AnalyticDB for MySQL menyediakan fitur pencarian vektor untuk membantu Anda mengimplementasikan pencarian kesamaan pada data tidak terstruktur. Topik ini menjelaskan fitur pencarian vektor serta cara membuat dan menggunakan indeks vektor.
Prasyarat
Sebuah kluster AnalyticDB for MySQL versi V3.1.4.0 atau lebih baru telah dibuat.
Untuk menggunakan fitur pencarian vektor, direkomendasikan menggunakan versi minor berikut: 3.1.5.16, 3.1.6.8, 3.1.8.6, atau yang lebih baru.
Jika kluster Anda bukan salah satu dari versi di atas, disarankan untuk mengatur parameter CSTORE_PROJECT_PUSH_DOWN dan CSTORE_PPD_TOP_N_ENABLE ke false sebelum menggunakan fitur pencarian vektor.
Untuk informasi tentang cara memeriksa versi minor dari kluster AnalyticDB for MySQL, lihat Bagaimana cara memeriksa versi dari kluster AnalyticDB for MySQL? Untuk memperbarui versi minor kluster, hubungi dukungan teknis.
Informasi Latar Belakang
Ikhtisar
Anda dapat menggunakan algoritma AI untuk mengekstraksi fitur dari data tidak terstruktur, mengkodekan fitur menjadi vektor fitur, lalu menyimpan vektor fitur tersebut di dalam AnalyticDB for MySQL. Saat menggunakan vektor fitur untuk mengidentifikasi data tidak terstruktur, jarak antara vektor dapat digunakan untuk mengukur kesamaan antara data tidak terstruktur yang berbeda. AnalyticDB for MySQL menyediakan fitur pencarian vektor yang efisien untuk skenario seperti pencarian berbasis gambar, pencocokan suara, pengenalan wajah, dan pencarian teks.
Arsitektur
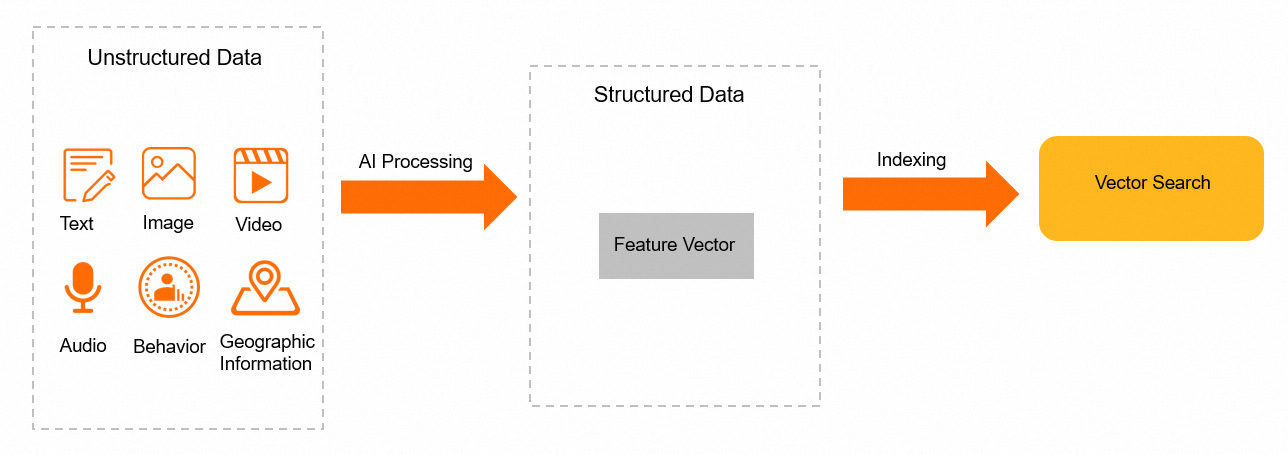
Manfaat
Dimensi tinggi, performa tinggi, dan recall tinggi untuk data vektor
Dalam contoh ini, sebuah vektor 512-dimensi yang mewakili wajah manusia digunakan. AnalyticDB for MySQL dapat memberikan recall 99% untuk 10 miliar entri data vektor dalam skenario yang membutuhkan 100 permintaan per detik (QPS) dengan waktu respons 50 milidetik atau untuk 0,2 miliar entri data vektor dalam skenario yang membutuhkan 1.000 QPS dengan waktu respons 1 detik.
