Layanan inferensi Large Language Model (LLM) online sering menggunakan arsitektur multi-kluster untuk mengatasi fluktuasi lalu lintas. ACK One menyediakan solusi multi-kluster yang sesuai dengan skenario ini. Topik ini menjelaskan cara menerapkan layanan inferensi vLLM di cloud menggunakan armada ACK One dan melakukan penskalaan lintas kluster dengan FederatedHPA (Federated Horizontal Pod Autoscaler).
Cara kerja
Dalam skenario inferensi berskala besar, layanan LLM online menghadapi lonjakan lalu lintas yang tajam dan tidak dapat diprediksi. Arsitektur multi-kluster merupakan solusi umum untuk menangani puncak lalu lintas tersebut:
-
Pengguna dengan pusat data lokal biasanya menerapkan arsitektur Cloud Hibrida. Saat terjadi lonjakan lalu lintas, mereka melakukan scale out workload ke kluster cloud.
-
Pengguna cloud sering menerapkan beberapa kluster di berbagai wilayah untuk menghindari kekurangan resource di satu wilayah.
Armada ACK One mengelola resource lintas beberapa kluster dan mendukung penjadwalan serta Auto Scaling lintas kluster. Solusi ini memenuhi kebutuhan kedua model penerapan tersebut:
-
Penjadwalan multi-kluster berbasis prioritas: Tetapkan prioritas penjadwalan untuk kluster. Jadwalkan replika ke kluster berprioritas tinggi terlebih dahulu. Saat resource menipis, lakukan scale out ke kluster berprioritas rendah. Lakukan scale in dengan menghapus replika dari kluster berprioritas rendah terlebih dahulu.
-
Penjadwalan cerdas berbasis inventaris: Kluster armada bekerja sama dengan GoatScaler di kluster anak dan menggunakan inventaris ECS untuk menjadwalkan replika secara cerdas.
-
Auto Scaling terpusat terpadu: Buat FederatedHPA untuk melakukan penskalaan workload lintas kluster dari satu titik pusat. Metrics Adapter pada kluster armada mengumpulkan dan mengagregasi metrik dari kluster anak (yang juga mendukung Prometheus Adapter). Selanjutnya, workload diskalakan berdasarkan metrik agregat tersebut.
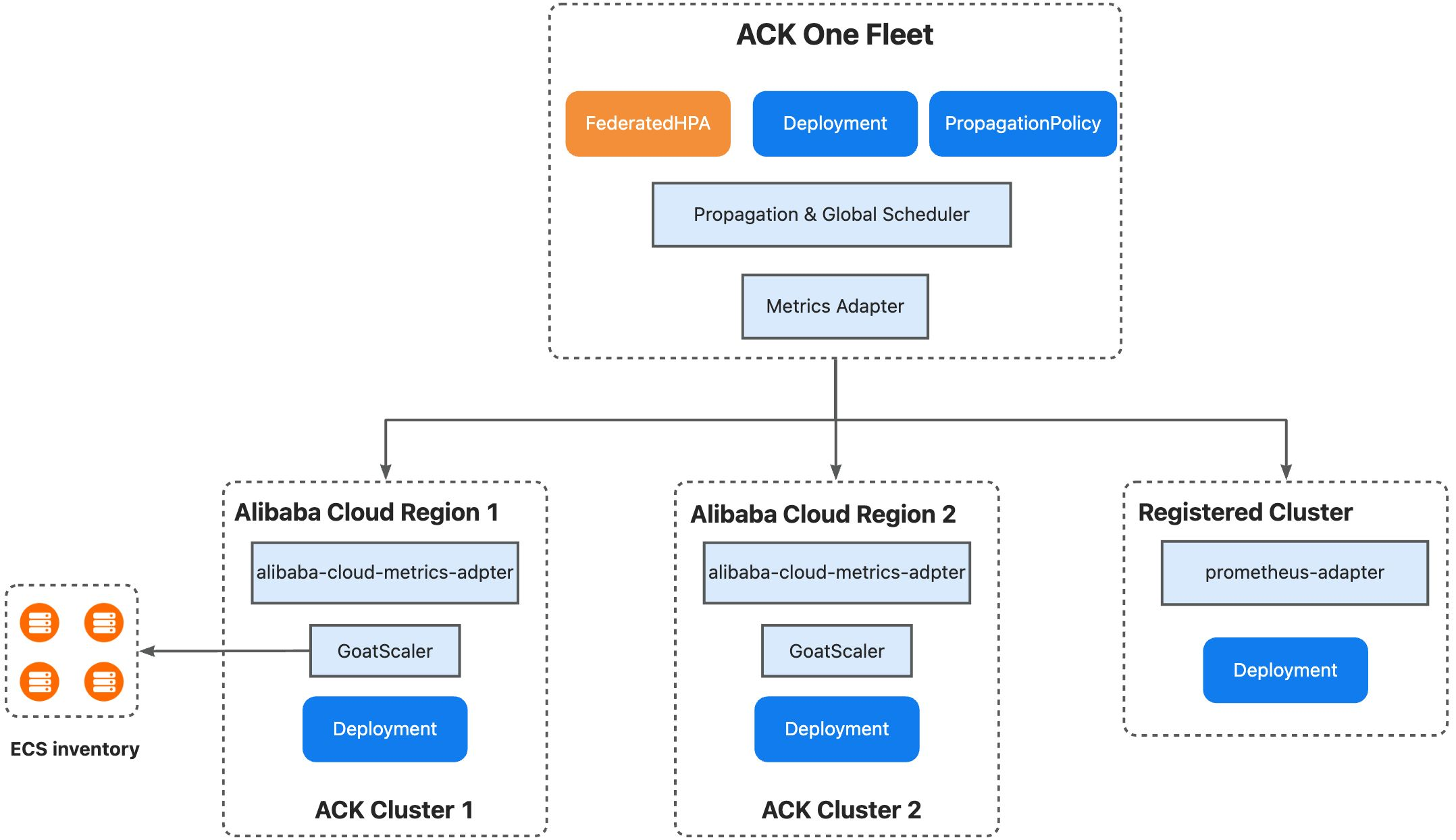
Lingkup
-
Anda telah membuat dua kluster ACK. Setiap kluster memiliki kelompok node GPU dan setidaknya satu instans GPU yang telah diinisialisasi.
