Fitur penanganan pengecualian menampilkan peristiwa abnormal yang terjadi atau sedang berlangsung di kluster basis data dalam 3 hari terakhir. Anda dapat menggunakan fitur ini untuk memantau status kesehatan kluster dan, ketika peristiwa abnormal terdeteksi, melakukan analisis penyebab utama guna mengidentifikasi masalah.
Lihat daftar peristiwa abnormal untuk semua instans
Masuk ke Konsol ApsaraDB for OceanBase.
Di panel navigasi sebelah kiri, pilih Autonomy Service > Exception Handling.
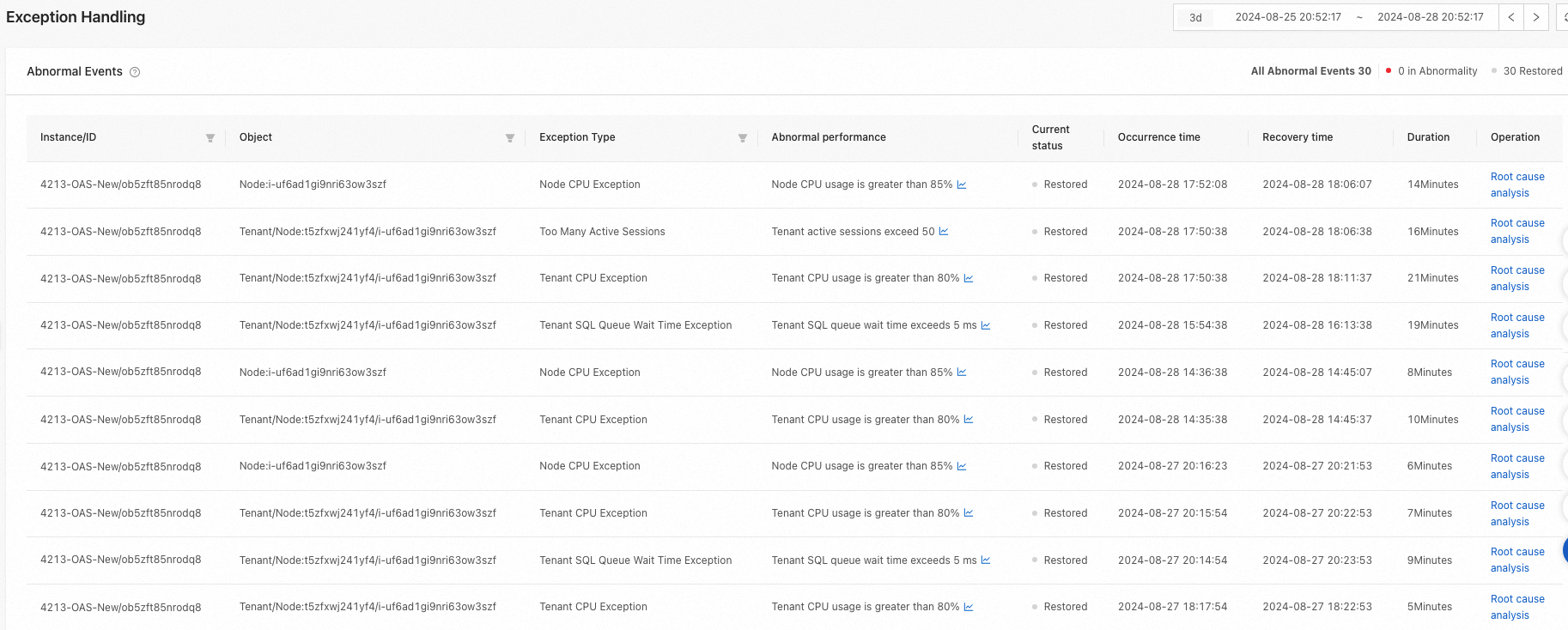
Di bagian Abnormal Events, tinjau daftar peristiwa abnormal untuk semua instans.
Secara default, sistem menampilkan semua peristiwa abnormal dalam 3 hari terakhir, baik yang masih berlangsung maupun yang telah dipulihkan. Jenis peristiwa abnormal yang didukung meliputi: node CPU exception, tenant CPU exception, tenant SQL queue waiting time exception, SQL mass error reporting exception, data disk I/O usage exception, tenant active session number exception, tenant disk I/O time exception, node clog disk I/O high usage, node data disk I/O high time, node data disk capacity high usage.
Lihat peristiwa abnormal untuk satu instans
Di bagian Abnormal Events, klik Root Cause Analysis di kolom Operation untuk instans target.
Sistem akan mengarahkan ulang ke halaman Exception Handling pusat diagnostik.
Di bagian Abnormal Events, tinjau peristiwa abnormal untuk instans target, termasuk Object, Exception Type, Abnormal Performance, Current Status, Occurrence Time, Recovery Time, Duration, dan Operation.
Klik Root Cause Analysis di kolom Operation untuk satu peristiwa abnormal guna melihat analisis penyebab utama dan saran optimasi.
CatatanAnda dapat mengklik View Smart Interpretation untuk melihat hasil diagnosis dan saran yang diberikan oleh AI. Konten interpretasi cerdas AI hanya bersifat informatif.
Jika penyebab peristiwa abnormal terdeteksi di grafik analisis, sistem akan menyorotnya dengan warna merah dan memberikan saran optimasi.
CatatanDi grafik analisis, setiap node mewakili aturan analisis. Saat melakukan analisis penyebab utama, sistem menjelajahi grafik untuk menemukan node penyebab utama. Node penyebab utama disorot dengan warna merah, sedangkan node hijau menunjukkan bahwa aturan tidak mencapai penyebab utama.
Berikut adalah contohnya:
Saat mendeteksi Tenant Queue Waiting Becomes Longer dalam periode waktu tertentu, sistem memberikan prompt bahwa penggunaan CPU terlalu tinggi. Di bagian Analysis Path, Anda dapat mengklik kotak yang disorot merah untuk melihat analisis penyebab utama yang sesuai.
Di bagian SQL Summary Information, sistem menampilkan SQL Summary Time Period, Total Executions, Total Number of Error Executions, Maximum Elapsed Time (ms), CPU Time (ms), dan Plan Generation Time (ms) secara default. Anda dapat melihat lebih banyak informasi dengan mengklik Manage Columns.
Di bagian Possible Root Cause SQL, Anda dapat melihat SQL yang mungkin menyebabkan masalah dan mengklik View SQL Details di kolom Actions.
Jika penyebab peristiwa abnormal tidak terdeteksi di grafik analisis, sistem akan memberikan saran optimasi di bagian Solution.
Berikut adalah contohnya:
Saat mendeteksi Tenant CPU Exception, sistem tetap menampilkan grafik analisis dan memberikan saran optimasi di bagian Solution.