Kerangka algoritma EasyRec melibatkan tiga konsep utama: bidang data, bidang fitur, dan Feature Generator (FG) fitur. Topik ini menjelaskan konsep-konsep tersebut serta perbedaan di antara mereka.
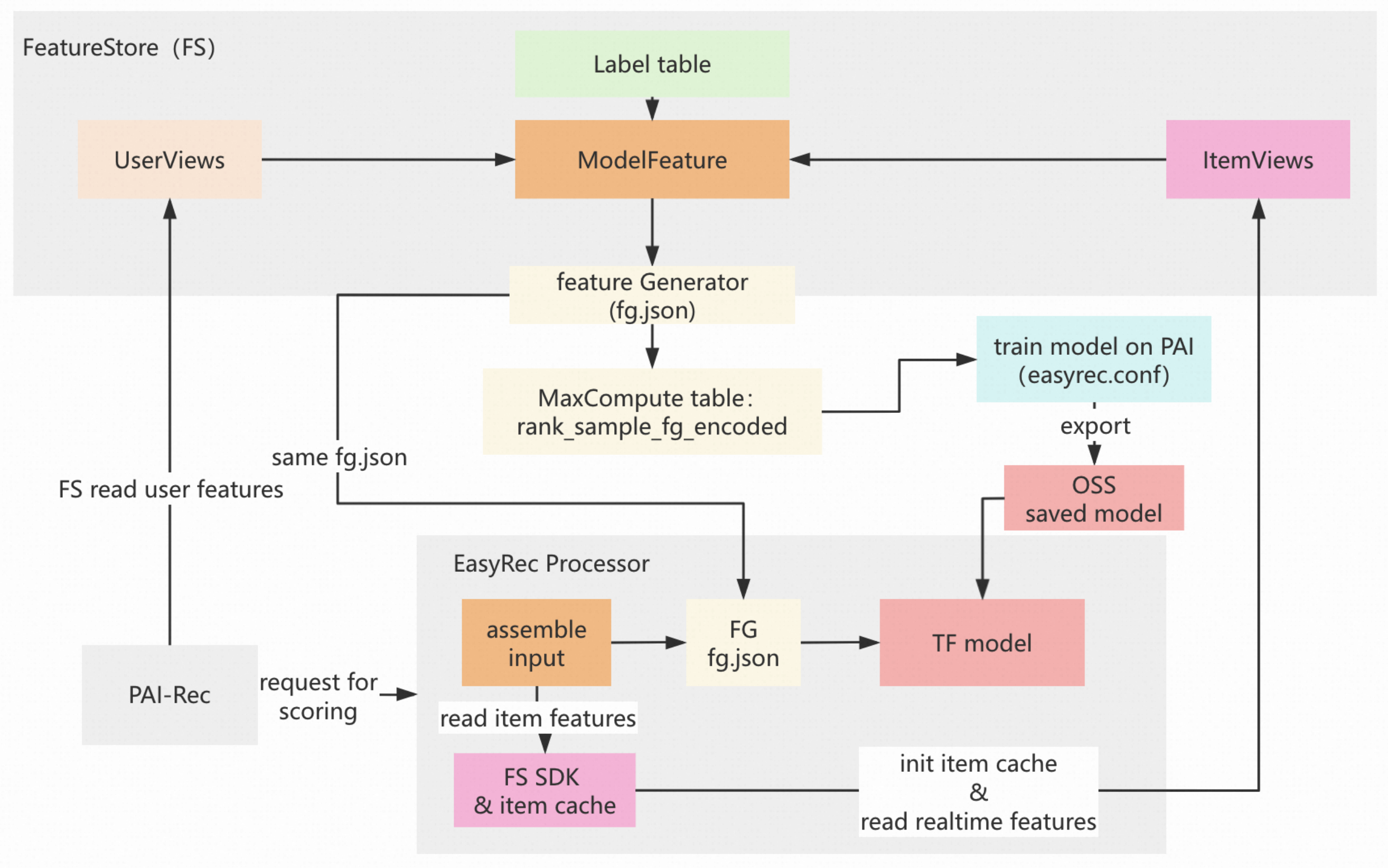
Peran FG dalam pelatihan offline dan inferensi online EasyRec
Istilah
FeatureStore: FeatureStore adalah alat manajemen fitur yang disediakan oleh Platform for AI (PAI). Anda dapat menggunakan alat ini untuk menyimpan dan mengelola fitur dalam sistem offline dan online. Untuk informasi lebih lanjut, lihat Ikhtisar FeatureStore.
