Setelah menginstal probe ARMS pada aplikasi Java Anda, ARMS akan memantaunya secara otomatis. Anda dapat melihat metrik infrastruktur monitoring, garbage collection (GC), dan memori JVM pada halaman Instance Monitoring.
Prasyarat
Agen ARMS telah diinstal untuk aplikasi tersebut.
Pemantauan Aplikasi menyediakan halaman detail aplikasi baru bagi pengguna yang telah mengaktifkan mode penagihan baru.
Jika Anda belum mengaktifkan mode penagihan baru, klik Switch to New Version pada halaman Application List untuk melihat halaman detail aplikasi baru.
Lihat Pemantauan Instans
-
Masuk ke Konsol ARMS. Di panel navigasi kiri, pilih .
Di bilah navigasi atas, klik Instance Monitoring.
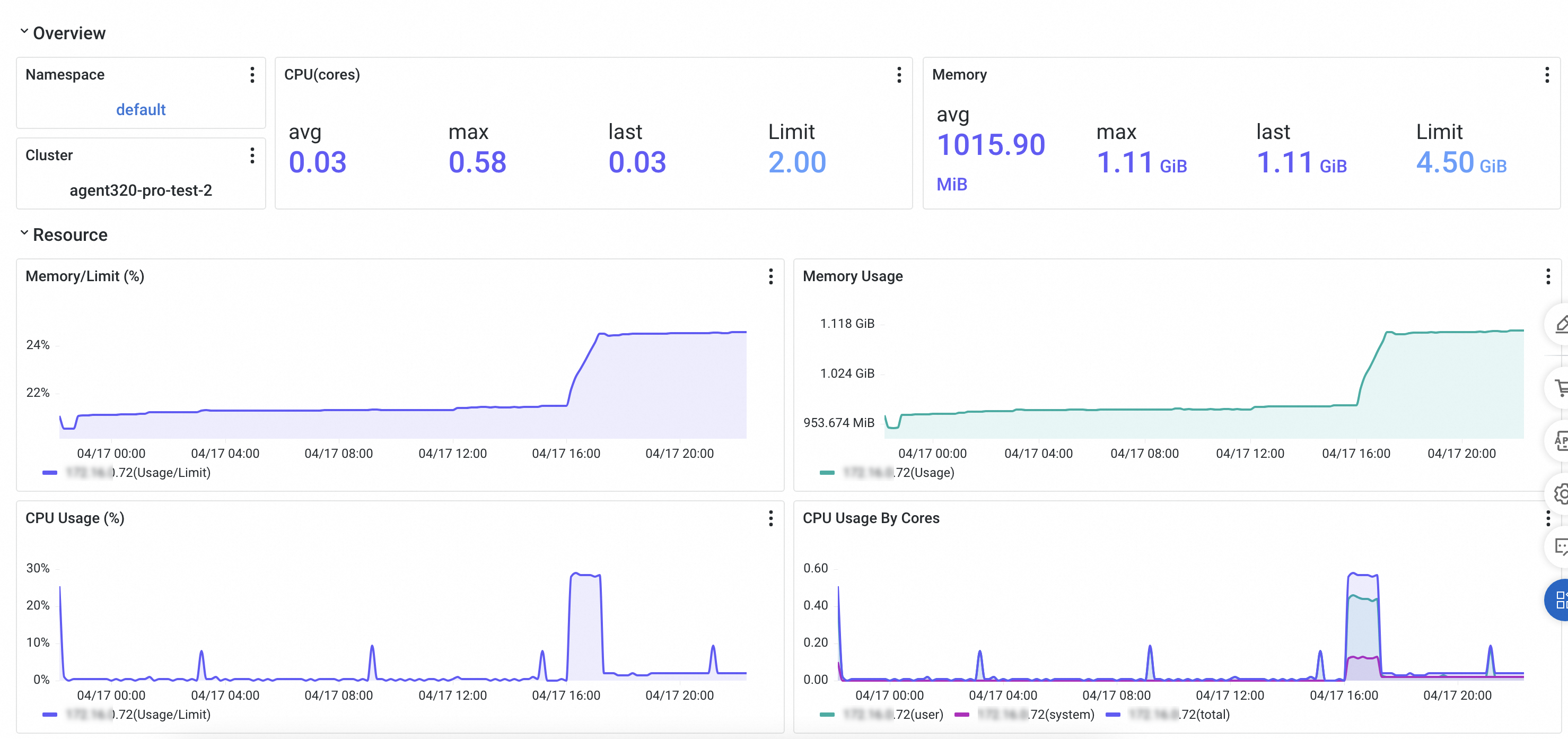
Ikhtisar Halaman
Dasbor halaman Instance Monitoring menyesuaikan tampilannya berdasarkan metode integrasi aplikasi Anda, dengan tampilan berbeda untuk lingkungan ECS dan kontainer.
Jika aplikasi Anda berjalan di lingkungan kontainer dan terintegrasi dengan Managed Service for Prometheus, halaman ini menampilkan metrik kontainer terutama dari Managed Service for Prometheus. Untuk mengintegrasikan lingkungan kontainer Anda dengan Managed Service for Prometheus, lihat Container Observability.
Jika lingkungan kontainer Anda tidak terintegrasi dengan Managed Service for Prometheus, pastikan versi probe Pemantauan Aplikasi Anda adalah 4.1.0 atau lebih baru agar metrik kontainer dasar dapat ditampilkan. Untuk informasi selengkapnya tentang versi probe, lihat Panduan Versi Probe (Java Agent).
