Topik ini menjelaskan cara mengoptimalkan kueri pengelompokan dan agregasi di AnalyticDB for MySQL.
Proses pengelompokan dan agregasi
AnalyticDB for MySQL merupakan layanan gudang data terdistribusi. Secara default, AnalyticDB for MySQL menjalankan kueri pengelompokan dan agregasi melalui langkah-langkah berikut:
-
Melakukan agregasi parsial pada data.
Node agregasi parsial hanya menggunakan sedikit memori. Proses agregasi bersifat berbasis aliran sehingga mencegah penumpukan data pada node agregasi parsial.
-
Setelah agregasi parsial selesai, mendistribusikan ulang data di antara node berdasarkan field GROUP BY, lalu melakukan agregasi akhir.
Hasil agregasi parsial ditransmisikan melalui jaringan ke node tahap hilir. Untuk informasi selengkapnya, lihat Factors that affect query performance. Agregasi parsial mengurangi jumlah data yang perlu ditransmisikan melalui jaringan, sehingga tekanan jaringan berkurang. Setelah data didistribusikan ulang, agregasi akhir dilakukan. Pada node agregasi akhir, nilai dan status agregasi dari suatu grup dipertahankan dalam memori hingga semua data selesai diproses. Ini memastikan bahwa tidak ada data baru yang perlu diproses untuk nilai grup tertentu. Oleh karena itu, node agregasi akhir dapat menggunakan memori dalam jumlah besar.
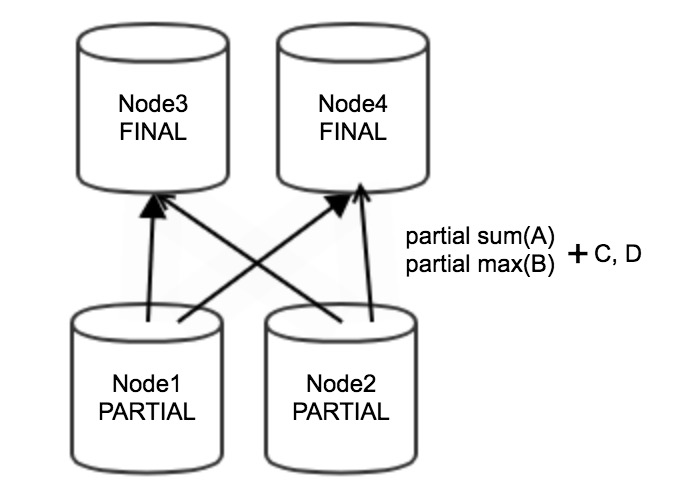
Sebagai contoh, jalankan pernyataan SQL berikut untuk melakukan pengelompokan dan agregasi:
SELECT sum(A), max(B) FROM tb1 GROUP BY C,D;Ketika pernyataan di atas dieksekusi untuk melakukan pengelompokan dan agregasi, agregasi parsial pertama kali dilakukan pada Node 1 dan Node 2 tahap hulu. Hasil agregasi parsial berupa partial sum(A), partial max(B), C, dan D. Hasil agregasi parsial ditransmisikan melalui jaringan ke Node 3 dan Node 4 tahap hilir untuk agregasi akhir, seperti yang ditunjukkan pada gambar berikut.
Gunakan hint untuk mengoptimalkan pengelompokan dan agregasi
-
Skenario
Pada sebagian besar skenario, agregasi dua langkah mencapai keseimbangan yang baik antara resource memori dan jaringan. Namun, pada skenario khusus yang melibatkan sejumlah besar nilai unik dalam field GROUP BY, agregasi dua langkah mungkin bukan pilihan terbaik.
Sebagai contoh, Anda ingin mengelompokkan data berdasarkan nomor ponsel atau user ID. Jika Anda menggunakan metode agregasi dua langkah, hanya sedikit data yang dapat diagregasi, sementara langkah agregasi parsial tetap melakukan beberapa operasi seperti menghitung nilai hash grup, deduplikasi, dan menjalankan fungsi agregasi. Pada contoh ini, sejumlah besar grup terlibat. Akibatnya, langkah agregasi parsial tidak mengurangi jumlah data yang perlu ditransmisikan melalui jaringan, tetapi mengonsumsi resource komputasi dalam jumlah besar.
-
Solusi
Untuk mengatasi masalah laju agregasi rendah tersebut, Anda dapat menambahkan hint
/*+ aggregation_path_type=single_agg*/untuk melewati agregasi parsial dan langsung melakukan agregasi akhir ketika mengeksekusi kueri. Ini mengurangi overhead komputasi yang tidak perlu.CatatanJika hint
/*+ aggregation_path_type=single_agg*/digunakan dalam pernyataan SQL, semua kueri pengelompokan dan agregasi dalam pernyataan SQL tersebut menggunakan proses optimasi yang ditentukan. Kami merekomendasikan untuk menganalisis karakteristik operator agregasi dalam rencana eksekusi asli, mengevaluasi manfaat hint, lalu menentukan apakah akan menggunakan skema optimasi ini. -
Deskripsi optimasi
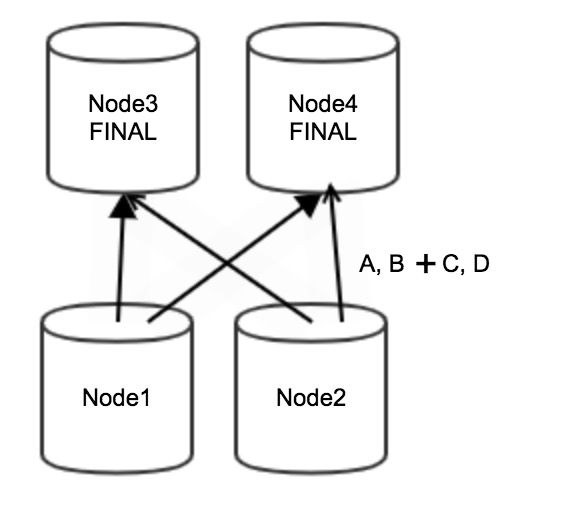
Jika laju agregasi rendah, agregasi parsial yang dilakukan pada Node 1 dan Node 2 tahap hulu tidak mengurangi jumlah data yang perlu ditransmisikan melalui jaringan, tetapi mengonsumsi resource komputasi dalam jumlah besar.
Setelah optimasi, agregasi parsial tidak dilakukan pada Node 1 dan Node 2. Semua data (A, B, C, dan D) langsung diagregasi pada Node 3 dan Node 4 tahap hilir sehingga mengurangi resource komputasi yang diperlukan, seperti yang ditunjukkan pada gambar berikut.
 Catatan
CatatanOptimasi ini mungkin tidak mengoptimalkan penggunaan memori. Jika laju agregasi rendah, sejumlah besar data terakumulasi dalam memori untuk deduplikasi dan agregasi guna memastikan bahwa semua data untuk nilai grup tertentu diproses.