Kueri terintegrasi untuk data terstruktur dan tidak terstruktur
AnalyticDB for MySQL mendukung kueri terintegrasi dengan menggunakan algoritma tetangga terdekat k (KNN) dan radius tetangga terdekat (RNN). Sebagai contoh, Anda dapat membandingkan kesamaan antara dua set vektor.
Pembaruan real-time
AnalyticDB for MySQL mendukung penulisan dan pembaruan real-time dengan konkurensi tinggi. Anda dapat melakukan kueri data segera setelah data ditulis.
Pencarian real-time
AnalyticDB for MySQL menggunakan arsitektur pemrosesan paralel masif (MPP) untuk menyediakan pencarian data dalam hitungan milidetik dan meningkatkan efisiensi pencarian.
Kemudahan penggunaan
AnalyticDB for MySQL mendukung Pernyataan SQL standar untuk menyederhanakan proses pengembangan tanpa memerlukan konfigurasi tambahan yang kompleks.
Istilah
Membuat Indeks Vektor
Sintaksis
Anda dapat membuat indeks vektor saat membuat tabel dengan menggunakan sintaksis berikut:
ANN INDEX [index_name] (column_name)] [algorithm=HNSW_PQ ] [distancemeasure=SquaredL2]Parameter
ANN INDEX: kata kunci indeks vektor.
index_name: nama indeks. Untuk informasi tentang konvensi penamaan indeks, lihat bagian "Batasan Penamaan" dari topik Batasan.
column_name: nama kolom vektor. Untuk informasi tentang konvensi penamaan kolom, lihat bagian "Batasan Penamaan" dari topik Batasan. Hanya tipe data berikut yang didukung:
ARRAY<FLOAT>,ARRAY<BYTE>, danARRAY<SMALLINT>.algorithm: algoritma yang digunakan untuk menghitung jarak vektor. Atur nilainya ke
HNSW_PQ.distancemeasure: rumus yang digunakan untuk menghitung jarak vektor. Atur nilainya ke
SquaredL2. Rumus perhitunganSquaredL2:(x1 - y1)<sup>2</sup> + (x2 - y2)<sup>2</sup> + ...(xn - yn)<sup>2</sup>.
Contoh
Dalam contoh ini, tabel bernama vector dibuat. Tabel tersebut berisi dua kolom vektor: float_feature dan short_feature. Kolom float_feature bertipe ARRAY<FLOAT> dan berisi data berdimensi empat. Kolom short_feature bertipe ARRAY<SMALLINT> dan berisi data berdimensi empat. Saat tabel dibuat, indeks vektor dibuat pada kedua kolom tersebut.
CREATE TABLE vector (
xid bigint not null,
cid bigint not null,
uid varchar not null,
vid varchar not null,
wid varchar not null,
float_feature array < float >(4),
short_feature array < smallint >(4),
ANN INDEX idx_short_feature(short_feature),
ANN INDEX idx_float_feature(float_feature),
PRIMARY KEY (xid, cid, vid)
) DISTRIBUTED BY HASH(xid);Menambahkan Indeks Vektor
Sintaksis
Anda dapat menambahkan indeks vektor setelah membuat tabel dengan menggunakan sintaksis berikut:
ALTER TABLE table_name ADD ANN INDEX [index_name] (column_name) [algorithm=HNSW_PQ ] [distancemeasure=SquaredL2]Contoh
Tabel vector dibuat dengan menjalankan pernyataan berikut:
CREATE TABLE vector (
xid BIGINT not null,
cid BIGINT not null,
uid VARCHAR not null,
vid VARCHAR not null,
wid VARCHAR not null,
float_feature array < FLOAT >(4),
short_feature array < SMALLINT >(4),
PRIMARY KEY (xid, cid, vid)
) DISTRIBUTED BY HASH(xid);Buat indeks vektor untuk kolom float_feature dan short_feature dalam tabel vektor.