Lingkungan ECS
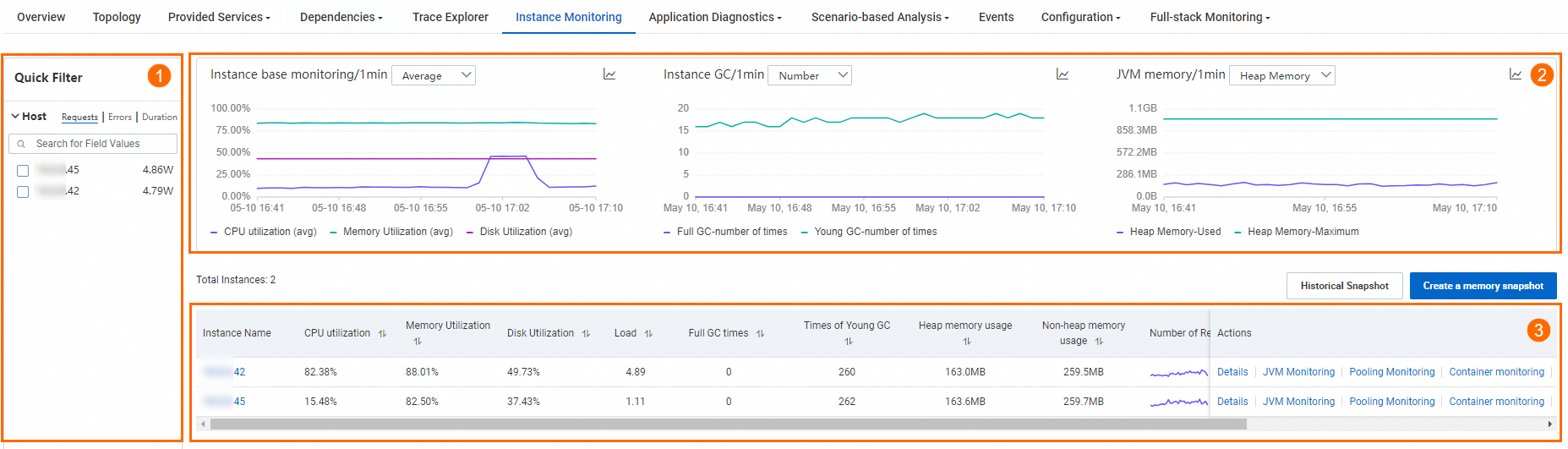
Di area filter cepat (①), Anda dapat memfilter grafik dan daftar instans berdasarkan alamat host.
Di area grafik tren (②), Anda dapat melihat kurva deret waktu untuk metrik infrastruktur monitoring, GC, dan memori JVM.
Infrastruktur monitoring: Menampilkan tren penggunaan CPU, memori, dan disk dalam rentang waktu tertentu. Anda dapat menggunakan daftar drop-down di samping judul setiap grafik untuk beralih antara nilai rata-rata dan maksimum.
Instance GC: Menampilkan tren Full GC dan Young GC dalam rentang waktu tertentu. Anda dapat menggunakan daftar drop-down di samping judul setiap grafik untuk beralih antara jumlah GC dan durasi rata-rata GC.
Memori JVM: Menampilkan tren memori heap yang digunakan dan memori heap maksimum dalam rentang waktu tertentu. Anda dapat menggunakan daftar drop-down di samping judul setiap grafik untuk beralih ke tren memori non-heap yang digunakan dan memori non-heap maksimum.
CatatanPemantauan Aplikasi ARMS mengumpulkan metrik JVM melalui JMX. Wilayah memori non-heap yang dilaporkan oleh ARMS lebih sedikit dibandingkan proses Java aktual. Akibatnya, jumlah total memori heap dan non-heap yang ditampilkan di ARMS mungkin berbeda dari ukuran RES yang ditunjukkan oleh perintah
top. Untuk informasi selengkapnya, lihat Detail Memori Pemantauan JVM.
Anda dapat mengklik ikon
 untuk membuka kotak dialog tempat Anda dapat melihat statistik suatu metrik dalam rentang waktu tertentu atau membandingkan statistik pada tanggal berbeda untuk rentang waktu yang sama. Anda juga dapat mengklik ikon
untuk membuka kotak dialog tempat Anda dapat melihat statistik suatu metrik dalam rentang waktu tertentu atau membandingkan statistik pada tanggal berbeda untuk rentang waktu yang sama. Anda juga dapat mengklik ikon  untuk beralih antara grafik kolom dan grafik tren.
untuk beralih antara grafik kolom dan grafik tren.Di area daftar instans (③), Anda dapat melihat IP instans, utilisasi CPU, utilisasi memori, utilisasi disk, beban, jumlah Full GC, jumlah Young GC, penggunaan memori heap, penggunaan memori non-heap, dan metrik RED (permintaan, error, dan waktu respons rata-rata).
Di daftar instans, Anda dapat melakukan aksi berikut:
Klik IP instans untuk melihat detail instans. Untuk informasi selengkapnya, lihat Detail Instans.
Di kolom Actions, klik Trace untuk melihat detail jejak instans. Untuk informasi selengkapnya, lihat Analisis Jejak.
Lingkungan Kontainer (Prometheus)
Di area filter cepat (①), Anda dapat memfilter grafik dan daftar instans berdasarkan kluster dan alamat host.
Di area grafik tren (②), Anda dapat melihat kurva deret waktu untuk metrik infrastruktur monitoring, GC, dan memori JVM.
Infrastruktur monitoring: Menampilkan tren penggunaan CPU dan memori dalam rentang waktu tertentu.
Instance GC: Menampilkan tren Full GC dan Young GC dalam rentang waktu tertentu. Anda dapat menggunakan daftar drop-down di samping judul setiap grafik untuk beralih antara jumlah GC dan durasi rata-rata GC.
Memori JVM: Menampilkan tren memori heap yang digunakan dan memori heap maksimum dalam rentang waktu tertentu. Anda dapat menggunakan daftar drop-down di samping judul setiap grafik untuk beralih ke tren memori non-heap yang digunakan dan memori non-heap maksimum.
CatatanPemantauan Aplikasi ARMS mengumpulkan metrik JVM melalui JMX. Wilayah memori non-heap yang dilaporkan oleh ARMS lebih sedikit dibandingkan proses Java aktual. Akibatnya, jumlah total memori heap dan non-heap yang ditampilkan di ARMS mungkin berbeda dari ukuran RES yang ditunjukkan oleh perintah
top. Untuk informasi selengkapnya, lihat Detail Memori Pemantauan JVM.
Anda dapat mengklik ikon
untuk membuka kotak dialog tempat Anda dapat melihat statistik suatu metrik dalam rentang waktu tertentu atau membandingkan statistik pada tanggal berbeda untuk rentang waktu yang sama. Anda juga dapat mengklik ikon untuk beralih antara grafik kolom dan grafik tren.Di area daftar instans (③), Anda dapat melihat IP instans, penggunaan CPU, permintaan CPU, batas CPU, utilisasi CPU (menampilkan - jika tidak ada batas CPU yang ditetapkan), penggunaan memori, permintaan memori, batas memori, utilisasi memori (menampilkan - jika tidak ada batas memori yang ditetapkan), penggunaan disk, batas disk, utilisasi disk (menampilkan - jika tidak ada batas disk yang ditetapkan), beban, jumlah Full GC, jumlah Young GC, penggunaan memori heap, penggunaan memori non-heap, dan metrik RED (permintaan, error, dan waktu respons rata-rata).
