Airflow adalah alat penjadwalan sumber terbuka populer yang mengatur dan menjadwalkan berbagai beban kerja sebagai grafik asiklik terarah (DAG). Anda dapat menjadwalkan pekerjaan Spark menggunakan Operator Spark Airflow atau alat baris perintah spark-submit. Topik ini menjelaskan cara menggunakan Airflow untuk menjadwalkan pekerjaan Spark AnalyticDB for MySQL.
Prasyarat
Kluster AnalyticDB for MySQL Edisi Perusahaan, Edisi Dasar, atau Edisi Data Lakehouse telah dibuat.
Kelompok sumber daya pekerjaan atau kelompok sumber daya interaktif Spark telah dibuat untuk kluster AnalyticDB for MySQL.
Python 3.7 atau versi yang lebih baru telah diinstal.
Alamat IP server yang menjalankan Airflow telah ditambahkan ke daftar putih kluster AnalyticDB for MySQL.
Jadwalkan pekerjaan Spark SQL
AnalyticDB for MySQL memungkinkan Anda mengeksekusi Spark SQL dalam mode batch atau interaktif. Prosedur penjadwalan berbeda-beda berdasarkan mode eksekusi.
Mode batch
Operator Spark Airflow
Jalankan perintah berikut untuk menginstal plugin Airflow Spark:
pip install https://help-static-aliyun-doc.aliyuncs.com/file-manage-files/zh-CN/20230608/qvjf/adb_spark_airflow-0.0.1-py3-none-any.whlBuat koneksi. Contoh:
{ "auth_type": "AK", "access_key_id": "<your_access_key_ID>", "access_key_secret": "<your_access_key_secret>", "region": "<your_region>" }Tabel berikut menjelaskan parameter tersebut.
Parameter
Deskripsi
auth_type
Metode autentikasi. Tetapkan nilainya ke AK, yang menentukan bahwa pasangan AccessKey digunakan untuk autentikasi.
access_key_id
ID AccessKey akun Alibaba Cloud Anda atau pengguna Resource Access Management (RAM) yang memiliki izin akses ke AnalyticDB for MySQL.
Untuk informasi tentang cara mendapatkan ID AccessKey dan Rahasia AccessKey, lihat Akun dan izin.
access_key_secret
Rahasia AccessKey akun Alibaba Cloud Anda atau pengguna RAM yang memiliki izin akses ke AnalyticDB for MySQL.
Untuk informasi tentang cara mendapatkan ID AccessKey dan Rahasia AccessKey, lihat Akun dan izin.
region
ID wilayah kluster AnalyticDB for MySQL.
Buat file deklarasi DAG Airflow. Dalam contoh ini, file bernama
spark_dags.pydibuat.from datetime import datetime from airflow.models.dag import DAG from airflow_alibaba.providers.alibaba.cloud.operators.analyticdb_spark import AnalyticDBSparkSQLOperator with DAG( dag_id="my_dag_name", default_args={"cluster_id": "<your_cluster_ID>", "rg_name": "<your_resource_group>", "region": "<your_region>"}, ) as dag: spark_sql = AnalyticDBSparkSQLOperator( task_id="task2", sql="SHOW DATABASES;" ) spark_sqlTabel berikut menjelaskan parameter tersebut.
Parameter konfigurasi DAG
Parameter
Wajib
Deskripsi
dag_id
Ya
Nama DAG. Anda dapat memasukkan nama kustom.
default_args
Ya
cluster_id: ID kluster AnalyticDB for MySQL.
rg_name: nama kelompok sumber daya pekerjaan di kluster AnalyticDB for MySQL.
region: ID wilayah kluster AnalyticDB for MySQL.
Untuk informasi selengkapnya, lihat Parameter DAG.
Parameter konfigurasi AnalyticDBSparkSQLOperator
Parameter
Wajib
Deskripsi
task_id
Ya
ID pekerjaan.
SQL
Ya
Pernyataan SQL Spark.
Untuk informasi selengkapnya, lihat Parameter Airflow.