ALTER TABLE vector ADD ANN INDEX idx_float_feature(float_feature);
ALTER TABLE vector ADD ANN INDEX idx_short_feature(short_feature);Kueri Data Vektor
Anda dapat menambahkan fungsi perhitungan jarak ke dalam pernyataan SELECT untuk mengabstraksi hubungan antar entitas menjadi jarak antar vektor dalam ruang vektor. Contoh: L2_DISTANCE.
Contoh
Masukkan Data
Masukkan data ke dalam tabel vector.
INSERT into vector (xid,cid,uid,vid,wid,short_feature,float_feature) VALUES (1,2,'A','B','C','[1,1,1,1]','[1.2,1.5,2,3.0]');
INSERT into vector (xid,cid,uid,vid,wid,short_feature,float_feature) VALUES (2,1,'e','v','f','[2,2,2,2]','[1.5,1.15,2.2,2.7]');
INSERT into vector (xid,cid,uid,vid,wid,short_feature,float_feature) VALUES (0,6,'d','f','g','[3,3,3,3]','[0.2,1.6,5,3.7]');
INSERT into vector (xid,cid,uid,vid,wid,short_feature,float_feature) VALUES (5,4,'j','b','h','[4,4,4,4]','[1.0,4.15,6,2.9]');
INSERT into vector (xid,cid,uid,vid,wid,short_feature,float_feature) VALUES (8,5,'Sj','Hb','Dh','[5,5,5,5]','[1.3,4.5,6.9,5.2]');
INSERT into vector (xid,cid,uid,vid,wid,short_feature,float_feature) VALUES (5,4,'x','g','h','[3,4,4,4]','[1.0,4.15,6,2.9]');
INSERT into vector (xid,cid,uid,vid,wid,short_feature,float_feature) VALUES (5,4,'j','r','k','[6,6,4,4]','[1.0,4.15,6,2.9]');
INSERT into vector (xid,cid,uid,vid,wid,short_feature,float_feature) VALUES (5,4,'s','i','q','[2,2,4,4]','[1.0,4.15,6,2.9]');Kueri Data
Kueri tiga entri teratas di kolom short_feature yang memiliki jarak terpendek ke vektor
'[1,1,1,1]'.SELECT xid, l2_distance(short_feature, '[1,1,1,1]') as dis FROM vector ORDER BY 2 LIMIT 3;Hasil sampel:
+-------+--------------+ | xid | dis | +-------+--------------+ | 1 | 0.0 | +-------+--------------+ | 2 | 4.0 | +-------+--------------+ | 0 | 16.0 | +-------+--------------+Kueri empat entri teratas di kolom short_feature yang memiliki jarak terpendek ke vektor
'[1,1,1,1]'ketika xid adalah 5 dan cid adalah 4.SELECT uid, l2_distance(short_feature, '[1,1,1,1]') as dis FROM vector WHERE xid = 5 AND cid = 4 ORDER BY 2 LIMIT 4;Hasil sampel:
+-------+--------------+ | uid | dis | +-------+--------------+ | s | 20.0 | +-------+--------------+ | x | 31.0 | +-------+--------------+ | j | 36.0 | +-------+--------------+ | j | 68.0 | +-------+--------------+Kueri tiga entri teratas di kolom short_feature yang memiliki jarak terpendek ke vektor
'[1,1,1,1]'ketika jaraknya kurang dari atau sama dengan 50 dan xid adalah 5.SELECT uid, l2_distance(short_feature, '[1,1,1,1]') as dis FROM vector WHERE l2_distance(short_feature, '[1,1,1,1]') < 50.0 AND xid = 5 ORDER BY 2 LIMIT 3;Hasil sampel:
+-------+---------------+ | uid | dis | +-------+---------------+ | s | 20.0 | +-------+---------------+ | x | 31.0 | +-------+---------------+ | j | 36.0 | +-------+---------------+