Armada ACK One mendukung layanan inferensi AI. Dalam skenario kluster ACK multi-wilayah dan multi-kluster cloud hibrida, Anda dapat menetapkan prioritas kluster untuk memprioritaskan penggunaan sumber daya dari pusat data lokal (IDC) atau wilayah utama, serta memanfaatkan sumber daya dari Alibaba Cloud atau wilayah cadangan sebagai daya komputasi tambahan. Penjadwalan berbasis inventaris ini menjamin kelangsungan bisnis.
Cara kerja
Fitur ini berlaku untuk skenario berikut.
Skenario kluster ACK multi-wilayah: Tetapkan Wilayah A sebagai wilayah utama untuk layanan inferensi AI dan Wilayah B sebagai wilayah cadangan. Kluster di Wilayah A memiliki prioritas lebih tinggi. Saat sumber daya GPU tidak mencukupi dan diperlukan perluasan kapasitas, armada ACK One terlebih dahulu menjadwalkan layanan inferensi ke Wilayah A berdasarkan prioritas kluster. Jika sumber daya di Wilayah A tidak mencukupi, layanan tersebut dijadwalkan ke Wilayah B. Saat melakukan scale-in, replika layanan inferensi di Wilayah B yang berprioritas lebih rendah akan di-scale-in terlebih dahulu, diikuti oleh replika di Wilayah A.
Skenario multi-kluster cloud hibrida: Anda dapat menggunakan armada untuk mengelola sumber daya IDC lokal dan sumber daya ACK berbasis cloud, dengan sumber daya cloud melengkapi sumber daya IDC lokal. Saat memperluas kapasitas, armada ACK One terlebih dahulu menjadwalkan layanan inferensi ke kluster IDC. Jika sumber daya IDC tidak mencukupi, layanan tersebut dijadwalkan ke kluster ACK untuk memanfaatkan daya komputasi cloud. Saat melakukan scale-in, replika layanan inferensi di cloud di-scale-in terlebih dahulu, diikuti oleh replika di IDC.
Contoh berikut berlaku untuk skenario multi-kluster cloud hibrida.
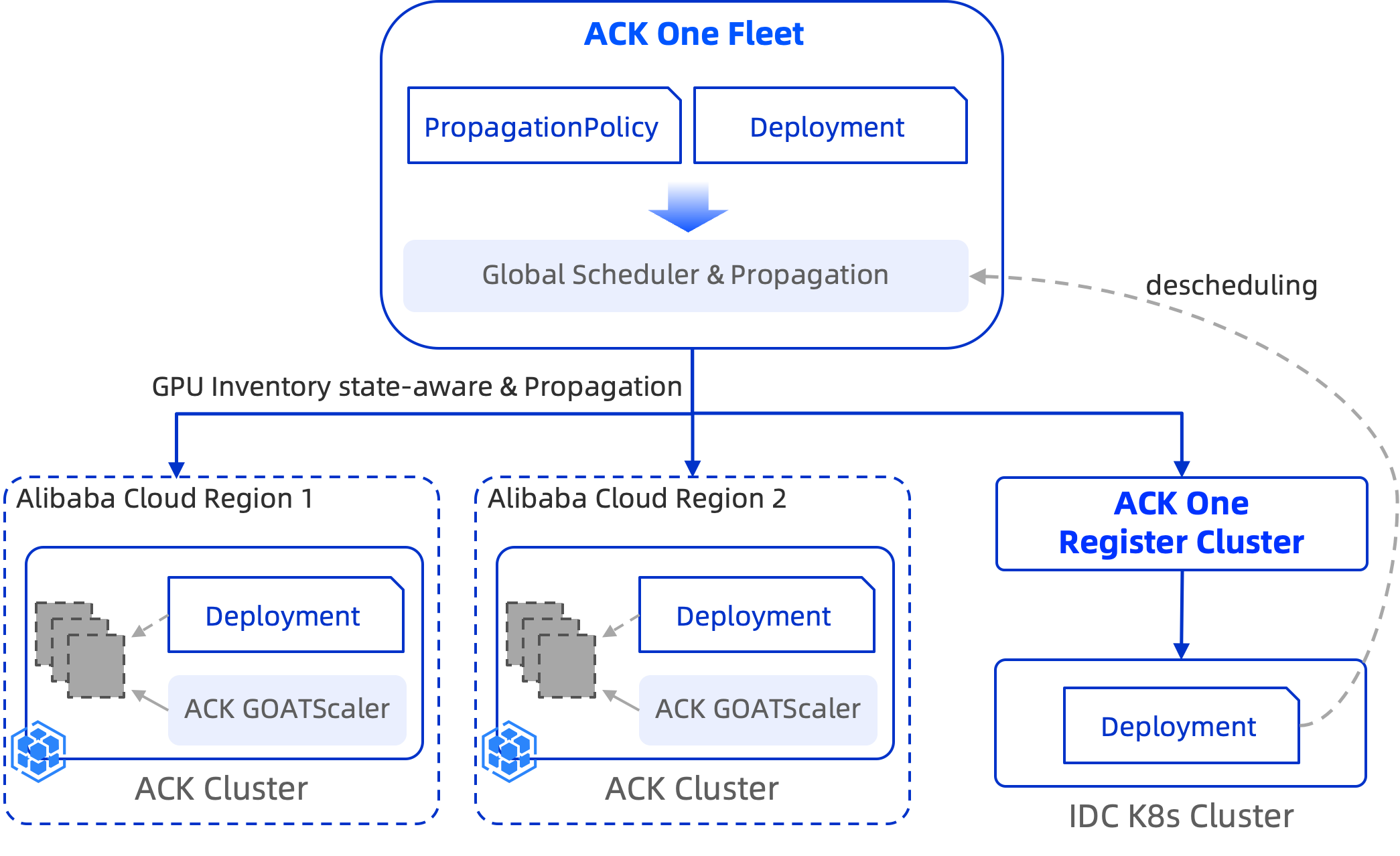
Penerapan
Elastisitas node instan diaktifkan untuk kluster anggota. Versi kluster ACK harus 1.24 atau lebih baru.
