AnalyticDB for MySQL Spark memungkinkan Anda menggunakan gambar Docker untuk memulai lingkungan pengembangan interaktif JupyterLab. Lingkungan ini membantu Anda terhubung ke AnalyticDB for MySQL Spark dan melakukan pengujian serta komputasi interaktif menggunakan sumber daya elastis dari AnalyticDB for MySQL.
Prasyarat
Sebuah kluster AnalyticDB for MySQL Enterprise Edition, Basic Edition, atau Data Lakehouse Edition telah dibuat.
Grup sumber daya pekerjaan telah dibuat untuk kluster AnalyticDB for MySQL.
Akun database telah dibuat untuk kluster AnalyticDB for MySQL.
Jika Anda menggunakan akun Alibaba Cloud, Anda hanya perlu membuat akun istimewa.
Jika Anda menggunakan Pengguna Resource Access Management (RAM), Anda harus membuat akun istimewa dan akun standar dan mengaitkan akun standar dengan pengguna RAM.
Anda telah menyelesaikan otorisasi akun.
Jalur penyimpanan log aplikasi Spark telah dikonfigurasi.
CatatanMasuk ke Konsol AnalyticDB for MySQL. Temukan kluster yang ingin Anda kelola dan klik ID kluster. Di panel navigasi di sebelah kiri, pilih . Klik Log Settings. Di kotak dialog yang muncul, pilih jalur default atau tentukan jalur penyimpanan kustom. Anda tidak dapat mengatur jalur penyimpanan kustom ke direktori root dari OSS. Pastikan bahwa jalur penyimpanan kustom berisi setidaknya satu lapis folder.
Catatan Penggunaan
AnalyticDB for MySQL Spark mendukung pekerjaan Jupyter interaktif hanya dalam Python 3.7 atau Scala 2.12.
Pekerjaan Jupyter interaktif secara otomatis melepaskan sumber daya Spark setelah tidak aktif selama periode waktu tertentu. Waktu pelepasan default adalah 1.200 detik (sumber daya dilepaskan secara otomatis 1.200 detik setelah blok kode terakhir dijalankan). Anda dapat menggunakan perintah berikut di Jupyter Notebook Cell untuk mengonfigurasi parameter
spark.adb.sessionTTLSecondsdan memodifikasi waktu pelepasan otomatis sumber daya Spark.%%configure -f { "spark.adb.sessionTTLSeconds": "3600" }
Terhubung ke AnalyticDB for MySQL Spark
Gunakan JupyterLab dalam AnalyticDB for MySQL gambar yang disediakan untuk terhubung ke Spark
Tarik gambar Jupyter dari AnalyticDB for MySQL. Jalankan perintah berikut:
docker pull registry.cn-hangzhou.aliyuncs.com/adb-public-image/adb-spark-public-image:adb.notebook.0.5.preMulai lingkungan pengembangan interaktif JupyterLab.
Sintaks perintah:
docker run -it -p {Port Host}:8888 -v {Path File Host}:{Path File Docker} registry.cn-hangzhou.aliyuncs.com/adb-public-image/adb-spark-public-image:adb.notebook.0.5.pre -d {ID Instance ADB} -r {Nama Grup Sumber Daya} -e {Endpoint API} -i {ID AK} -k {Rahasia AK} -t {Token Sts} # Pilih salah satu Token Sts atau AKTabel berikut menjelaskan parameter.
Parameter
Diperlukan
Deskripsi
-p
Tidak
Memetakan port host ke port kontainer. Tentukan parameter dalam format
-p {Port Host}:{Port Kontainer}.Tentukan nilai acak untuk port host dan atur port kontainer menjadi
8888. Contoh:-p 8888:8888.-v
Tidak
Jika Anda tidak memasang path host dan menonaktifkan kontainer Docker, file yang sedang diedit mungkin hilang. Setelah Anda menonaktifkan kontainer Docker, kontainer akan mencoba menghentikan semua pekerjaan Spark interaktif yang sedang berjalan. Anda dapat menggunakan salah satu metode berikut untuk mencegah hilangnya file yang sedang diedit:
Saat memulai lingkungan pengembangan interaktif JupyterLab, pasang path host ke kontainer Docker dan simpan file pekerjaan di path file yang sesuai. Tentukan parameter dalam format
-v {Path Host}:{Path File Docker}. Tentukan nilai acak untuk path file kontainer Docker. Nilai yang direkomendasikan:/root/jupyter.Sebelum Anda menonaktifkan kontainer Docker, pastikan semua file telah disalin dan disimpan.