Simpan file
spark_dags.pydi folder tempat file deklarasi konfigurasi Airflow dags_folder berada.Jalankan DAG tersebut. Untuk informasi selengkapnya, lihat dokumentasi Airflow.
Spark-submit
Anda dapat mengonfigurasi parameter spesifik AnalyticDB for MySQL dalam file konfigurasi AnalyticDB for MySQL Spark conf/spark-defaults.conf atau menggunakan parameter Airflow. Parameter spesifik tersebut meliputi clusterId, regionId, keyId, dan secretId. Untuk informasi selengkapnya, lihat Parameter konfigurasi aplikasi Spark.
Jalankan perintah berikut untuk menginstal plugin Airflow Spark:
pip3 install apache-airflow-providers-apache-sparkPentingAnda harus menginstal Python 3 sebelum menginstal plugin Airflow Spark.
Saat Anda menginstal plugin apache-airflow-providers-apache-spark, PySpark yang dikembangkan oleh komunitas Apache Spark akan diinstal secara otomatis. Jika ingin menguninstall PySpark, jalankan perintah berikut:
pip3 uninstall pyspark
Unduh paket spark-submit dan konfigurasikan parameter tersebut.
Jalankan perintah berikut untuk menambahkan alamat spark-submit ke path Airflow:
export PATH=$PATH:</your/adb/spark/path/bin>PentingSebelum memulai Airflow, Anda harus menambahkan alamat spark-submit ke path Airflow. Jika tidak, sistem mungkin gagal menemukan perintah spark-submit saat menjadwalkan pekerjaan.
Buat file deklarasi DAG Airflow. Dalam contoh ini, file bernama demo.py dibuat.
from airflow.models import DAG from airflow.providers.apache.spark.operators.spark_sql import SparkSqlOperator from airflow.providers.apache.spark.operators.spark_submit import SparkSubmitOperator from airflow.utils.dates import days_ago args = { 'owner': 'Aliyun ADB Spark', } with DAG( dag_id='example_spark_operator', default_args=args, schedule_interval=None, start_date=days_ago(2), tags=['example'], ) as dag: adb_spark_conf = { "spark.driver.resourceSpec": "medium", "spark.executor.resourceSpec": "medium" } # [START howto_operator_spark_submit] submit_job = SparkSubmitOperator( conf=adb_spark_conf, application="oss://<bucket_name>/jar/pi.py", task_id="submit_job", verbose=True ) # [END howto_operator_spark_submit] # [START howto_operator_spark_sql] sql_job = SparkSqlOperator( conn_id="spark_default", sql="SELECT * FROM yourdb.yourtable", conf=",".join([k + "=" + v for k, v in adb_spark_conf.items()]), task_id="sql_job", verbose=True ) # [END howto_operator_spark_sql] submit_job >> sql_jobSimpan file demo.py di folder dags pada direktori instalasi Airflow.
Jalankan DAG tersebut. Untuk informasi selengkapnya, lihat dokumentasi Airflow.
Mode interaktif
Dapatkan titik akhir kelompok sumber daya Spark Interaktif.
Masuk ke Konsol AnalyticDB for MySQL. Di pojok kiri atas konsol, pilih wilayah. Di panel navigasi sebelah kiri, klik Clusters. Temukan kluster yang ingin Anda kelola lalu klik ID kluster tersebut.
Di panel navigasi sebelah kiri, pilih , lalu klik tab Resource Groups .
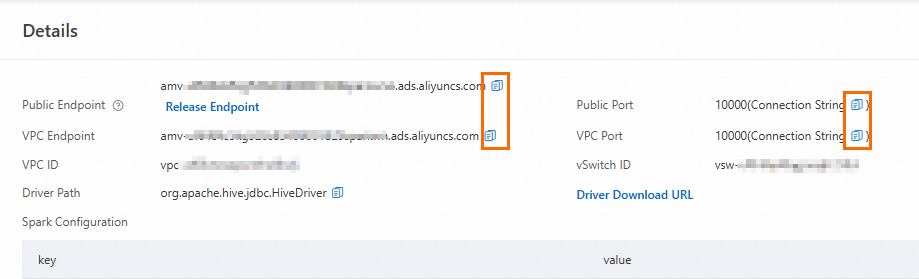
Temukan kelompok sumber daya target lalu klik Details di kolom Actions untuk melihat titik akhir internal dan titik akhir publik. Anda dapat mengklik ikon
 di samping titik akhir untuk menyalinnya. Anda juga dapat mengklik ikon di dalam tanda kurung di samping Port untuk menyalin string koneksi JDBC.