FG: FG dirancang untuk memastikan konsistensi antara pemrosesan fitur offline dan online. FG dapat menghasilkan fitur berikut: fitur ID, fitur mentah, fitur kombinasi, fitur pencarian, fitur kecocokan, fitur urutan, dan fitur tumpang tindih. Fitur pencarian dan fitur urutan sering digunakan. Untuk informasi lebih lanjut, lihat RTP FG.
Fitur pengguna: Fitur pengguna yang ditunjukkan pada gambar di atas mencakup yang diperoleh dari sistem offline dan online. Di pojok kiri bawah gambar di atas, mesin PAI-Rec membaca fitur pengguna dengan menggunakan SDK FeatureStore.
Fitur item: Layanan penilaian EasyRec processor membaca fitur item dengan menggunakan SDK FeatureStore.
Menggabungkan input: Fitur pengguna dalam permintaan dan fitur item dalam cache digabungkan untuk pembuatan fitur. Setelah pembuatan fitur, fitur yang dihasilkan diimpor ke model TensorFlow untuk penilaian.
EasyRec processor: Ini diterapkan pada Elastic Algorithm Service (EAS) dari PAI dan digunakan untuk menilai model rekomendasi, iklan, dan pencarian. EasyRec processor dapat memuat model pembelajaran mendalam EasyRec dan melakukan optimasi performa.
easyrec.conf: File ini menjelaskan bidang data, jenis fitur, dan struktur jaringan yang digunakan oleh model pembelajaran mendalam EasyRec.
Pipeline
Pipeline offline: FeatureStore menggunakan UserViews (beberapa tampilan fitur sisi pengguna), ItemViews (beberapa tampilan fitur sisi item), dan Label Table (tabel MaxCompute dengan label pelatihan) untuk membangun fitur model (tabel sampel pelatihan). FG (paket MapReduce JAR fg_on_odps-1.3.59-jar-with-dependencies.jar) bekerja dengan file fg.json untuk mentransformasikan fitur model menjadi tabel hasil rank_sample_fg_encoded. Model dilatih di PAI berdasarkan file easyrec.conf, diekspor dan disimpan di Object Storage Service (OSS), lalu diimpor ke model TensorFlow untuk penilaian.
Pipeline online: Mesin PAI-Rec mendapatkan fitur pengguna dan ID item yang akan dinilai (bagian logika ini tidak ditampilkan pada gambar di atas), dan meminta EasyRec processor untuk menggabungkan fitur. Kemudian, EasyRec processor menggunakan FG untuk melakukan transformasi fitur online, menilai ID item, lalu mengembalikan skor.
1. Bidang data dan bidang fitur dalam file konfigurasi EasyRec
1.1. Konfigurasi bidang data: data_config
data_config menentukan nama dan jenis bidang data asli dalam file easyrec.conf, serta metode imputasi nilai yang hilang untuk bidang data ini. Untuk informasi lebih lanjut, lihat Bidang Data di EasyRec. Jenis nilai bidang data mencakup int, double, dan string. Data dapat disimpan dalam berbagai format seperti file CSV, tabel MaxCompute, dan aliran data Kafka.
Contoh: data tipe key-value
Imputasi nilai yang hilang: Nilai yang hilang diimputasi dengan pasangan key-value. Dalam contoh ini, pasangan key-value adalah -1024:0.
Logika untuk pelatihan offline dan prediksi online: Nilai yang hilang diimputasi dalam model TensorFlow.
input_fields: {
input_name: "prop_kv"
input_type: STRING
default_val:"-1024:0"
}1.2. Konfigurasi bidang fitur: feature_config
data_config terutama mendefinisikan bidang data dan label. feature_config menentukan bagaimana bidang data ini diuraikan dan digunakan oleh model. Misalnya, Field x digunakan sebagai fitur tipe STRING. Di feature_config, bidang ini dapat diartikan sebagai fitur ID, fitur tag, atau fitur urutan.
Contoh: fitur ID
features {
input_names: "user_id"
feature_type: IdFeature
embedding_dim: 32
hash_bucket_size: 100000
}Deskripsi: Fitur yang ditunjukkan oleh user_id dipetakan hash ke 100.000 ember. Setiap ID ember dipetakan ke vektor 32-dimensi melalui pelatihan model.
Logika untuk pelatihan offline dan prediksi online: Fitur yang ditunjukkan oleh user_id diubah menjadi vektor 32-dimensi dalam model TensorFlow.
