Setelah AnalyticDB for MySQL menerima sebuah kueri, kueri tersebut dibagi menjadi beberapa stage. Stage-stage ini didistribusikan ke node pekerja dan node pelaksana untuk membaca serta menghitung data. Beberapa stage dapat dijalankan secara paralel, sedangkan yang lain memiliki dependensi dan harus dijalankan secara berurutan. Kompleksitas ini menyulitkan analisis durasi pernyataan SQL yang kompleks. Anda dapat menggunakan detail stage dan task di Konsol atau melalui API untuk menganalisis kueri lambat.
Prosedur
Masuk ke Konsol AnalyticDB for MySQL. Di pojok kiri atas Konsol, pilih wilayah. Di panel navigasi sebelah kiri, klik Clusters. Temukan kluster yang ingin Anda kelola, lalu klik ID kluster tersebut.
-
Di panel navigasi sebelah kiri, klik Diagnostics and Optimization.
-
Pada bagian SQL Queries, klik Diagnose untuk kueri yang diinginkan.
-
Klik tab Stages & Tasks. Bagian Query Properties di bagian atas halaman menampilkan informasi seperti waktu mulai dan akhir, username, durasi antrian, durasi total, memori puncak, volume data yang dipindai, volume data yang dikembalikan, status, dan resource group. Tab Stages & Tasks mencantumkan detail eksekusi setiap stage, termasuk Stage ID, status, jumlah baris input/output dan volume data, memori puncak, serta durasi kumulatif. Untuk penjelasan hasil kueri stage, lihat Parameter stage.
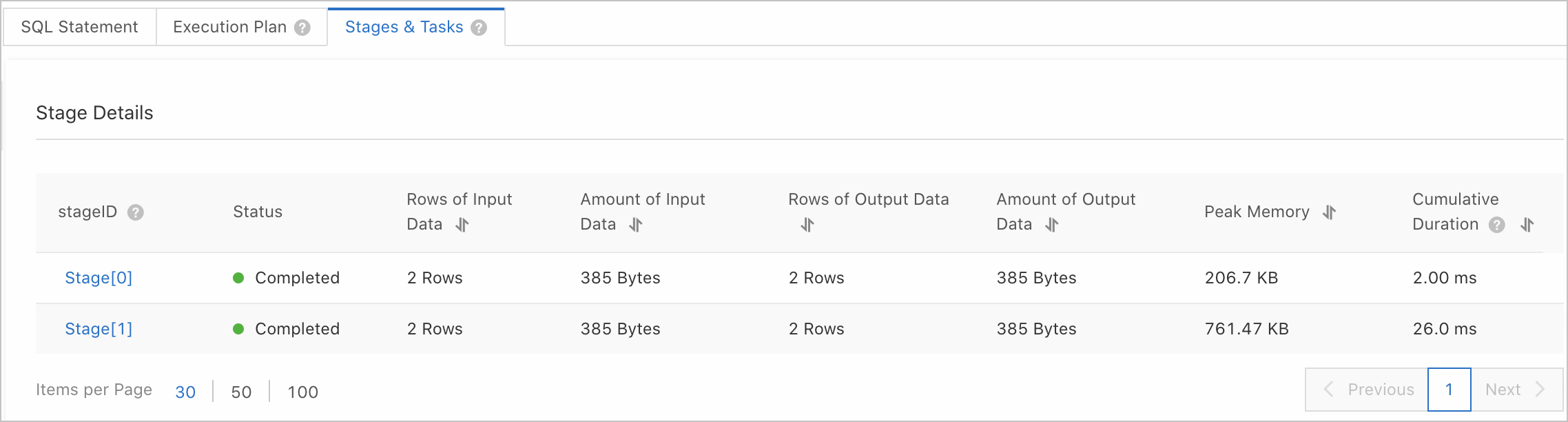
-
Untuk memecahkan masalah kueri lambat, klik Stage ID untuk melihat detail semua task dalam stage tersebut. Untuk penjelasan hasil kueri task, lihat Parameter task.
PentingDetail task hanya tersedia untuk kueri yang membutuhkan waktu lebih dari 1 detik untuk diselesaikan.