Di daftar instans, Anda dapat melakukan aksi berikut:
Klik IP instans atau Details di kolom Actions untuk melihat detail instans. Untuk informasi selengkapnya, lihat Detail Instans.
Di kolom Actions, klik Trace untuk melihat detail jejak instans. Untuk informasi selengkapnya, lihat Analisis Jejak.
Lingkungan Kontainer (Pengumpulan Mandiri ARMS)
Di area filter cepat (①), Anda dapat memfilter grafik dan daftar instans berdasarkan alamat host.
Di area grafik tren (②), Anda dapat melihat kurva deret waktu untuk metrik infrastruktur monitoring, GC, dan memori JVM.
Infrastruktur monitoring: Menampilkan tren penggunaan CPU dan memori dalam rentang waktu tertentu.
Instance GC: Menampilkan tren Full GC dan Young GC dalam rentang waktu tertentu. Anda dapat menggunakan daftar drop-down di samping judul setiap grafik untuk beralih antara jumlah GC dan durasi rata-rata GC.
Memori JVM: Menampilkan tren memori heap yang digunakan dan memori heap maksimum dalam rentang waktu tertentu. Anda dapat menggunakan daftar drop-down di samping judul setiap grafik untuk beralih ke tren memori non-heap yang digunakan dan memori non-heap maksimum.
CatatanPemantauan Aplikasi ARMS mengumpulkan metrik JVM melalui JMX. Wilayah memori non-heap yang dilaporkan oleh ARMS lebih sedikit dibandingkan proses Java aktual. Akibatnya, jumlah total memori heap dan non-heap yang ditampilkan di ARMS mungkin berbeda dari ukuran RES yang ditunjukkan oleh perintah
top. Untuk informasi selengkapnya, lihat Detail Memori Pemantauan JVM.
Anda dapat mengklik ikon
untuk membuka kotak dialog tempat Anda dapat melihat statistik suatu metrik dalam rentang waktu tertentu atau membandingkan statistik pada tanggal berbeda untuk rentang waktu yang sama. Anda juga dapat mengklik ikon untuk beralih antara grafik kolom dan grafik tren.Di area daftar instans (③), Anda dapat melihat IP instans, penggunaan CPU, penggunaan memori, beban, jumlah Full GC, jumlah Young GC, penggunaan memori heap, penggunaan memori non-heap, dan metrik RED (permintaan, error, dan waktu respons rata-rata).
Di daftar instans, Anda dapat melakukan aksi berikut:
Klik IP instans atau Details di kolom Actions untuk melihat detail instans. Untuk informasi selengkapnya, lihat Detail Instans.
Di kolom Actions, klik Trace untuk melihat detail jejak instans. Untuk informasi selengkapnya, lihat Analisis Jejak.
Detail Instance
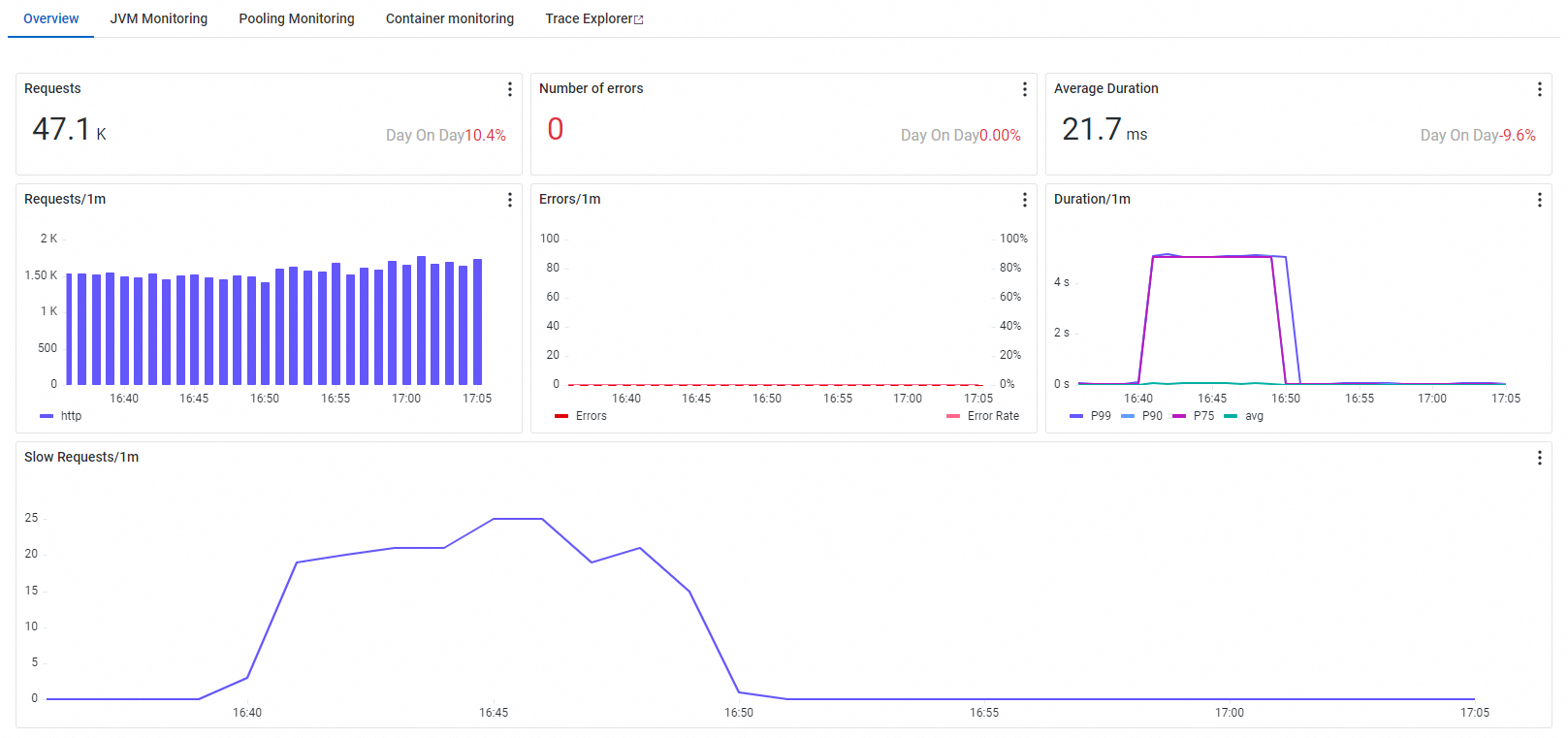
Ikhtisar
Tab Overview menampilkan jumlah permintaan, jumlah error, waktu respons rata-rata, dan informasi panggilan lambat untuk antarmuka yang dipilih.
