Managed Service for Prometheus menyediakan layanan terkelola Prometheus dan layanan pemantauan kontainer. Layanan pemantauan kontainer dikenai biaya yang mencakup biaya skala kluster pemantauan dan biaya instans Prometheus. Layanan ini tersedia dalam dua versi: Dasar dan Pro. Topik ini menjelaskan operasi, rincian penagihan, fitur, dasbor yang didukung, serta aturan peringatan default dari versi Pro pemantauan kontainer.
Jenis kluster yang mendukung Edisi Pro
ACK managed Pro cluster
ACK Lingjun cluster
Cluster khusus ACK
Prasyarat
Versi Pro pemantauan kontainer memerlukan Managed Service for Prometheus. Anda harus terlebih dahulu mengaktifkan Managed Service for Prometheus (bayar sesuai penggunaan berdasarkan volume tulis tautan aktivasi, bayar sesuai penggunaan berdasarkan volume pelaporan tautan aktivasi), lalu mengaktifkan versi Pro pemantauan kontainer.
Rincian penagihan versi Pro pemantauan kontainer
Item penagihan | Deskripsi penagihan | Metode penagihan | Siklus penagihan |
Biaya skala kluster pemantauan | Penggunaan OCU dihitung berdasarkan skala node kluster kontainer, dengan setiap 10 node kluster dikonversi menjadi 1 OCU. Catatan OCU: Observability Capacity Unit adalah unit penagihan baru yang diperkenalkan oleh Alibaba Cloud Native Observability. Unit ini secara otomatis menghitung penggunaan OCU berdasarkan penggunaan sumber daya per jam. Harga OCU adalah 0,023 USD/unit. | Bayar sesuai penggunaan: Biaya harian skala kluster kontainer = Jumlah total unit OCU per jam × harga unit OCU Catatan Unit OCU per jam = Jumlah maksimum node dalam siklus penagihan saat ini dibagi 10, dibulatkan ke atas | Siklus penagihan adalah per jam. Managed Service for Prometheus menghitung jumlah maksimum node kluster untuk setiap jam pada hari sebelumnya setelah pukul 00.00, kemudian menghitung unit OCU per jam sesuai aturan penagihan, mengakumulasi unit OCU per jam untuk menghitung total jumlah OCU pada hari sebelumnya, mengalikannya dengan harga unit OCU, dan menghasilkan biaya pemantauan skala kluster kontainer secara harian. |
Biaya instans Prometheus | Untuk informasi selengkapnya, lihat Penagihan instans Prometheus. | ||
Cara menggunakan versi Pro pemantauan kontainer
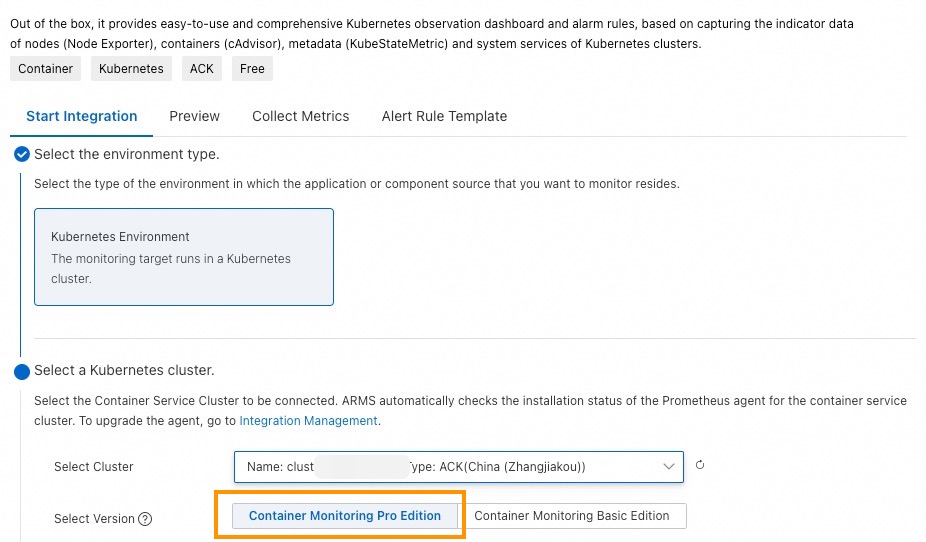
Metode 1: Pilih versi Pro pemantauan kontainer saat integrasi
Pada halaman Integration Center, pilih Container Cluster Monitoring.
