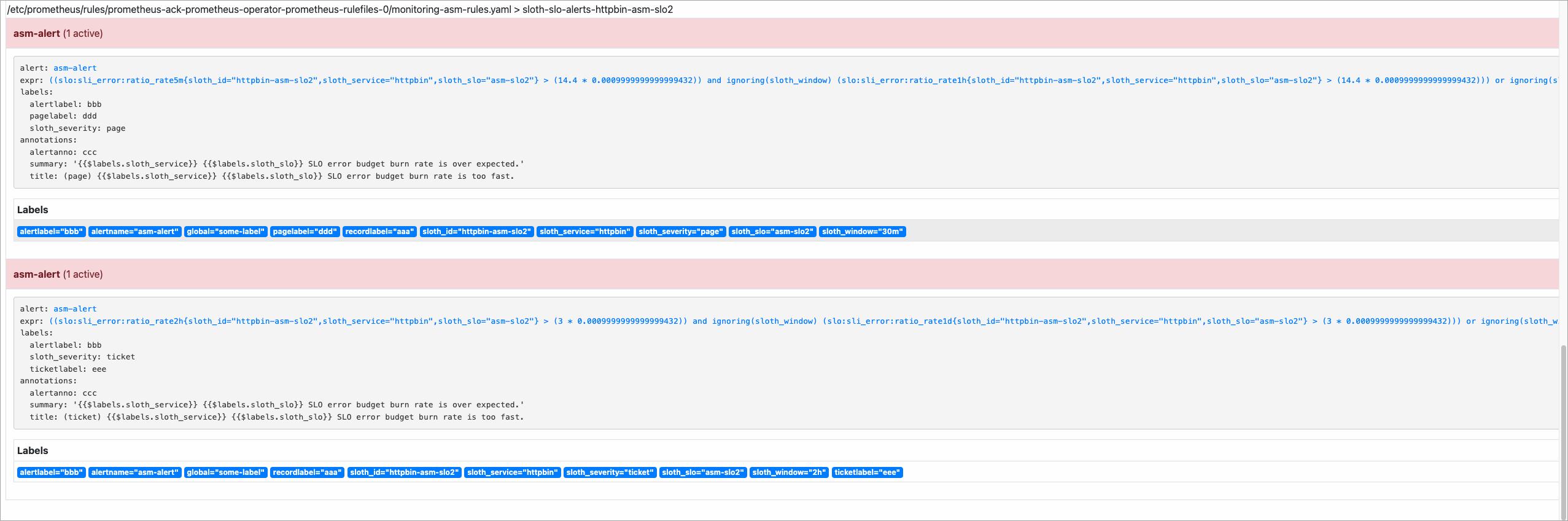
Referensi metrik SLO
Tabel berikut menjelaskan metrik SLO yang digunakan untuk pemantauan. Untuk penjelasan lengkap mengenai konsep SLO seperti error budget dan multi-window burn rate alerting, lihat Ikhtisar SLO.
| Metric | Description | Interpretation |
|---|---|---|
slo:period_error_budget_remaining:ratio | Sisa error budget sebagai rasio selama periode kepatuhan 30 hari. | 1 = budget penuh tersedia. 0 = budget habis. Nilai antara 0 dan 1 menunjukkan konsumsi sebagian. |
slo:sli_error:ratio_rate30d | Tingkat error rata-rata selama periode kepatuhan 30 hari. | Nilai yang lebih rendah menunjukkan keandalan layanan yang lebih baik. |
slo:period_burn_rate:ratio | Laju konsumsi error budget selama periode kepatuhan 30 hari. | 1 = budget dikonsumsi persis pada laju yang diharapkan. Nilai di atas 1 menunjukkan konsumsi lebih cepat daripada yang berkelanjutan. |
slo:current_burn_rate:ratio | Burn rate saat ini berdasarkan jendela waktu yang lebih pendek. | Nilai di atas 1 menunjukkan budget dikonsumsi lebih cepat daripada yang berkelanjutan dan dapat memicu peringatan. |
Lihat peringatan di Alertmanager
Alertmanager mengumpulkan peringatan dari Prometheus dan mengarahkannya ke penerima yang dikonfigurasi seperti endpoint email atau webhook.
Alihkan port lokal 9093 ke layanan Alertmanager:
kubectl --namespace monitoring port-forward svc/ack-prometheus-operator-alertmanager 9093Buka http://localhost:9093 di browser untuk mengakses Konsol Alertmanager.