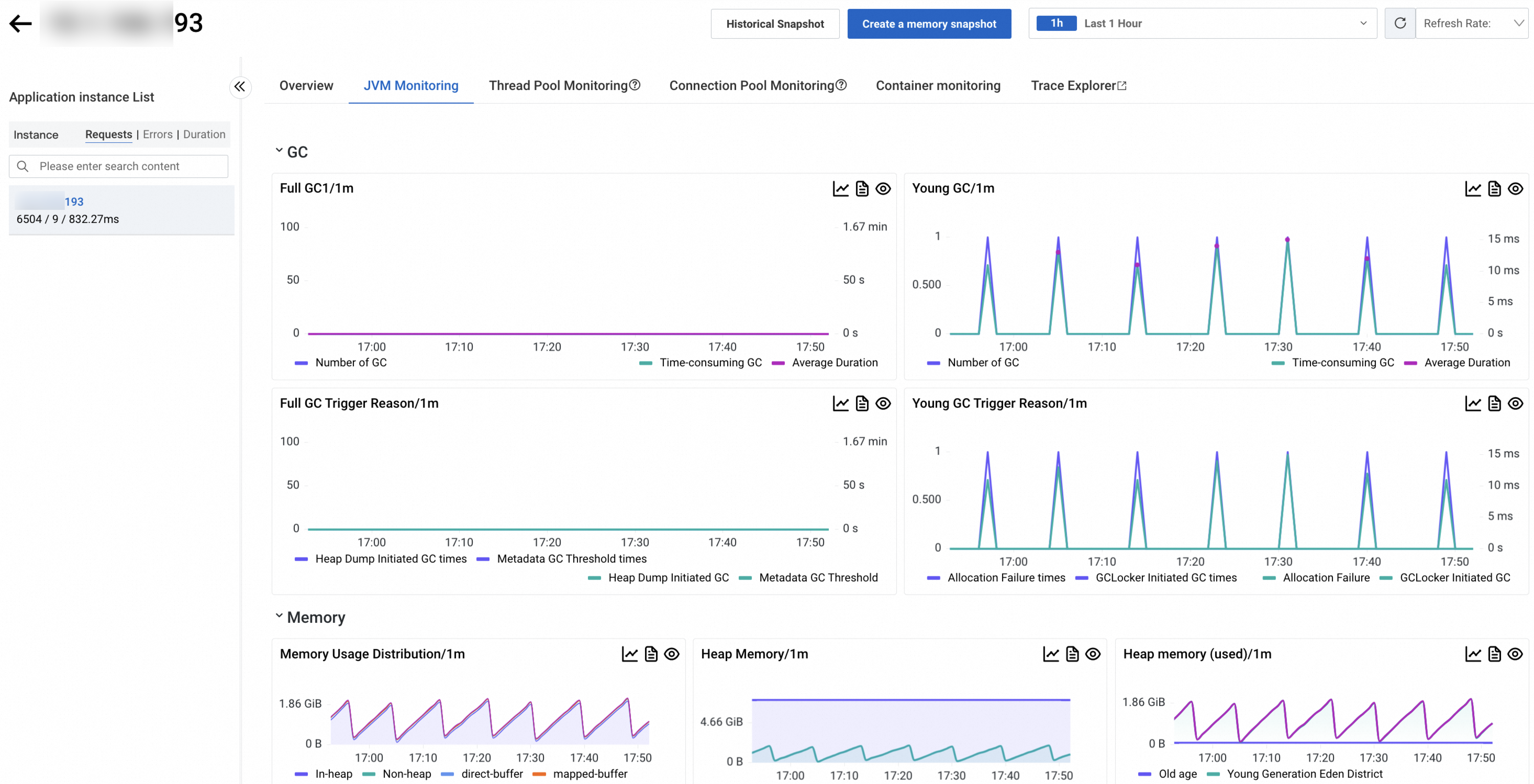
Pemantauan JVM
Tab JVM Monitoring menampilkan metrik GC, memori, thread, dan file untuk instans yang dipilih.
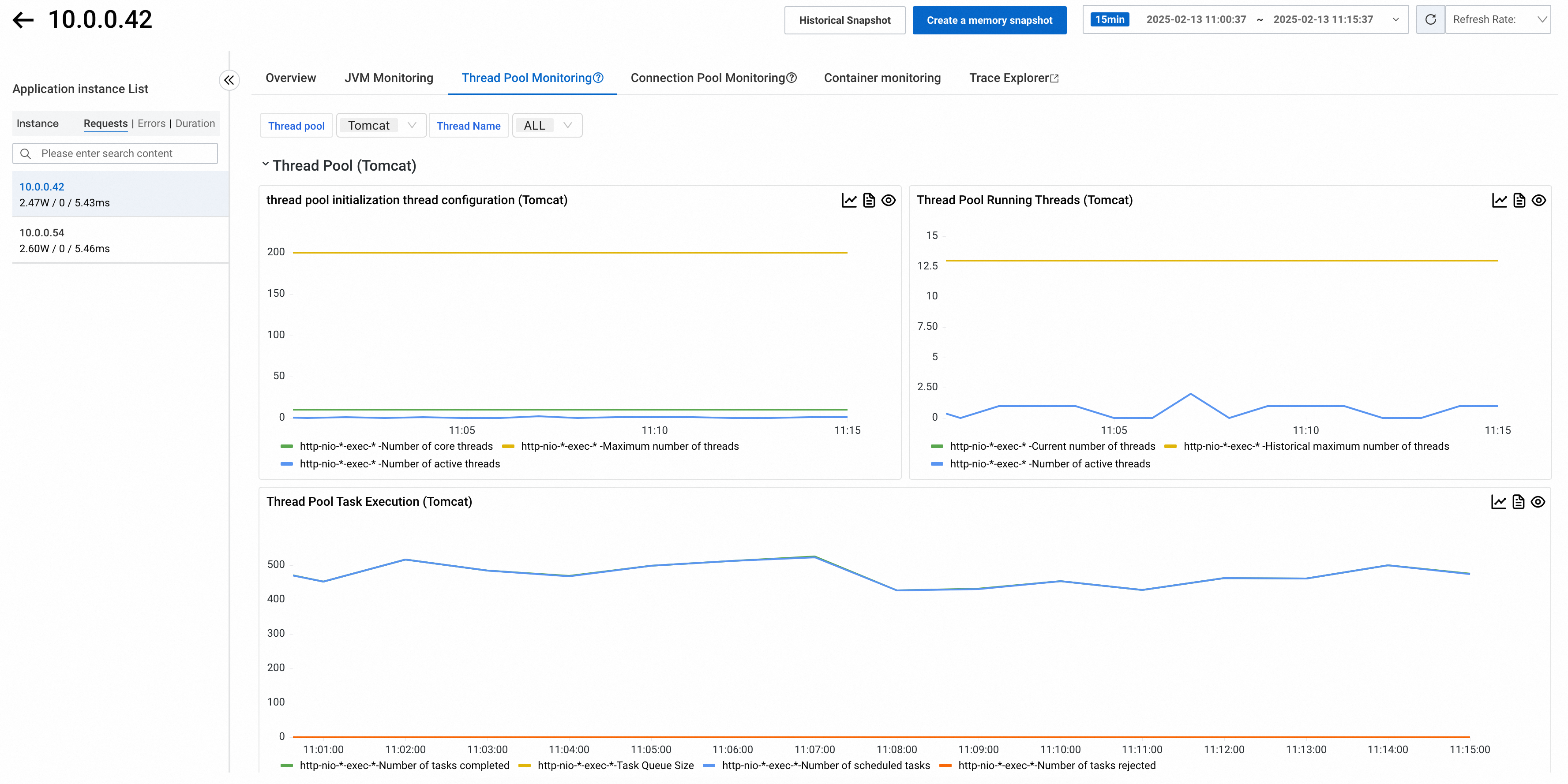
Pemantauan Kolam Thread
Versi Probe 4.1.x atau Lebih Baru
Tab Thread Pool Monitoring menampilkan metrik untuk kolam thread yang digunakan aplikasi Anda, termasuk konfigurasi thread inti, status thread aktif, dan status eksekusi tugas.