di samping titik akhir untuk menyalinnya. Anda juga dapat mengklik ikon di dalam tanda kurung di samping Port untuk menyalin string koneksi JDBC.Dalam kasus berikut, Anda harus mengklik Request Network di samping Public Endpoint untuk meminta titik akhir publik secara manual.
Alat klien yang digunakan untuk mengirimkan pekerjaan Spark SQL diterapkan di mesin lokal atau server eksternal.
Alat klien yang digunakan untuk mengirimkan pekerjaan Spark SQL diterapkan di instance ECS, dan instance ECS serta kluster AnalyticDB for MySQL tidak berada dalam VPC yang sama.
Instal dependensi apache-airflow-providers-apache-hive dan apache-airflow-providers-common-sql.
Akses antarmuka web Airflow. Di bilah navigasi atas, pilih .
Klik tombol
 . Pada halaman Add Connections, konfigurasikan parameter yang dijelaskan dalam tabel berikut.
. Pada halaman Add Connections, konfigurasikan parameter yang dijelaskan dalam tabel berikut.Parameter
Deskripsi
Connection Id
Nama koneksi. Dalam contoh ini, digunakan
adb_spark_cluster.Connection Type
Pilih Hive Server 2 Thrift.
Host
Titik akhir yang diperoleh pada Langkah 1. Ganti
defaultdalam titik akhir dengan nama database yang sebenarnya dan hapus akhiranresource_group=<resource group name>dari titik akhir tersebut.Contoh:
jdbc:hive2://amv-t4naxpqk****sparkwho.ads.aliyuncs.com:10000/adb_demo.Schema
Nama database. Dalam contoh ini, digunakan
adb_demo.Login
Nama akun database dan kelompok sumber daya interaktif di kluster AnalyticDB for MySQL. Format:
resource_group_name/database_account_name.Contoh:
spark_interactive_prod/spark_user.Password
Kata sandi akun database AnalyticDB for MySQL.
Port
Nomor port untuk kelompok sumber daya interaktif Spark. Tetapkan nilainya ke 10000.
Extra
Metode autentikasi. Masukkan konten berikut, yang menentukan bahwa autentikasi nama pengguna dan kata sandi digunakan:
{ "auth_mechanism": "CUSTOM" }Buat file DAG.
from airflow import DAG from airflow.providers.common.sql.operators.sql import SQLExecuteQueryOperator from datetime import datetime default_args = { 'owner': 'airflow', 'start_date': datetime(2025, 2, 10), 'retries': 1, } dag = DAG( 'adb_spark_sql_test', default_args=default_args, schedule_interval='@daily', ) jdbc_query = SQLExecuteQueryOperator( task_id='execute_spark_sql_query', conn_id='adb_spark_cluster', sql='show databases', dag=dag ) jdbc_queryTabel berikut menjelaskan parameter tersebut.
Parameter
Wajib
Deskripsi
task_id
Ya
ID pekerjaan. Anda dapat memasukkan ID kustom.
conn_id
Ya
Nama koneksi. Masukkan ID koneksi yang Anda buat pada Langkah 4.
sql
Ya
Pernyataan SQL Spark.
Untuk informasi selengkapnya, lihat Parameter Airflow.
Di antarmuka web Airflow, klik tombol
 di samping DAG tersebut.
di samping DAG tersebut.