Pada panel Container Cluster Monitoring, pilih kluster layanan kontainer yang akan diintegrasikan, lalu pilih Container Monitoring Pro Version sebagai versi, dan klik OK.
Metode 2: Tingkatkan dari versi dasar ke versi Pro pemantauan kontainer
Setelah ditingkatkan ke versi Pro pemantauan kontainer, Anda tidak dapat menurunkan spesifikasi kembali ke versi dasar.
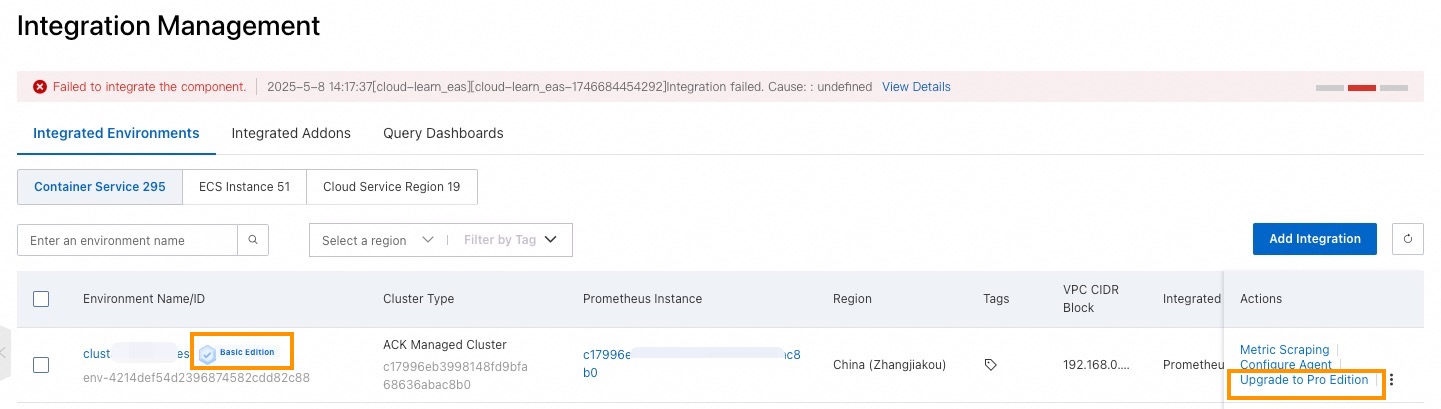
Pada halaman Provisioning, pilih Integrated Environments > Container Environment.
Klik Upgrade pada kolom Operation untuk pemantauan kontainer yang akan ditingkatkan. Pada kotak dialog, klik Confirm.
Perbedaan antara versi dasar dan versi Pro
Kategori | Versi dasar | Versi Pro |
7 hari | 90 hari | |
Pengumpul Prometheus | Agen yang diterapkan di kluster pengguna (replika tunggal default menggunakan sumber daya kluster sebesar 3 core, 4 GB), memerlukan pengelolaan mandiri. | Menyediakan Agen pengumpulan terkelola, pengguna tidak lagi menanggung biaya sumber daya Agen, menyediakan SLA tingkat produksi sebesar 99,95%. |
Dasbor pemantauan | Dasbor pemantauan dasar bawaan. | Dasbor pemantauan komprehensif bawaan. |
Dasbor yang didukung oleh versi Pro pemantauan kontainer
Tipe | Nama Dasbor |
Ikhtisar pemantauan | Ikhtisar pemantauan kluster |
Dasbor namespace kluster | |
Komponen inti kluster | ACK Pro API server |
ACK Pro ETCD | |
ACK Pro Scheduler | |
ACK Pro Cloud Controller Manager | |
ACK Pro Kube Controller Manager | |
Pemantauan node | Ikhtisar pool node |
Detail pemantauan node kluster | |
Pemantauan aplikasi | Pemantauan aplikasi tanpa status |
Pemantauan aplikasi berstatus | |
Pemantauan aplikasi set proses daemon | |
Pemantauan Pod kluster | |
Pemantauan jaringan | Pemantauan komponen CoreDNS |
Pemantauan lalu lintas Ingress kluster | |
Pemantauan penyimpanan | Pemantauan komponen penyimpanan CSI – dimensi kluster |
Pemantauan komponen penyimpanan CSI – dimensi node | |
Pemantauan IO Pod (Level Pod) | |
Pemantauan IO Penyimpanan Frontend (Level Kluster) | |
Pemantauan GPU | Pemantauan GPU kluster – dimensi kluster |
Pemantauan GPU kluster – dimensi node | |
Pemantauan GPU kluster – dimensi Pod aplikasi | |
Analisis biaya/optimasi sumber daya | Profil sumber daya |
Lainnya | Pemantauan IO Penyimpanan Backend (Level Kluster) |
k8s-reclaimed-resource | |
Pemantauan mandiri Prometheus kluster | |
Ikhtisar Virtual Node(ECI) |
Aturan peringatan default
Nama/ID aturan peringatan | Kelompok peringatan | Template |
Penggunaan CPU node lebih besar dari 75% | Node | Node {{ $labels.instance }} penggunaan CPU lebih besar dari 75%, penggunaan CPU saat ini {{ printf "%.2f" $value }}% |