Di bagian atas tab, Anda dapat memfilter kolam thread berdasarkan jenis dan nama.
Versi Probe Sebelum 4.1.x
Tab Thread Pool Monitoring menampilkan jumlah thread inti, jumlah thread saat ini, jumlah maksimum thread, jumlah thread aktif, dan kapasitas antrian tugas untuk kolam thread yang digunakan aplikasi Anda.
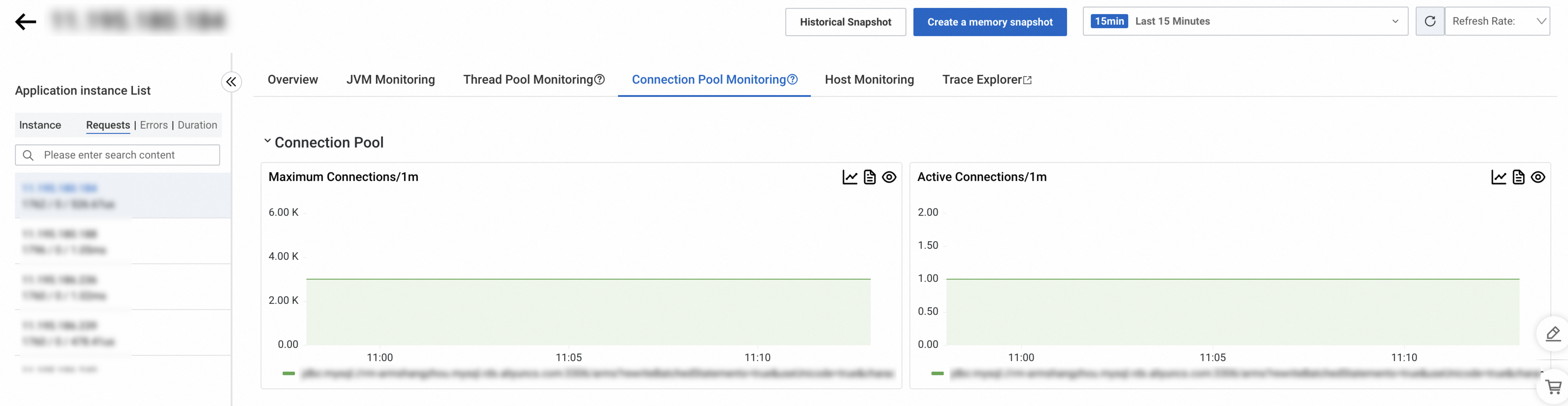
Pemantauan Kolam Koneksi
Versi Probe 4.1.x atau Lebih Baru
Tab Connection Pool Monitoring menampilkan metrik untuk kolam koneksi yang digunakan aplikasi Anda, termasuk konfigurasi inisialisasi dan status waktu proses.
Di bagian atas tab, Anda dapat memfilter kolam koneksi berdasarkan jenis.