Jika node autoscaling sudah diaktifkan untuk kluster anggota, Anda dapat beralih ke instant node elasticity dengan mengikuti langkah-langkah dalam Langkah 1: Mengaktifkan elastisitas node instan
Alat baris perintah AMC telah diinstal.
Langkah 1: Menyebarkan layanan demo di armada
Contoh berikut menggunakan model qwen3-0.6b, yang diunduh dari ModelScope dan dijalankan dengan vllm. Untuk pengujian, Anda dapat menjalankan penerapan ini pada GPU T4 atau A10.
Buat namespace `test` di armada dan pastikan semua kluster anggota juga memiliki namespace ini.
kubectl create ns testBuat dan simpan file bernama
demo.yaml. Kemudian, jalankankubectl apply -f demo.yamldi armada untuk menyebarkan Deployment dan Service demo.apiVersion: apps/v1 kind: Deployment metadata: name: qwen3 namespace: test spec: progressDeadlineSeconds: 600 replicas: 2 revisionHistoryLimit: 10 selector: matchLabels: app: qwen3 template: metadata: labels: app: qwen3 spec: containers: # Gunakan model qwen3-0.6b, diunduh dari ModelScope - command: - sh - -c - export VLLM_USE_MODELSCOPE=True; vllm serve Qwen/Qwen3-0.6B --served-model-name qwen3-0.6b --port 8000 --trust-remote-code --tensor_parallel_size=1 --max-model-len 2048 --gpu-memory-utilization 0.8 image: kube-ai-registry.cn-shanghai.cr.aliyuncs.com/kube-ai/vllm-openai:v0.9.1 imagePullPolicy: IfNotPresent name: vllm ports: - containerPort: 8000 name: restful protocol: TCP readinessProbe: failureThreshold: 3 initialDelaySeconds: 30 periodSeconds: 10 successThreshold: 1 tcpSocket: port: 8000 timeoutSeconds: 1 resources: limits: nvidia.com/gpu: "1" requests: nvidia.com/gpu: "1" dnsPolicy: ClusterFirst restartPolicy: Always schedulerName: default-scheduler securityContext: {} terminationGracePeriodSeconds: 30 --- apiVersion: v1 kind: Service metadata: name: qwen3 namespace: test labels: app: qwen3 spec: ports: - port: 8000 selector: app: qwen3
Langkah 2: Menyebarkan kebijakan propagasi untuk penjadwalan elastis di cloud hibrida
Dalam PropagationPolicy berikut, Anda dapat mengaktifkan penjadwalan yang memperhatikan inventaris dan mengonfigurasi prioritas kluster. Konfigurasi ini memprioritaskan penjadwalan ke IDC. Jika sumber daya IDC tidak mencukupi, penjadwalan dialihkan ke cloud untuk memicu elastisitas node.
Ganti ${registered cluster ID} dan ${ACK Cluster ID} dalam contoh dengan ID kluster Anda. Buat dan simpan file bernama demo-pp.yaml. Kemudian, jalankan kubectl apply -f demo-pp.yaml di armada untuk menyebarkan PropagationPolicy.