Penggunaan CPU node lebih besar dari 85% | Node | Node {{ $labels.instance }} penggunaan CPU lebih besar dari 85%, penggunaan CPU saat ini {{ printf "%.2f" $value }}% |
Penggunaan memori node lebih besar dari 75% | Node | Node {{ $labels.instance }} penggunaan memori lebih besar dari 75%, penggunaan memori saat ini {{ printf "%.2f" $value }}% |
Penggunaan memori node lebih besar dari 85% | Node | Node {{ $labels.instance }} penggunaan memori lebih besar dari 85%, penggunaan memori saat ini {{ printf "%.2f" $value }}% |
Anomali node | Node | Node {{$labels.node}} telah berada dalam status tidak tersedia selama lebih dari 10 menit |
Penggunaan disk lebih besar dari 95% | Node | Node {{ $labels.instance }} disk {{ $labels.device }} penggunaan melebihi 95%, penggunaan disk saat ini {{ printf "%.2f" $value }}% |
Ketersediaan Pod Deployment kurang dari 50% | Beban kerja | Namespace: {{$labels.namespace}} / Deployment: {{$labels.deployment}} ketersediaan Pod kurang dari 50%, jumlah Pod tidak tersedia saat ini {{ $value }} |
Eksekusi Job gagal | Beban kerja | Namespace: {{$labels.namespace}}/Job: {{$labels.job_name}} eksekusi gagal |
Pod gagal memulai karena waktu habis | Beban kerja | Namespace: {{$labels.namespace}}/Pod: {{$labels.pod_name}} belum berhasil dimulai selama lebih dari 15 menit, alasan menunggu {{$labels.reason}} |
Status Pod tidak normal | Beban kerja | Namespace: {{$labels.namespace}}/Pod: {{$labels.pod_name}} telah berada dalam status {{$labels.phase}} selama lebih dari 10 menit |
Pod sering restart | Beban kerja | Namespace: {{$labels.namespace}}/Pod: {{$labels.pod_name}} telah melakukan restart lebih dari {{ $labels.metrics_params_value}} kali dalam {{$labels.metrics_params_time}} menit, jumlah restart saat ini {{ $value }} |
Penggunaan CPU kontainer melebihi 85% | Beban kerja | Namespace: {{$labels.namespace}} / Pod: {{$labels.pod_name}} / Kontainer: {{$labels.container}} penggunaan CPU lebih besar dari 85%, nilai saat ini {{ printf "%.2f" $value }}% |
Penggunaan CPU kontainer melebihi 75% | Beban kerja | Namespace: {{$labels.namespace}} / Pod: {{$labels.pod_name}} / Kontainer: {{$labels.container}} penggunaan CPU lebih besar dari 75%, nilai saat ini {{ printf "%.2f" $value }}% |
Penggunaan memori kontainer melebihi 75% | Beban kerja | Namespace: {{$labels.namespace}} / Pod: {{$labels.pod_name}} / Kontainer: {{$labels.container}} penggunaan memori lebih besar dari 75%, nilai saat ini {{ printf "%.2f" $value }}% |
Penggunaan memori kontainer melebihi 85% | Beban kerja | Namespace: {{$labels.namespace}} / Pod: {{$labels.pod_name}} / Kontainer: {{$labels.container}} penggunaan memori lebih besar dari 85%, nilai saat ini {{ printf "%.2f" $value }}% |