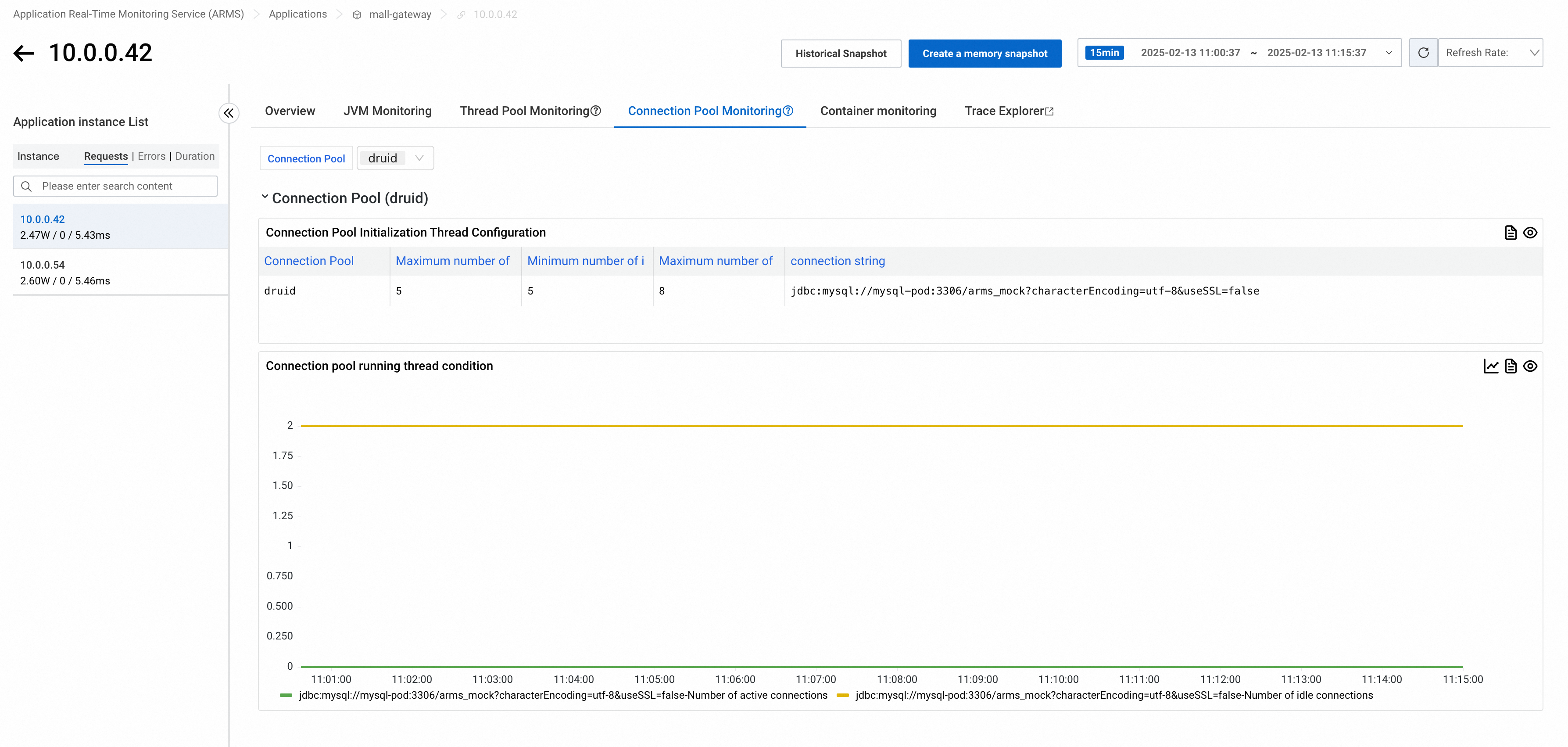
Versi Probe Sebelum 4.1.x
Tab Connection Pool Monitoring menampilkan jumlah maksimum koneksi dan jumlah koneksi aktif untuk kolam koneksi yang digunakan aplikasi Anda.
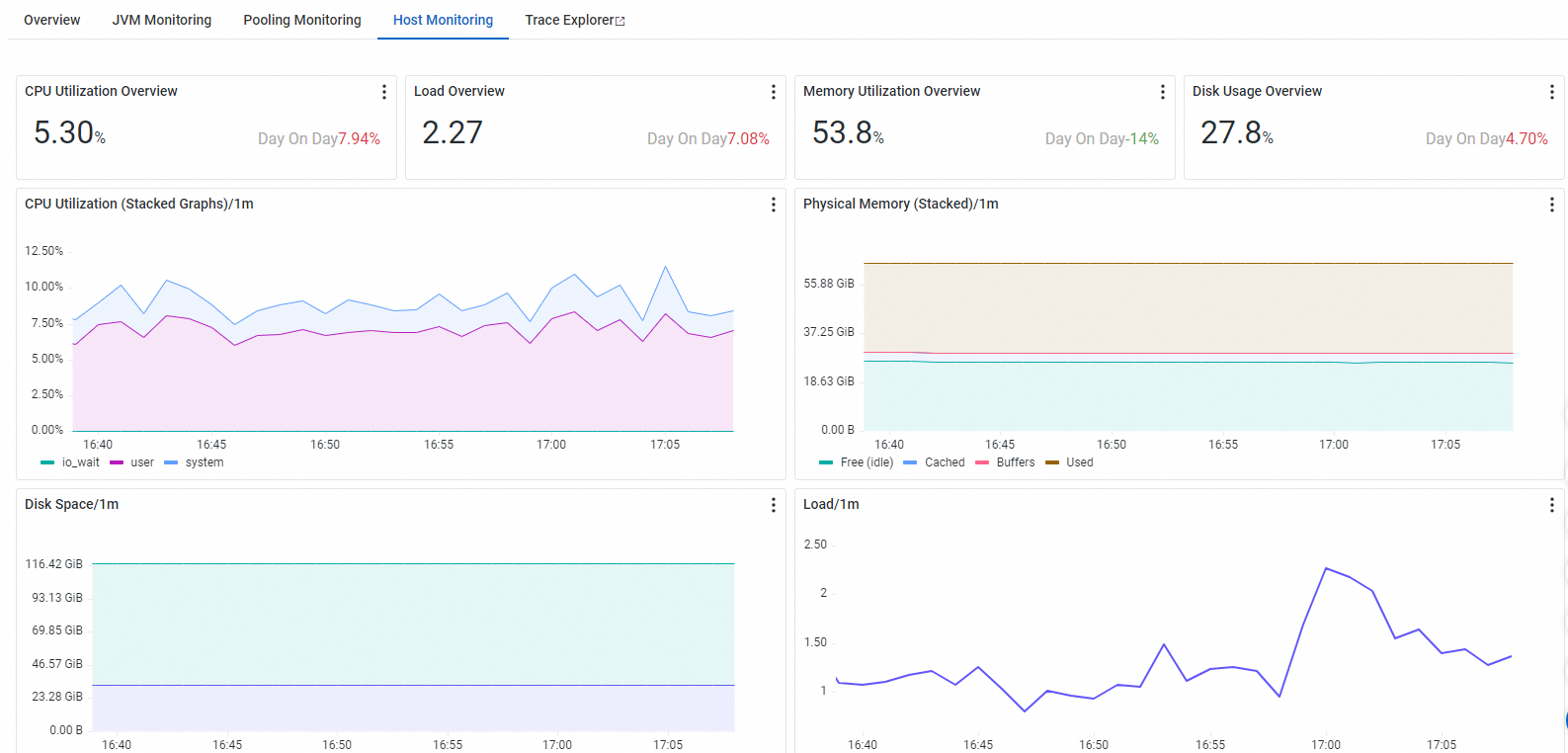
Pemantauan Host
Tab Host Monitoring menampilkan metrik CPU, memori, disk, beban, network traffic, dan paket jaringan.
Pemantauan Kontainer
Lingkungan Kontainer (Prometheus)
Untuk mengintegrasikan dengan Managed Service for Prometheus, lihat Prometheus Instance for Container Service.
Tab Container Monitoring menampilkan metrik CPU, memori, disk, beban, network traffic, dan paket jaringan dari perspektif kontainer.
Lingkungan Kontainer (Pengumpulan Mandiri ARMS)
Jika Anda belum mengintegrasikan dengan Managed Service for Prometheus, pastikan versi probe ARMS Anda adalah 4.1.0 atau lebih baru. Untuk informasi selengkapnya tentang versi probe, lihat Panduan Versi Probe (Java Agent).