-
Anda telah menambahkan kedua kluster ACK ke dalam armada ACK One dan menginstal komponen alibaba-cloud-metrics-adapter. Untuk kluster terdaftar, instal Prometheus Adapter open-source .
-
Anda telah menginstal plugin kubectl amc.
Fitur Horizontal Pod Autoscaler (HPA) multi-kluster sedang dalam pratinjau undangan. Hubungi kami untuk mengajukan akses daftar putih sebelum menggunakannya.
Prosedur
Langkah 1: Konfigurasikan pengumpulan metrik di kluster anak
Konfigurasikan parameter untuk komponen ack-alibaba-cloud-metrics-adapter di kedua kluster ACK.
Masuk ke Container Service Management Console . Di panel navigasi sebelah kiri, klik Clusters.
Pada halaman Clusters, klik nama kluster Anda. Di panel navigasi sebelah kiri, klik .
-
Temukan komponen ack-alibaba-cloud-metrics-adapter. Pada kolom Actions, klik Update. Pada bidang
prometheus.adapter.rules, modifikasi konfigurasi pengumpulan metrik. Contohnya:-
vllm:num_requests_waiting: Jumlah permintaan yang menunggu untuk diproses. -
vllm:num_requests_running: Jumlah permintaan yang sedang diproses.
rules: - seriesQuery: 'vllm:num_requests_waiting' resources: overrides: kubernetes_namespace: {resource: "namespace"} kubernetes_pod_name: {resource: "pod"} name: matches: 'vllm:num_requests_waiting' as: 'num_requests_waiting' metricsQuery: 'sum(<<.Series>>{<<.LabelMatchers>>}) by (<<.GroupBy>>)' - seriesQuery: 'vllm:num_requests_running' resources: overrides: kubernetes_namespace: {resource: "namespace"} kubernetes_pod_name: {resource: "pod"} name: matches: 'vllm:num_requests_running' as: 'num_requests_running' metricsQuery: 'sum(<<.Series>>{<<.LabelMatchers>>}) by (<<.GroupBy>>)' -
-
Klik
OK. -
Verifikasi bahwa metrik kustom telah dikonfigurasi dengan benar.
# Lihat metrik kustom kubectl get --raw "/apis/custom.metrics.k8s.io/v1beta1/namespaces/test/pods/qwen3-xxxxx/num_requests_waiting" kubectl get --raw "/apis/custom.metrics.k8s.io/v1beta1/namespaces/test/pods/qwen3-xxxxx/num_requests_running"Jika output menampilkan metrik vLLM, konfigurasi pengumpulan metrik berhasil.
Langkah 2: Terapkan layanan inferensi vLLM di armada
Simpan templat YAML berikut sebagai deployment.yaml. Kemudian jalankan kubectl apply -f deployment.yaml untuk menerapkan layanan inferensi di armada.
apiVersion: apps/v1
kind: Deployment
metadata:
name: qwen3
namespace: test
spec:
progressDeadlineSeconds: 600
replicas: 1
revisionHistoryLimit: 10
selector:
matchLabels:
app: qwen3
template:
metadata:
annotations:
# Menangkap metrik pod, mirip dengan PodMonitor
prometheus.io/path: /metrics
prometheus.io/port: "8000"
prometheus.io/scrape: "true"
labels:
app: qwen3
spec:
containers:
# Menggunakan model qwen3-0.6b, diunduh dari ModelScope
- command:
- sh
- -c
- export VLLM_USE_MODELSCOPE=True; vllm serve Qwen/Qwen3-0.6B --served-model-name
qwen3-0.6b --port 8000 --trust-remote-code --tensor_parallel_size=1 --max-model-len
2048 --gpu-memory-utilization 0.8
image: kube-ai-registry.cn-shanghai.cr.aliyuncs.com/kube-ai/vllm-openai:v0.9.1
imagePullPolicy: IfNotPresent
name: vllm
ports:
- containerPort: 8000
name: restful
protocol: TCP
readinessProbe:
failureThreshold: 3
initialDelaySeconds: 30
periodSeconds: 10
successThreshold: 1
tcpSocket:
port: 8000
timeoutSeconds: 1
resources:
limits:
nvidia.com/gpu: "1"
requests:
nvidia.com/gpu: "1"
dnsPolicy: ClusterFirst
restartPolicy: Always
schedulerName: default-scheduler
securityContext: {}
terminationGracePeriodSeconds: 30Langkah 3: Konfigurasikan kebijakan distribusi multi-kluster di armada
Simpan templat YAML berikut sebagai propagationpolicy.yaml. Kemudian jalankan kubectl apply -f propagationpolicy.yaml.