Contoh:
-v /home/admin/notebook:/root/jupyter. Dalam contoh ini, file host yang disimpan di path/home/admin/notebookdipasang ke path/root/jupyterdari kontainer Docker.CatatanSimpan file notebook yang sedang diedit ke folder
/tmp. Setelah Anda menonaktifkan kontainer Docker, Anda dapat melihat file yang sesuai di path/home/admin/notebookdari host. Setelah Anda mengaktifkan kembali kontainer Docker, Anda dapat melanjutkan eksekusi file. Untuk informasi lebih lanjut, lihat Volumes.-d
Ya
ID kluster AnalyticDB for MySQL Enterprise Edition, Basic Edition, atau Data Lakehouse Edition.
Anda dapat masuk ke Konsol AnalyticDB for MySQL dan buka halaman Clusters untuk melihat ID kluster.
-r
Ya
Nama grup sumber daya Job di kluster AnalyticDB for MySQL.
Anda dapat masuk ke Konsol AnalyticDB for MySQL, pilih Cluster Management > Resource Management di panel navigasi di sebelah kiri, dan kemudian klik tab Resource Groups untuk melihat nama grup sumber daya.
-e
Ya
Endpoint kluster AnalyticDB for MySQL.
Untuk informasi lebih lanjut, lihat Endpoint.
-i
Ya (dalam skenario tertentu)
ID AccessKey dan Rahasia AccessKey dari akun Alibaba Cloud atau pengguna RAM Anda.
Untuk informasi tentang cara melihat ID AccessKey dan Rahasia AccessKey, lihat Akun dan izin.
-k
-t
Ya (dalam skenario tertentu)
Token Layanan Keamanan (STS), yaitu kredensial identitas sementara dari peran RAM.
Pengguna RAM dengan izin dapat memanggil operasi API AssumeRole - Dapatkan kredensial identitas sementara dari peran RAM dengan pasangan AccessKey mereka sendiri untuk mendapatkan token STS dari peran RAM dan menggunakan token STS untuk mengakses sumber daya Alibaba Cloud.
Contoh:
docker run -it -p 8888:8888 -v /home/admin/notebook:/root/jupyter registry.cn-hangzhou.aliyuncs.com/adb-public-image/adb-spark-public-image:adb.notebook.0.5.pre -d amv-bp164l******** -r test -e adb.aliyuncs.com -i LTAI**************** -k ****************Setelah Anda memulai lingkungan pengembangan interaktif JupyterLab, informasi berikut dikembalikan. Anda dapat menyalin dan menempelkan URL
http://127.0.0.1:8888/lab?token=1e2caca216c1fd159da607c6360c82213b643605f11ef291ke browser Anda dan gunakan JupyterLab untuk terhubung ke AnalyticDB for MySQL Spark.[I 2023-11-24 09:55:09.852 ServerApp] nbclassic | ekstensi berhasil dimuat. [I 2023-11-24 09:55:09.852 ServerApp] ekstensi sparkmagic diaktifkan! [I 2023-11-24 09:55:09.853 ServerApp] sparkmagic | ekstensi berhasil dimuat. [I 2023-11-24 09:55:09.853 ServerApp] Menyajikan notebook dari direktori lokal: /root/jupyter [I 2023-11-24 09:55:09.853 ServerApp] Jupyter Server 1.24.0 berjalan di: [I 2023-11-24 09:55:09.853 ServerApp] http://419e63fc7821:8888/lab?token=1e2caca216c1fd159da607c6360c82213b643605f11ef291 [I 2023-11-24 09:55:09.853 ServerApp] atau http://127.0.0.1:8888/lab?token=1e2caca216c1fd159da607c6360c82213b643605f11ef291 [I 2023-11-24 09:55:09.853 ServerApp] Gunakan Control-C untuk menghentikan server ini dan mematikan semua kernel (dua kali untuk melewati konfirmasi).CatatanJika pesan kesalahan muncul saat Anda memulai lingkungan pengembangan interaktif JupyterLab, Anda dapat melihat file
proxy_{timestamp}.loguntuk pemecahan masalah.