Dalam contoh di bawah, bidang spec.resourceSelectors diisi dengan sumber daya contoh yang dibuat dalam Langkah 1: Menyebarkan layanan demo di armada. Di lingkungan produksi, gunakan informasi sumber daya aktual Anda.apiVersion: policy.one.alibabacloud.com/v1alpha1
kind: PropagationPolicy
metadata:
name: vllm-deploy-pp
namespace: test
spec:
autoScaling:
ecsProvision: true
placement:
clusterAffinities:
- affinityName: idc
clusterNames:
- ${registered cluster ID}
- affinityName: ack
clusterNames:
- ${ACK Cluster ID}
replicaScheduling:
replicaSchedulingType: Divided
replicaDivisionPreference: Weighted
weightPreference:
dynamicWeight: AvailableReplicas
preserveResourcesOnDeletion: false
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
namespace: test
schedulerName: default-scheduler
---
apiVersion: policy.one.alibabacloud.com/v1alpha1
kind: PropagationPolicy
metadata:
name: demo-svc
namespace: test
spec:
preserveResourcesOnDeletion: false
resourceSelectors:
- apiVersion: v1
kind: Service
name: qwen3
placement:
replicaScheduling:
replicaSchedulingType: DuplicatedLangkah 3: Memverifikasi penskalaan elastis
Jalankan
kubectl amc get pod -ntest -Muntuk melihat status penerapan.Pada awalnya, ketika kluster IDC memiliki sumber daya yang cukup, Pod diterapkan ke kluster IDC terlebih dahulu:
NAME CLUSTER CLUSTER_ALIAS READY STATUS RESTARTS AGE qwen3-5665b88779-7k*** c6b4******** cluster-idc-demo 1/1 Running 0 18m qwen3-5665b88779-ds*** c6b4******** cluster-idc-demo 1/1 Running 0 18mPerluas jumlah replika untuk layanan inferensi di armada:
kubectl scale deploy qwen3 -ntest --replicas=4Setelah proses scale-out selesai, jalankan
kubectl amc get pod -ntest -Muntuk melihat status penerapan Pod.Pod baru dijadwalkan ke kluster ACK. Dua Pod berada dalam status Pending, yang menunjukkan bahwa kluster ACK kekurangan sumber daya:
NAME CLUSTER CLUSTER_ALIAS READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES ADOPTION qwen3-5665b88779-7k*** c043******** cluster-bj-demo 0/1 Pending 0 33s <none> <none> <none> <none> N qwen3-5665b88779-ds*** c043******** cluster-bj-demo 0/1 Pending 0 33s <none> <none> <none> <none> N qwen3-5665b88779-7k*** c6b4******** cluster-idc-demo 1/1 Running 0 18m 172.20.245.125 x.x.x.x <none> <none> N qwen3-5665b88779-ds*** c6b4******** cluster-idc-demo 1/1 Running 0 18m 172.19.8.159 x.x.x.x <none> <none> NJalankan perintah
kubectl amc get node -Muntuk memeriksa status node. Output menunjukkan bahwa dua node baru telah ditambahkan secara elastis dan sedang bergabung ke kluster ACK:Setelah layanan inferensi di-scale-in, node yang ditambahkan secara elastis akan dihapus secara otomatis setelah 10 menit.
NAME CLUSTER CLUSTER_ALIAS STATUS ROLES AGE VERSION ADOPTION cn-beijing.172.19.8.*** c043******** cluster-bj-demo NotReady <none> 20s N cn-beijing.172.20.245.** c043******** cluster-bj-demo Ready <none> 18h v1.34.1-aliyun.1 N cn-beijing.172.21.3.*** c043******** cluster-bj-demo NotReady <none> 20s N cn-beijing.172.21.3.** c043******** cluster-bj-demo Ready <none> 18h v1.34.1-aliyun.1 N cn-beijing.172.20.245.** c6b4******** cluster-idc-demo Ready <none> 3h14m v1.34.1-aliyun.1 N cn-beijing.172.21.3.** c6b4******** cluster-idc-demo Ready <none> 3h16m v1.34.1-aliyun.1 N cn-beijing.172.21.3.** c6b4******** cluster-idc-demo Ready <none> 3h13m v1.34.1-aliyun.1 NSaat melakukan scale-in, replika dihapus berdasarkan prioritas kluster yang ditentukan dalam PropagationPolicy, dari prioritas terendah ke tertinggi.
Kurangi jumlah replika untuk layanan inferensi di armada:
kubectl scale deploy qwen3 -ntest --replicas=2Jalankan
kubectl amc get pod -ntest -Muntuk melihat status penerapan Pod. Output menunjukkan bahwa dua replika di kluster ACK telah di-scale-in:NAME CLUSTER CLUSTER_ALIAS READY STATUS RESTARTS AGE qwen3-5665b88779-7k*** c6b4******** cluster-idc-demo 1/1 Running 0 18m qwen3-5665b88779-ds*** c6b4******** cluster-idc-demo 1/1 Running 0 18m