Parameter
Parameter stage
|
Parameter |
Deskripsi |
|
Stage ID |
Identifier unik dari stage. ID ini sesuai dengan Stage ID pada pohon rencana eksekusi. |
|
Status |
Status eksekusi stage. Nilai yang valid:
|
|
Input rows |
Jumlah baris pada data masukan stage. |
|
Input data size |
Ukuran data masukan stage. |
|
Output rows |
Jumlah baris pada data keluaran stage. |
|
Output data size |
Ukuran data keluaran stage. |
|
Peak memory |
Penggunaan memori maksimum dari stage. |
|
Cumulative duration |
Jumlah waktu yang dikonsumsi oleh semua operator dalam stage. Parameter ini membantu Anda mengidentifikasi stage yang memakan banyak waktu atau memiliki penggunaan CPU tinggi. Anda tidak dapat langsung membandingkan cumulative duration dengan durasi kueri. Anda juga harus mempertimbangkan tingkat paralelisme stage untuk menentukan hubungan antara durasi kueri dan cumulative duration. |
Parameter task
|
Parameter |
Deskripsi |
|
Task ID |
Identifier unik dari task. Sebagai contoh, dalam |
|
Status |
Status eksekusi task. Nilai yang valid:
|
|
Input data |
Jumlah baris dan ukuran data masukan task. Anda dapat mengurutkan task berdasarkan nilai ini untuk memeriksa apakah terjadi kesenjangan data pada data masukan stage. Jika terjadi kesenjangan data, hal ini menunjukkan bahwa klausa GROUP BY atau JOIN menggunakan kunci distribusi yang tidak efisien. Anda perlu menelusuri kembali ke stage hulu untuk menyelesaikan masalah tersebut. Catatan
Kesenjangan data terjadi ketika kunci distribusi yang tidak efisien menyebabkan data terdistribusi secara tidak merata di seluruh node pekerja. |
|
Output data |
Jumlah baris dan ukuran data keluaran task. Dengan memeriksa properti node Aggregation atau Join pada rencana operator stage saat ini, Anda dapat memetakkannya ke pernyataan SQL dan memeriksa apakah bidang gabungan digunakan dalam kunci partisi atau kondisi JOIN. Sebagai contoh, |
|
Peak memory |
Memori maksimum yang digunakan selama eksekusi task. Peak memory sebanding dengan ukuran data masukan. Parameter ini dapat membantu Anda menentukan apakah suatu kueri gagal karena penggunaan memori yang sangat tidak seimbang pada node tertentu. |
|
Table read duration |