Gunakan Jupyter Notebook yang diinstal secara lokal untuk terhubung ke Spark
Instal dan konfigurasikan lingkungan Jupyter Notebook
Instal plugin SparkMagic di Jupyter untuk menjalankan pekerjaan Spark interaktif. Pilih metode yang sesuai berdasarkan versi Jupyter Anda. Contoh berikut adalah untuk JupyterLab 3.x.
PentingSemua langkah opsional harus dilakukan secara ketat tanpa melewatkan atau mengubah urutan. Jika Anda melewatkan langkah apa pun, insinyur yang bertugas tidak akan dapat menganalisis masalah lingkungan melalui log startup Jupyter, dan Anda harus menyelesaikan kesalahan sendiri.
Instal SparkMagic.
pip install sparkmagicInstal ipywidgets.
pip install ipywidgets(Opsional) Instal kernel pembungkus. Jalankan
pip show sparkmagic, yang akan menampilkan path instalasi sparkmagic. Beralihlah ke direktori tersebut dan jalankan:jupyter-kernelspec install sparkmagic/kernels/sparkkernel jupyter-kernelspec install sparkmagic/kernels/pysparkkernel jupyter-kernelspec install sparkmagic/kernels/sparkrkernel(Opsional) Modifikasi file konfigurasi
config.jsonSparkMagic (path default adalah~/.sparkmagic/config.json), mengubah127.0.0.1:5000menjadi IP dan port yang ingin Anda dengarkan. Berikut adalah contoh struktur konfigurasi sebagian. Untuk detail lebih lanjut, lihat contoh terkait."kernel_python_credentials": { "username": "", "password": "", "url": "http://127.0.0.1:5000", "auth": "None" }, "kernel_scala_credentials": { "username": "", "password": "", "url": "http://127.0.0.1:5000", "auth": "None" }, "kernel_r_credentials": { "username": "", "password": "", "url": "http://127.0.0.1:5000" },(Opsional) Aktifkan ekstensi server untuk mengubah kluster melalui kode.
jupyter server extension enable --py sparkmagic
Mulai AnalyticDB for MySQL proxy
Anda dapat menggunakan salah satu metode berikut untuk memulai proxy AnalyticDB for MySQL.
Metode 1: Mulai proxy menggunakan Docker
Tarik gambar Jupyter dari AnalyticDB for MySQL. Jalankan perintah berikut:
docker pull registry.cn-hangzhou.aliyuncs.com/adb-public-image/adb-spark-public-image:adb.notebook.0.5.preMulai proxy Docker. Eksekusi perintah berikut untuk memulai kontainer dan mendengarkan di port lokal 5000.
docker run -it -p 5000:5000 -v {Path File Host}:{Path File Docker} registry.cn-hangzhou.aliyuncs.com/adb-public-image/adb-spark-public-image:adb.notebook.0.5.pre -d {ID Instance ADB} -r {Nama Grup Sumber Daya} -e {Endpoint API} -i {ID AK} -k {Rahasia AK} -t {Token Sts} # Pilih salah satu Token Sts atau AKTabel berikut menjelaskan parameter.