Tab Container Monitoring menampilkan kurva deret waktu untuk CPU, memori, dan network traffic dari perspektif kontainer.
Analisis Jejak
Analisis jejak menggunakan data jejak yang tersimpan untuk melakukan analisis real-time. Anda dapat menggabungkan filter dan dimensi agregasi untuk memenuhi kebutuhan diagnostik kustom dalam berbagai skenario. Untuk informasi selengkapnya, lihat Analisis Jejak.
Referensi
Untuk informasi selengkapnya tentang metrik Pemantauan Aplikasi, lihat Referensi Metrik Pemantauan Aplikasi.
FAQ
Apa hubungan antara data tingkat aplikasi dan data mesin tunggal?
Metrik RED (permintaan, error, dan latensi):
Jumlah permintaan, jumlah panggilan lambat, dan jumlah kode status HTTP: Metrik tingkat aplikasi adalah jumlah dari metrik per-instans.
Waktu respons: Metrik tingkat aplikasi adalah rata-rata dari metrik per-instans.
Metrik JVM:
Jumlah GC dan durasi GC: Metrik tingkat aplikasi adalah jumlah dari metrik per-instans.
Memori heap dan jumlah thread: Metrik tingkat aplikasi adalah nilai maksimum di antara semua metrik per-instans.
Metrik kolam thread dan kolam koneksi
Semua metrik: Metrik tingkat aplikasi adalah rata-rata dari metrik per-instans.
Metrik sistem
Semua metrik: Metrik tingkat aplikasi adalah nilai maksimum di antara semua metrik per-instans.
Panggilan SQL dan NoSQL: Mirip dengan metrik RED, jumlah tingkat aplikasi adalah jumlah dari jumlah per-instans, sedangkan metrik lainnya adalah rata-rata dari metrik per-instans.
Metrik exception: Metrik tingkat aplikasi adalah jumlah dari metrik per-instans.
Traffic tidak merata di seluruh instans
Pada versi probe 3.x, mengaktifkan optimasi memori dapat menyebabkan beberapa metrik terlewat. Masalah ini telah diselesaikan pada versi probe 4.x.
Satu permintaan Undertow dihitung dua kali
Pada versi probe sebelum 3.2.x, instrumentasi untuk DeferredResult menyebabkan satu panggilan dieksekusi dua kali. Masalah ini telah diselesaikan pada versi probe 3.2.x dan lebih baru.
Kuota CPU atau memori di Pemantauan Kontainer tidak sesuai dengan pengaturan Pod
Periksa apakah Pod Anda mendefinisikan beberapa kontainer. Metrik ini adalah jumlah kuota untuk semua kontainer dalam Pod.
Beberapa metrik sistem hilang, tidak akurat, atau menunjukkan penggunaan CPU 100%
Versi probe sebelum 4.x tidak mengumpulkan metrik sistem di Windows. Masalah ini telah diselesaikan pada versi probe 4.x dan lebih baru.
Mengapa Full GC terjadi tepat setelah startup aplikasi?
Hal ini biasanya terjadi karena ukuran metaspace tidak dikonfigurasi. Ukuran metaspace default sekitar 20 MB. Selama startup, aplikasi mungkin memperluas metaspace, yang memicu Full GC. Anda dapat mengatur ukuran awal dan maksimum metaspace menggunakan parameter -XX:MetaspaceSize dan -XX:MaxMetaspaceSize.
Bagaimana VM Stack dihitung?
Metrik ini dihitung sebagai jumlah thread live dikalikan 1 MB. Ukuran stack thread default adalah 1 MB. Jika Anda menentukan ukuran stack berbeda menggunakan parameter -Xss, metrik ini mungkin berbeda dari nilai aktual.
state=live mencakup status berikut: live, blocked, new, runnable, timed-wait, dan wait.
Bagaimana metrik JVM dikumpulkan?
ARMS mengambil metrik JVM menggunakan antarmuka JDK standar:
Metrik terkait memori:
ManagementFactory.getMemoryPoolMXBeans
java.lang.management.MemoryPoolMXBean#getUsage
Metrik terkait GC:
Versi Probe Sebelum 4.4.0
ManagementFactory.getGarbageCollectorMXBeans
java.lang.management.GarbageCollectorMXBean#getCollectionCount
java.lang.management.GarbageCollectorMXBean#getCollectionTime
Versi Probe 4.4.0 atau Lebih Baru
Anda dapat memperolehnya dari GarbageCollectorMXBean dengan berlangganan event GarbageCollectionNotificationInfo.
Mengapa nilai maksimum memori heap JVM adalah -1?
Nilai -1 menunjukkan bahwa ukuran maksimum memori heap tidak ditetapkan.
Mengapa penggunaan memori heap JVM tidak sama dengan ukuran maksimum memori heap?
Sesuai aturan alokasi memori JVM, parameter -Xms menetapkan ukuran heap awal. Heap diperluas ketika ruang bebas tidak mencukupi, hingga ukuran maksimum yang ditetapkan oleh -Xmx. Ketidaksesuaian menunjukkan bahwa ekspansi belum terjadi. Nilai penggunaan mencerminkan penggunaan aktual saat ini.
Frekuensi GC JVM secara bertahap meningkat
Hal ini dapat terjadi jika Anda menggunakan ParallelGC, yang merupakan algoritma GC default di JDK 8. ParallelGC mengaktifkan -XX:+UseAdaptiveSizePolicy secara default. Pengaturan ini secara dinamis menyesuaikan ukuran heap, termasuk ukuran generasi muda dan SurvivorRatio, untuk memenuhi tujuan jeda GC. Ketika Young GC terjadi secara sering, ruang survivor mungkin menyusut. Objek kemudian dipromosikan dengan cepat ke generasi lama, yang menyebabkan pertumbuhan lebih cepat dan Full GC lebih sering. Untuk informasi selengkapnya, lihat dokumentasi Java.
Tidak ada data untuk pemantauan kolam thread atau kolam koneksi
Di halaman Custom Configuration, di bawah Advanced Settings, pastikan pemantauan kolam thread dan kolam koneksi diaktifkan.
Verifikasi bahwa framework Anda didukung. Untuk informasi selengkapnya, lihat Pemantauan Kolam Thread dan Kolam Koneksi.
Jumlah maksimum koneksi HikariCP tidak sesuai ekspektasi
Versi probe sebelum 3.2.x salah mengambil jumlah maksimum koneksi. Masalah ini telah diselesaikan pada versi probe 3.2.x dan lebih baru.