Jadwalkan pekerjaan Spark JAR
Operator Spark Airflow
Jalankan perintah berikut untuk menginstal plugin Airflow Spark:
pip install https://help-static-aliyun-doc.aliyuncs.com/file-manage-files/zh-CN/20230608/qvjf/adb_spark_airflow-0.0.1-py3-none-any.whlBuat koneksi. Contoh:
{ "auth_type": "AK", "access_key_id": "<your_access_key_ID>", "access_key_secret": "<your_access_key_secret>", "region": "<your_region>" }Tabel berikut menjelaskan parameter tersebut.
Parameter
Deskripsi
auth_type
Metode autentikasi. Tetapkan nilainya ke AK, yang menentukan bahwa pasangan AccessKey digunakan untuk autentikasi.
access_key_id
ID AccessKey akun Alibaba Cloud Anda atau pengguna Resource Access Management (RAM) yang memiliki izin akses ke AnalyticDB for MySQL.
Untuk informasi tentang cara mendapatkan ID AccessKey dan Rahasia AccessKey, lihat Akun dan izin.
access_key_secret
Rahasia AccessKey akun Alibaba Cloud Anda atau pengguna RAM yang memiliki izin akses ke AnalyticDB for MySQL.
Untuk informasi tentang cara mendapatkan ID AccessKey dan Rahasia AccessKey, lihat Akun dan izin.
region
ID wilayah kluster AnalyticDB for MySQL.
Buat file deklarasi DAG Airflow. Dalam contoh ini, file bernama
spark_dags.pydibuat.from datetime import datetime from airflow.models.dag import DAG from airflow_alibaba.providers.alibaba.cloud.operators.analyticdb_spark import AnalyticDBSparkBatchOperator from airflow_alibaba.providers.alibaba.cloud.operators.analyticdb_spark import AnalyticDBSparkSQLOperator with DAG( dag_id=DAG_ID, default_args={"cluster_id": "your cluster", "rg_name": "your resource group", "region": "your region"}, ) as dag: spark_pi = AnalyticDBSparkBatchOperator( task_id="task1", file="local:///tmp/spark-examples.jar", class_name="org.apache.spark.examples.SparkPi", ) spark_lr = AnalyticDBSparkBatchOperator( task_id="task2", file="local:///tmp/spark-examples.jar", class_name="org.apache.spark.examples.SparkLR", ) spark_pi >> spark_lr from tests_common.test_utils.watcher import watcher # This test needs watcher to properly mark success/failure # when "tearDown" task with trigger rule is part of the DAG list(dag.tasks) >> watcher()Parameter konfigurasi DAG
Parameter
Wajib
Deskripsi
dag_id
Ya
Nama DAG. Anda dapat memasukkan nama kustom.
default_args
Ya
cluster_id: ID kluster AnalyticDB for MySQL.
rg_name: nama kelompok sumber daya pekerjaan di kluster AnalyticDB for MySQL.
region: ID wilayah kluster AnalyticDB for MySQL.
Untuk informasi selengkapnya, lihat Parameter DAG.
Parameter konfigurasi AnalyticDBSparkBatchOperator
Parameter
Wajib
Deskripsi
task_id
Ya
ID pekerjaan.
file
Ya
Jalur mutlak file utama aplikasi Spark. File utama dapat berupa paket JAR yang berisi titik masuk atau file yang dapat dieksekusi yang berfungsi sebagai titik masuk untuk aplikasi Python.
PentingFile utama aplikasi Spark harus disimpan di OSS.
Bucket OSS dan kluster AnalyticDB for MySQL harus berada di wilayah yang sama.
class_name
Ya jika kondisi tertentu terpenuhi
Titik masuk aplikasi Java atau Scala.
Aplikasi Python tidak memerlukan titik masuk.
Untuk informasi selengkapnya, lihat Parameter AnalyticDBSparkBatchOperator.
Simpan file
spark_dags.pydi folder tempat file deklarasi konfigurasi Airflow dags_folder berada.Jalankan DAG tersebut. Untuk informasi selengkapnya, lihat dokumentasi Airflow.