Saat pohon operator stage berisi operator TableScan, parameter ini menunjukkan total waktu yang dihabiskan oleh semua operator TableScan dalam stage untuk membaca data tabel. Durasi ini merupakan nilai kumulatif dari beberapa mesin dan thread sehingga tidak dapat langsung dibandingkan dengan durasi kueri. Dengan membandingkannya terhadap cumulative duration, Anda dapat menentukan apakah waktu eksekusi stage terutama dihabiskan untuk pemindaian data. |
|
Data read from tables |
Saat pohon operator stage berisi operator TableScan, parameter ini menunjukkan jumlah baris dan volume data yang dibaca dari tabel sumber oleh semua operator TableScan dalam stage. Dengan mengurutkan berdasarkan bidang ini, Anda dapat menentukan apakah terjadi kesenjangan data pada tabel sumber. Jika iya, Anda dapat menggunakan Konsol untuk mendiagnosis skew kunci distribusi. Untuk informasi lebih lanjut, lihat Data modeling diagnostics. |
|
Created at |
Waktu saat task dibuat. |
|
Queuing duration |
Waktu yang dihabiskan task dalam antrian sebelum eksekusi dimulai. |
|
Ended at |
Waktu saat task selesai dieksekusi. |
|
Interval between start and end time |
Waktu yang berlalu antara waktu pembuatan task dan waktu selesainya task. Sebagai contoh, jika task dibuat pada 2022-12-12 12:00:00 dan selesai pada 2022-12-12 12:00:04, intervalnya adalah 4 detik. Dengan membandingkan interval ini terhadap durasi kueri, Anda dapat mengidentifikasi lokasi bottleneck performa. Misalnya, jika durasi kueri adalah 6 detik dan intervalnya 4 detik, bottleneck berada pada stage saat ini. Untuk metode perhitungan detail, lihat Contoh: Menghitung durasi dan konkurensi task. |
|
Cumulative duration |
Jumlah waktu eksekusi semua thread dalam task ini. Untuk metode perhitungan detail, lihat Contoh: Menghitung durasi dan konkurensi task. |
|
Computing time ratio |
Rasio antara waktu pemrosesan data aktual terhadap siklus hidup subtask. Rumus: Computing time ratio = (Cumulative duration / Subtask concurrency) / Interval between start and end time. Dalam rumus ini, (Cumulative duration / Subtask concurrency) merepresentasikan rata-rata waktu yang dihabiskan setiap thread untuk memproses data, sedangkan interval mencakup waktu pemrosesan aktual, durasi antrian subtask, dan latensi jaringan. Untuk metode perhitungan detail, lihat Contoh: Menghitung durasi dan konkurensi task. Catatan