Parameter
Diperlukan
Deskripsi
-p
Tidak
Memetakan port host ke port kontainer. Tentukan parameter dalam format
-p {Port Host}:{Port Kontainer}.Tentukan nilai acak untuk port host dan atur port kontainer menjadi
5000. Contoh:-p 5000:5000.-v
Tidak
Jika Anda tidak memasang path host dan menonaktifkan kontainer Docker, file yang sedang diedit mungkin hilang. Setelah Anda menonaktifkan kontainer Docker, kontainer akan mencoba menghentikan semua pekerjaan Spark interaktif yang sedang berjalan. Anda dapat menggunakan salah satu metode berikut untuk mencegah hilangnya file yang sedang diedit:
Saat memulai lingkungan pengembangan interaktif JupyterLab, pasang path host ke kontainer Docker dan simpan file pekerjaan di path file yang sesuai. Tentukan parameter dalam format
-v {Path Host}:{Path File Docker}. Tentukan nilai acak untuk path file kontainer Docker. Nilai yang direkomendasikan:/root/jupyter.Sebelum Anda menonaktifkan kontainer Docker, pastikan semua file telah disalin dan disimpan.
Contoh:
-v /home/admin/notebook:/root/jupyter. Dalam contoh ini, file host yang disimpan di path/home/admin/notebookdipasang ke path/root/jupyterdari kontainer Docker.CatatanSimpan file notebook yang sedang diedit ke folder
/tmp. Setelah Anda menonaktifkan kontainer Docker, Anda dapat melihat file yang sesuai di path/home/admin/notebookdari host. Setelah Anda mengaktifkan kembali kontainer Docker, Anda dapat melanjutkan eksekusi file. Untuk informasi lebih lanjut, lihat Volumes.-d
Ya
ID kluster AnalyticDB for MySQL Enterprise Edition, Basic Edition, atau Data Lakehouse Edition.
Anda dapat masuk ke Konsol AnalyticDB for MySQL dan buka halaman Clusters untuk melihat ID kluster.
-r
Ya
Nama grup sumber daya Job di kluster AnalyticDB for MySQL.
Anda dapat masuk ke Konsol AnalyticDB for MySQL, pilih Cluster Management > Resource Management di panel navigasi di sebelah kiri, dan kemudian klik tab Resource Groups untuk melihat nama grup sumber daya.
-e
Ya
Endpoint kluster AnalyticDB for MySQL.
Untuk informasi lebih lanjut, lihat Endpoint.
-i
Ya (dalam skenario tertentu)
ID AccessKey dan Rahasia AccessKey dari akun Alibaba Cloud atau pengguna RAM Anda.
Untuk informasi tentang cara melihat ID AccessKey dan Rahasia AccessKey, lihat Akun dan izin.
-k
-t
Ya (dalam skenario tertentu)
Token Layanan Keamanan (STS), yaitu kredensial identitas sementara dari peran RAM.
Pengguna RAM dengan izin dapat memanggil operasi API AssumeRole - Dapatkan kredensial identitas sementara dari peran RAM dengan pasangan AccessKey mereka sendiri untuk mendapatkan token STS dari peran RAM dan menggunakan token STS untuk mengakses sumber daya Alibaba Cloud.
Metode 2: Instal proxy menggunakan baris perintah
Unduh dan instal proxy
pip install aliyun-adb-livy-proxy-0.0.1.zipEksekusi perintah berikut untuk memulai proxy.
CatatanSetelah proxy AnalyticDB for MySQL berhasil diinstal, Anda dapat menjalankan
adbproxy --helpuntuk melihat daftar parameter.adbproxy --db {ID Instance ADB} --rg {Nama Grup Sumber Daya} --endpoint {Endpoint API} --host 127.0.0.1 --port 5000 -i {ID AK} -k {Rahasia AK} -t {Token Sts} # Pilih salah satu Token Sts atau AKTabel berikut menjelaskan parameter.
Parameter
Diperlukan
Deskripsi
--db
Ya
ID kluster AnalyticDB for MySQL Enterprise Edition, Basic Edition, atau Data Lakehouse Edition.
Anda dapat masuk ke Konsol AnalyticDB for MySQL dan buka halaman Clusters untuk melihat ID kluster.
--rg
Ya
Nama grup sumber daya Job di kluster AnalyticDB for MySQL.