Spark-submit
Anda dapat mengonfigurasi parameter spesifik AnalyticDB for MySQL dalam file konfigurasi AnalyticDB for MySQL Spark conf/spark-defaults.conf atau menggunakan parameter Airflow. Parameter spesifik tersebut meliputi clusterId, regionId, keyId, secretId, dan ossUploadPath. Untuk informasi selengkapnya, lihat Parameter konfigurasi aplikasi Spark.
Jalankan perintah berikut untuk menginstal plugin Airflow Spark:
pip3 install apache-airflow-providers-apache-sparkPentingAnda harus menginstal Python 3 sebelum menginstal plugin Airflow Spark.
Saat Anda menginstal plugin apache-airflow-providers-apache-spark, PySpark yang dikembangkan oleh komunitas Apache Spark akan diinstal secara otomatis. Jika ingin menguninstall PySpark, jalankan perintah berikut:
pip3 uninstall pyspark
Unduh paket spark-submit dan konfigurasikan parameter tersebut.
Jalankan perintah berikut untuk menambahkan alamat spark-submit ke path Airflow:
export PATH=$PATH:</your/adb/spark/path/bin>PentingSebelum memulai Airflow, Anda harus menambahkan alamat spark-submit ke path Airflow. Jika tidak, sistem mungkin gagal menemukan perintah spark-submit saat menjadwalkan pekerjaan.
Buat file deklarasi DAG Airflow. Dalam contoh ini, file bernama demo.py dibuat.
from datetime import datetime from airflow.models.dag import DAG from airflow_alibaba.providers.alibaba.cloud.operators.analyticdb_spark import AnalyticDBSparkBatchOperator from airflow_alibaba.providers.alibaba.cloud.operators.analyticdb_spark import AnalyticDBSparkSQLOperator with DAG( dag_id=DAG_ID, start_date=datetime(2021, 1, 1), schedule=None, default_args={"cluster_id": "your cluster", "rg_name": "your resource group", "region": "your region"}, max_active_runs=1, catchup=False, ) as dag: spark_pi = AnalyticDBSparkBatchOperator( task_id="task1", file="local:///tmp/spark-examples.jar", class_name="org.apache.spark.examples.SparkPi", ) spark_lr = AnalyticDBSparkBatchOperator( task_id="task2", file="local:///tmp/spark-examples.jar", class_name="org.apache.spark.examples.SparkLR", ) spark_pi >> spark_lr from tests_common.test_utils.watcher import watcher # This test needs watcher to properly mark success/failure # when "tearDown" task with trigger rule is part of the DAG list(dag.tasks) >> watcher()Tabel berikut menjelaskan parameter tersebut.
Parameter konfigurasi DAG
Parameter
Wajib
Deskripsi
dag_id
Ya
Nama DAG. Anda dapat memasukkan nama kustom.
default_args
Ya
cluster_id: ID kluster AnalyticDB for MySQL.
rg_name: nama kelompok sumber daya pekerjaan di kluster AnalyticDB for MySQL.
region: ID wilayah kluster AnalyticDB for MySQL.
Untuk informasi selengkapnya, lihat Parameter DAG.
Parameter konfigurasi AnalyticDBSparkBatchOperator
Parameter
Wajib
Deskripsi
task_id
Ya
ID pekerjaan.
file
Ya
Jalur mutlak file utama aplikasi Spark. File utama dapat berupa paket JAR yang berisi titik masuk atau file yang dapat dieksekusi yang berfungsi sebagai titik masuk untuk aplikasi Python.
PentingFile utama aplikasi Spark harus disimpan di OSS.
Bucket OSS dan kluster AnalyticDB for MySQL harus berada di wilayah yang sama.
class_name
Ya jika kondisi tertentu terpenuhi
Titik masuk aplikasi Java atau Scala.
Aplikasi Python tidak memerlukan titik masuk.
Untuk informasi selengkapnya, lihat Parameter AnalyticDBSparkBatchOperator.
Simpan file demo.py di folder dags pada direktori instalasi Airflow.
Jalankan DAG tersebut. Untuk informasi selengkapnya, lihat dokumentasi Airflow.