Pada halaman Alertmanager, klik ikon
 untuk memperluas dan melihat detail peringatan.
untuk memperluas dan melihat detail peringatan.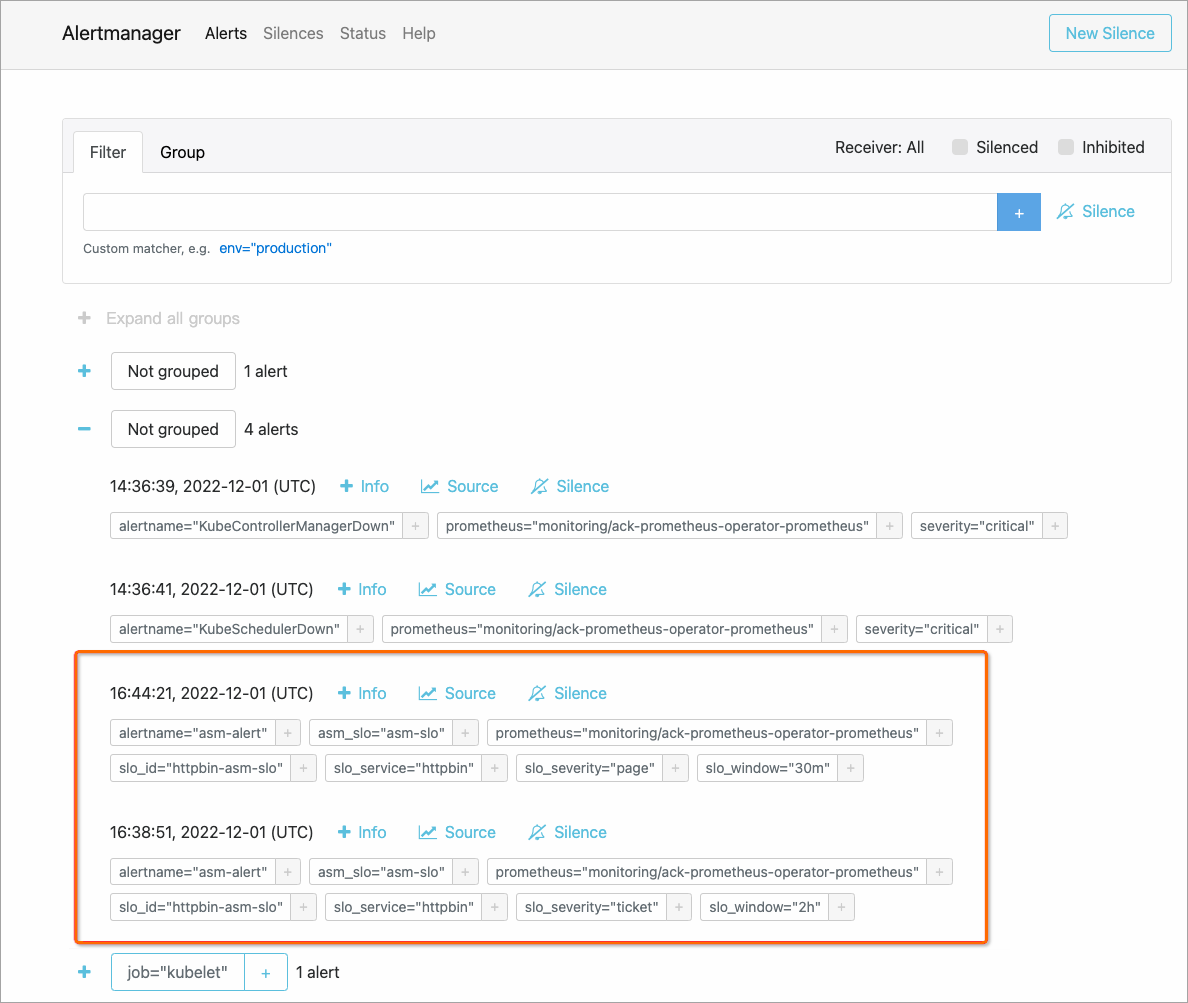
Langkah selanjutnya
Konfigurasikan SLO untuk aplikasi di ASM untuk menambah atau mengubah target SLO.
Ikhtisar SLO untuk penjelasan lengkap mengenai konsep SLO, metrik, dan multi-window burn rate alerting.