Anda dapat masuk ke Konsol AnalyticDB for MySQL, pilih Cluster Management > Resource Management di panel navigasi di sebelah kiri, dan kemudian klik tab Resource Groups untuk melihat nama grup sumber daya.
--endpoint
Ya
Endpoint kluster AnalyticDB for MySQL.
Untuk informasi lebih lanjut, lihat Endpoint.
--host
Tidak
Alamat IP lokal tempat layanan adbproxy terikat. Nilai default adalah
127.0.0.1.--port
Tidak
Nomor port tempat layanan adbproxy mendengarkan. Nilai default adalah
5000.-i
Ya (dalam skenario tertentu)
ID AccessKey dan Rahasia AccessKey dari akun Alibaba Cloud atau pengguna RAM dengan AnalyticDB for MySQL izin akses.
Untuk informasi tentang cara mendapatkan ID AccessKey dan Rahasia AccessKey, lihat Akun dan izin.
-k
-t
Ya (dalam skenario tertentu)
Token Layanan Keamanan (STS), yaitu kredensial identitas sementara dari peran RAM.
Pengguna RAM dengan izin dapat memanggil operasi API AssumeRole - Dapatkan kredensial identitas sementara dari peran RAM dengan pasangan AccessKey mereka sendiri untuk mendapatkan token STS dari peran RAM dan menggunakan token STS untuk mengakses sumber daya Alibaba Cloud.
Setelah berhasil dimulai, konsol akan menampilkan informasi log terkait.
Mulai Jupyter
Gunakan perintah berikut untuk memulai lingkungan pengembangan interaktif Jupyter.
jupyter labJika Anda telah menetapkan alamat mendengarkan kustom, eksekusi jupyter lab --ip=*** untuk memulai Jupyter, di mana *** adalah alamat mendengarkan kustom Anda.
Setelah berhasil dimulai, informasi berikut dikembalikan. Anda dapat menyalin dan menempelkan URL http://127.0.0.1:8888/lab?token=1e2caca216c1fd159da607c6360c82213b643605f11ef291 ke browser Anda untuk menggunakan Jupyter terhubung ke AnalyticDB for MySQL Spark.
[I 2025-07-02 17:36:16.051 ServerApp] Menyajikan notebook dari direktori lokal: /home/newuser
[I 2025-07-02 17:36:16.052 ServerApp] Jupyter Server 2.16.0 berjalan di:
[I 2025-07-02 17:36:16.052 ServerApp] http://419e63fc7821:8888/lab?token=1e2caca216c1fd159da607c6360c82213b643605f11ef291
[I 2025-07-02 17:36:16.052 ServerApp] http://127.0.0.1:8888/lab?token=1e2caca216c1fd159da607c6360c82213b643605f11ef291
[I 2025-07-02 17:36:16.052 ServerApp] Gunakan Control-C untuk menghentikan server ini dan mematikan semua kernel (dua kali untuk melewati konfirmasi).Jalankan pekerjaan di Jupyter
Mulai sumber daya dan tentukan penggunaan ACU maksimum untuk pekerjaan
Setelah terhubung ke AnalyticDB for MySQL Spark menggunakan Jupyter, klik PySpark pada halaman untuk membuat pekerjaan PySpark baru. Pekerjaan Spark akan berjalan dengan parameter konfigurasi default berikut:
{ "kind": "pyspark", "heartbeatTimeoutInSecond": "60", "spark.driver.resourceSpec": "medium", "spark.executor.resourceSpec": "medium", "spark.executor.instances": "1", "spark.dynamicAllocation.shuffleTracking.enabled": "true", "spark.dynamicAllocation.enabled": "true", "spark.dynamicAllocation.minExecutors": "0", "spark.dynamicAllocation.maxExecutors": "1", "spark.adb.sessionTTLSeconds": "1200" }Untuk memodifikasi parameter konfigurasi aplikasi Spark, Anda dapat menggunakan pernyataan
%%configure -f.Mulai ulang kernel.