Rasio waktu komputasi yang lebih kecil menunjukkan interval antara waktu mulai dan akhir yang lebih panjang, artinya Anda perlu mengidentifikasi operator yang memakan waktu lama. Sebaliknya, rasio yang lebih besar menunjukkan interval yang lebih pendek, yang mengarah pada masalah seperti antrian resource atau latensi jaringan. |
|
Subtask concurrency |
Setiap task dieksekusi oleh beberapa thread konkuren pada satu mesin. Jumlah thread yang menjalankan task komputasi secara bersamaan disebut subtask concurrency. Untuk metode perhitungan detail, lihat Contoh: Menghitung durasi dan konkurensi task. |
|
Execution node |
Alamat IP internal node tempat task dieksekusi. Jika beberapa kueri menunjukkan long tail pada node yang sama, Anda perlu menyelidiki node tersebut. Catatan
Long tail terjadi ketika beberapa task dalam eksekusi terdistribusi AnalyticDB for MySQL membutuhkan waktu jauh lebih lama untuk diselesaikan dibandingkan task lainnya. |
Contoh: Menghitung durasi dan konkurensi task
Contoh ini menunjukkan cara menghitung interval antara waktu mulai dan akhir, cumulative duration, computing time ratio, dan subtask concurrency untuk task bernama Task 2.1.
Asumsikan Task 2.1 termasuk dalam stage[2], yang terdiri dari empat operator: StageOutput, Join, TableScan, dan RemoteSource. Gambar berikut menunjukkan pohon operator.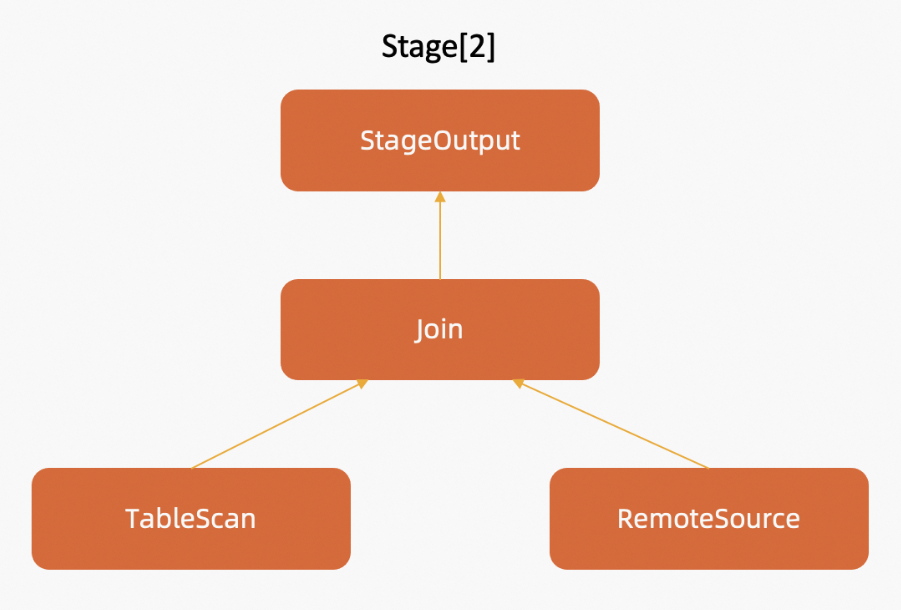
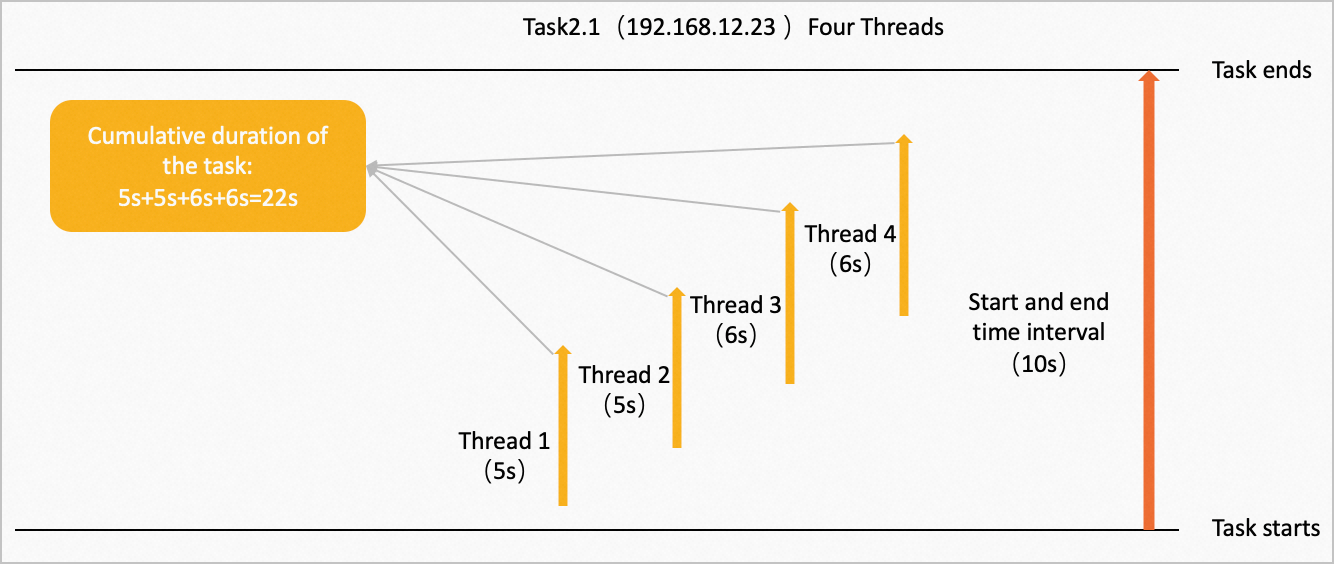
Operator dalam pohon tersebut dieksekusi secara paralel di beberapa node, mengikuti arah panah. Task 2.1 berjalan pada empat thread konkuren di node dengan alamat IP 192.168.12.23. Waktu pemrosesan data untuk Thread 1, Thread 2, Thread 3, dan Thread 4 masing-masing adalah 5 detik, 5 detik, 6 detik, dan 6 detik. Gambar berikut menunjukkan proses tersebut.
-
Cumulative duration task adalah jumlah waktu eksekusi semua thread: 5 detik + 5 detik + 6 detik + 6 detik = 22 detik.
-
Interval antara waktu mulai dan akhir adalah 10 detik.
-
Computing time ratio adalah (cumulative duration / subtask concurrency) / interval antara waktu mulai dan akhir: (22 detik / 4) / 10 detik = 0,55.
API Terkait
|
API |
Deskripsi |
|
Mendapatkan detail eksekusi pernyataan SQL. |
|
|
Mendapatkan detail eksekusi subtask terdistribusi untuk query ID dan stage ID tertentu. |