Contoh: fitur mentah
features {
input_names: "ctr"
feature_type: RawFeature
boundaries: [0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0]
embedding_dim: 8
}Prapemrosesan: Algoritma binning PAI digunakan untuk mendapatkan satu set batas. Batas-batas ini kemudian dikonfigurasikan untuk fitur dalam feature_config.
Logika untuk pelatihan offline dan prediksi online: Untuk fitur yang ditunjukkan oleh ctr, batas-batas tersebut dibucket untuk menghasilkan ID bucket, dan ID bucket kemudian dipetakan ke vektor.
Contoh: fitur tag
features : {
input_names: 'tags'
feature_type: TagFeature
separator: '|'
hash_bucket_size: 100000
embedding_dim: 24
}Sebagai contoh, fitur tag artikel adalah Entertainment|Funny|Popular, di mana tanda vertikal (|) digunakan sebagai pemisah.
Logika untuk pelatihan offline dan prediksi online: Embedding hash dilakukan pada fitur tag dalam model TensorFlow untuk menghasilkan vektor embedding. Kemudian, rata-rata pooling dilakukan pada vektor untuk menghasilkan vektor embedding rata-rata.
2. Transformasi fitur Lookup di FG
FG mendukung berbagai kombinasi fitur dan metode transformasi. Berikut adalah contoh transformasi fitur lookup.
{
"map": "user:map_brand_click_kv",
"key":"item:brand",
"feature_name": "map_brand_click_count",
"feature_type":"lookup_feature",
"needDiscrete":false,
}Pemrosesan data offline: Paket fg_on_odps-1.3.59-jar-with-dependencies.jar diperlukan dalam sistem offline. Fitur item brand digunakan sebagai kunci untuk menanyakan nilai fitur pengguna map_brand_click_kv, lalu nilai yang diperoleh digunakan untuk fitur baru map_brand_click_count. Dalam contoh ini, map_brand_click_kv menunjukkan jumlah klik pengguna di bawah merek yang berbeda, dan map_brand_click_count menunjukkan jumlah klik pengguna di bawah merek item saat ini.
Prediksi online: EasyRec processor menggunakan FG untuk menghitung nilai map_brand_click_count lalu mengirim nilai tersebut ke model TensorFlow untuk prediksi.
3. FAQ
3.1. Dari mana batas-batas berasal dan apa artinya?
Dalam contoh berikut dari file konfigurasi EasyRec, konfigurasi untuk fitur yang ditunjukkan oleh CTR berisi parameter boundaries.
feature_configs: {
input_names: "CTR"
feature_type: RawFeature
boundaries: [0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0]
embedding_dim: 8
}Nilai parameter boundaries diperoleh dengan menggunakan komponen Binning dari PAI.
Dalam model TensorFlow, ketika komponen Binning melakukan diskretisasi pada fitur yang ditunjukkan oleh CTR, batas-batas tersebut dianggap sebagai serangkaian interval diskrit: (-inf, 0.1), [0.1, 0.2), [0.2, 0.3), [0.3, 0.4), [0.4, 0.5), [0.5, 0.6), [0.6, 0.7), [0.7, 0.8), [0.8, 0.9), dan [0.9, 1.0). Setelah Anda mengonfigurasi parameter boundaries, Anda perlu mengonfigurasi parameter embedding_dim untuk mengonversi angka interval menjadi vektor.
3.2. Bagaimana FG digunakan untuk melakukan transformasi fitur dalam sistem online? Bagaimana cara memastikan konsistensi antara sistem offline dan online?
File fg.json digunakan untuk menggambarkan proses transformasi fitur. Sistem online dan offline menggunakan kode yang sama untuk memastikan konsistensi logika transformasi fitur. Sistem online menggunakan FG untuk melakukan transformasi fitur.
3.3. Bagaimana implementasi imputasi nilai yang hilang untuk fitur? Di mana saya mengonfigurasi imputasi nilai yang hilang?
Saat Anda mengonfigurasi file easyrec.config, Anda dapat mengonfigurasi parameter default_value untuk setiap bidang fitur dalam data_config untuk imputasi nilai yang hilang. Selama pelatihan model, nilai yang hilang diimputasi dengan nilai parameter default_value saat data dibaca. Selama inferensi model online, nilai yang hilang harus diimputasi terlebih dahulu agar inferensi dapat dilakukan.
Jika FG digunakan, imputasi nilai yang hilang dikonfigurasi dalam file fg.json untuk sistem online dan offline.