Metrik pemantauan pooling ditampilkan sebagai nilai desimal
Probe mengumpulkan data setiap 15 detik. Konsol menampilkan nilai rata-rata dalam rentang waktu tertentu. Misalnya, jika empat titik data yang dikumpulkan dalam satu menit adalah 0, 0, 1, dan 0, rata-ratanya adalah 0,25.
Kolam thread atau kolam koneksi penuh, tetapi pemantauan tidak menunjukkan perubahan
Jika log atau catatan lain mengonfirmasi bahwa kolam thread atau kolam koneksi penuh, tetapi ARMS tidak menunjukkan peningkatan metrik yang sesuai, waktu sampling mungkin tidak sejajar dengan puncaknya. ARMS mengumpulkan metrik kolam thread dan kolam koneksi setiap 15 detik. Lonjakan singkat dalam interval ini mungkin tidak tertangkap.
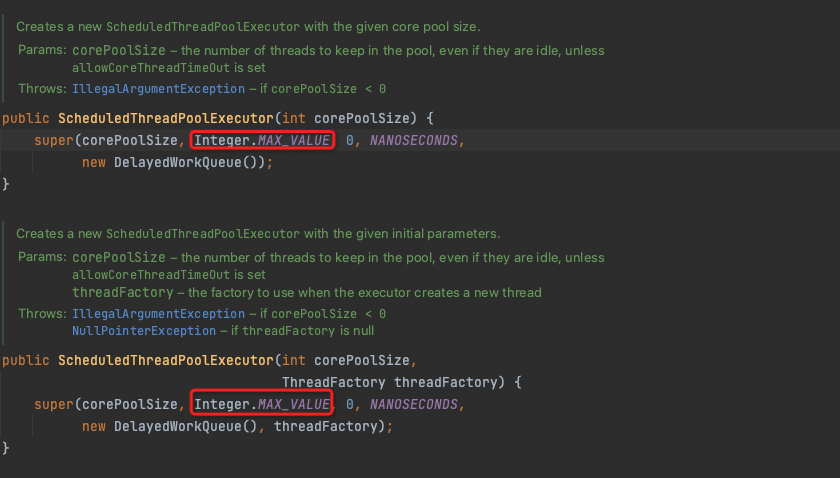
Jumlah maksimum thread kolam thread tidak sesuai ekspektasi atau menunjukkan 2,1 miliar
ARMS mengambil jumlah maksimum thread langsung dari objek kolam thread. Hal ini jarang gagal. Nilai yang tidak sesuai kemungkinan besar berarti konfigurasi maksimum Anda tidak diterapkan.
Nilai 2,1 miliar biasanya menunjukkan kolam thread terjadwal. Kolam thread terjadwal secara default menggunakan Integer.MAX_VALUE, seperti yang ditunjukkan di bawah.
Metrik kolam thread Tomcat tidak sesuai ekspektasi
ARMS mengambil metrik kolam thread langsung dari objek kolam thread. Hal ini jarang gagal. Jika beberapa metrik, seperti jumlah maksimum thread, jumlah thread aktif, dan jumlah thread inti, semuanya berbeda, periksa apakah aplikasi Anda mengekspos layanan Tomcat pada beberapa port. Misalnya, Spring Actuator membuka port tambahan untuk mengekspos metrik. Dalam kasus seperti ini, ARMS mungkin menggabungkan metrik dari beberapa kolam thread karena konvergensi dimensi. Untuk mengatasi masalah ini, upgrade ke versi probe 4.1.10 atau lebih baru. Kemudian, di halaman , di bagian Pooling Monitoring Configuration, atur Thread Pool Thread Name Pattern Extraction Strategy menjadi Replace trailing digits with *.
Tidak ada data untuk kolam thread atau kolam koneksi sebelum waktu tertentu
Hal ini dapat terjadi jika aplikasi Anda memicu tugas terjadwal. Data untuk kolam thread atau kolam koneksi hanya muncul setelah tugas diinisialisasi. Metrik berbasis traffic, seperti jumlah permintaan untuk endpoint API, sering kali berperilaku serupa.
Tidak ada data untuk kolam koneksi HttpClient
Mulai dari versi probe ARMS 4.x, ARMS tidak lagi mendukung pemantauan kolam koneksi untuk OkHttp3 dan Apache HttpClient. Hal ini karena framework tersebut membuat kolam koneksi terpisah untuk setiap domain eksternal. Ketika ada banyak domain, overhead keseluruhan dan risiko stabilitas meningkat. Karena alasan ini, ARMS tidak lagi mendukungnya.
Tidak ada data pemantauan kontainer yang muncul setelah mengintegrasikan aplikasi ACK
Hal ini dapat terjadi jika Akun Alibaba Cloud yang digunakan untuk membuat kluster ACK berbeda dengan akun yang digunakan untuk mengintegrasikan dengan ARMS. ARMS hanya menampilkan data pemantauan kontainer untuk sumber daya di bawah Akun Alibaba Cloud yang sama.
Tingkat buka handle file bukan nol, tetapi jumlah handle file nol
Konfirmasi apakah aplikasi Anda berjalan di JDK 9 atau lebih baru dan menggunakan versi probe ARMS 3.x. Jika demikian, logika pengumpulan metrik memiliki masalah kompatibilitas di lingkungan ini. Masalah ini telah diselesaikan pada versi probe 4.2.2 dan lebih baru. Anda dapat upgrade probe Anda ke versi terbaru.
Penggunaan memori fisik proses JVM berbeda signifikan dari penggunaan memori heap pemantauan JVM
Hal ini biasanya terjadi karena proses JVM menggunakan jumlah besar memori off-heap. ARMS hanya memantau memori heap dan sebagian memori off-heap. Untuk informasi selengkapnya tentang bagian memori JVM yang dapat dipantau ARMS, lihat Detail Memori Pemantauan JVM. Jika penggunaan memori off-heap tinggi, lihat bagian analisis kebocoran memori off-heap dalam dokumen tersebut.
Mengapa Druid menampilkan lebih banyak koneksi idle daripada pengaturan koneksi idle maksimum?
MaxIdle hanya ada untuk membantu pengguna bermigrasi dari DBCP. Fitur ini tidak berpengaruh.
Beberapa instans di-upgrade ke versi probe terbaru, tetapi tidak ada data yang muncul
Jika Anda melakukan upgrade dari versi probe sebelum 4.1.x, Anda harus meng-upgrade semua instans ke versi terbaru. Halaman kemudian akan menyesuaikan secara otomatis dan menampilkan data.