Di bilah navigasi atas, pilih . Pastikan tidak ada aplikasi Spark yang sedang berjalan yang ditampilkan di halaman pengembangan Jupyter.
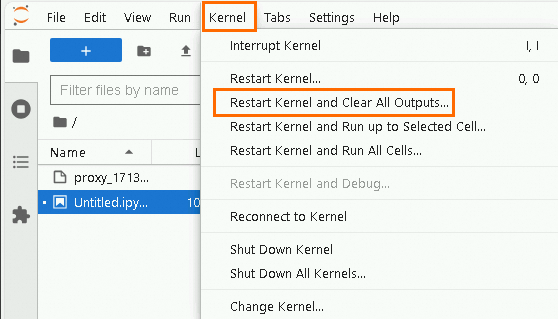
Masukkan parameter konfigurasi aplikasi Spark kustom di Jupyter Notebook Cell.
PentingSaat menentukan parameter konfigurasi aplikasi Spark kustom, Anda harus mengatur parameter spark.dynamicAllocation.enabled menjadi false.
Contoh:
Konfigurasi ini mengalokasikan 32 Executor untuk pekerjaan Spark, dengan setiap Executor memiliki spesifikasi
medium(2 core dan 8 GB memori). Seluruh pekerjaan dapat mengalokasikan total 64 ACU sumber daya komputasi.%%configure -f { "spark.driver.resourceSpec":"large", "spark.sql.hive.metastore.version":"adb", "spark.executor.resourceSpec":"medium", "spark.adb.executorDiskSize":"100Gi", "spark.executor.instances":"32", "spark.dynamicAllocation.enabled":"false", "spark.network.timeout":"30000", "spark.memory.fraction":"0.75", "spark.memory.storageFraction":"0.3" }Untuk informasi lebih lanjut tentang parameter konfigurasi aplikasi Spark, lihat Parameter konfigurasi aplikasi Spark dan Situs resmi Spark.
Klik tombol
 untuk memodifikasi parameter konfigurasi aplikasi Spark.Penting
untuk memodifikasi parameter konfigurasi aplikasi Spark.PentingSetelah Anda menutup halaman Jupyter Notebook, parameter konfigurasi kustom yang ditentukan tidak lagi berlaku. Jika Anda tidak menentukan parameter aplikasi Spark setelah membuka kembali halaman Jupyter Notebook, parameter konfigurasi default digunakan untuk menjalankan pekerjaan Spark.
Saat menjalankan pekerjaan Spark di halaman Jupyter Notebook, semua konfigurasi pekerjaan ditulis langsung ke struktur JSON, bukan objek
confdari struktur JSON yang diperlukan saat Anda mengirim pekerjaan batch.
Jalankan pekerjaan
Masukkan perintah
sparkuntuk memulai SparkSession. Catatan
CatatanKlik Link di nilai pengembalian untuk mengakses antarmuka UI Spark dan melihat informasi seperti log pekerjaan Spark.
Jalankan Spark SQL di Jupyter Notebook Cell untuk menanyakan daftar database yang tersedia di kluster AnalyticDB for MySQL.
PentingAnda harus menambahkan
%%sqlsebelum menjalankan kode Spark SQL, jika tidak akan diurai sebagai kode Python secara default. Anda dapat menjalankan%%helpuntuk mempelajari lebih lanjut tentang perintah Magic dan penggunaannya.%%sql show databases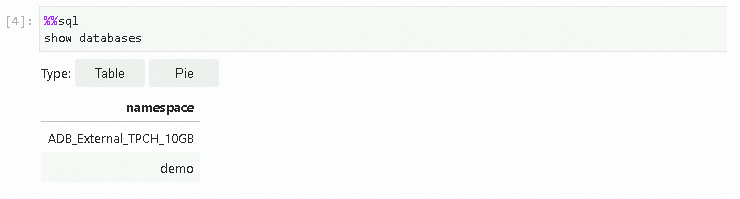 Hasil kueri sesuai dengan yang ada di AnalyticDB for MySQL.
Hasil kueri sesuai dengan yang ada di AnalyticDB for MySQL.