-
autoScaling.ecsProvision: Mengaktifkan penjadwalan cerdas berbasis inventaris. Melakukan penskalaan instans ECS secara otomatis sesuai kebutuhan. -
clusterAffinities: Pengelompokan berbasis prioritas. Saat penjadwalan, sistem mengisi kelompok afinitas sesuai urutan prioritas.
apiVersion: policy.one.alibabacloud.com/v1alpha1
kind: PropagationPolicy
metadata:
name: vllm-deploy-pp
namespace: test
spec:
autoScaling:
ecsProvision: true
placement:
clusterAffinities:
- affinityName: high-priority
clusterNames:
- ${cluster1_id}
- affinityName: low-priority
clusterNames:
- ${cluster2_id}
replicaScheduling:
replicaSchedulingType: Divided
replicaDivisionPreference: Weighted
weightPreference:
dynamicWeight: AvailableReplicas
preserveResourcesOnDeletion: false
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
namespace: test
- apiVersion: v1
kind: Service
namespace: test
schedulerName: default-schedulerLangkah 4: Buat FederatedHPA di armada
FederatedHPA memantau CPU, memori, metrik kustom, dan metrik eksternal untuk pod. Contoh berikut menggunakan metrik kustom num_requests_waiting dan num_requests_running untuk melakukan penskalaan workload.
Simpan templat YAML berikut sebagai federatedhpa.yaml. Kemudian jalankan kubectl apply -f federatedhpa.yaml.
apiVersion: autoscaling.one.alibabacloud.com/v1alpha1
kind: FederatedHPA
metadata:
name: vllm-fhpa
namespace: test
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: qwen3
minReplicas: 1
maxReplicas: 10
behavior:
scaleDown:
stabilizationWindowSeconds: 30
scaleUp:
stabilizationWindowSeconds: 10
metrics:
- type: Pods
pods:
metric:
name: num_requests_waiting
target:
type: AverageValue
averageValue: ${waiting_size} # Nilai optimal bervariasi tergantung GPU dan model
- type: Pods
pods:
metric:
name: num_requests_running
target:
type: AverageValue
averageValue: ${running_size} # Nilai optimal bervariasi tergantung GPU dan modelVerifikasi hasil
-
Verifikasi penjadwalan berbasis prioritas
Jalankan
kubectl scale deployment -n test qwen3 --replicas=2untuk melakukan scale out workload. Karena cluster1 hanya memiliki satu instans GPU, replika kedua dijadwalkan ke cluster2 dalam kelompok berprioritas rendah. -
Verifikasi FederatedHPA
-
Gunakan ALB multi-kluster untuk mengekspos layanan, seperti dijelaskan dalam Manage north-south traffic. Kemudian peroleh alamat Ingress.
-
Ganti alamat ALB dalam perintah berikut dan jalankannya untuk melakukan load-test terhadap layanan.
hey -n 600 -c 60 -m POST -H "Content-Type: application/json" -d '{"messages": [{"role": "user", "content": "Test it"}]}' http://alb-xxxxxx.cn-hangzhou.alb.aliyuncsslb.com:8000/v1/chat/completionsAnda akan melihat
num_requests_runningmeningkat tajam dan jumlah replika bertambah:Current Metrics: Pods: Current: Average Value: 0 Metric: Name: num_requests_waiting Type: Pods Pods: Current: Average Value: 58 Metric: Name: num_requests_running Type: Pods Current Replicas: 2 Desired Replicas: 3
-
-
Verifikasi penjadwalan cerdas berbasis inventaris
Setelah melakukan penskalaan aplikasi inferensi menjadi tiga replika, replika baru berhasil dimulai—meskipun cluster1 dan cluster2 secara gabungan hanya memiliki dua instans GPU. Hal ini mengonfirmasi bahwa penjadwalan cerdas berbasis inventaris telah berfungsi.
FAQ
kubectl get fhpa menampilkan nilai kosong di kolom REPLICAS. Mengapa?
FederatedHPA tidak cocok dengan workload target. Periksa pengaturan nama dan namespace workload.
kubectl get fhpa -o yaml mengembalikan error. Mengapa?
Kesalahan kondisi berbunyi the HPA was unable to compute the replica count: unable to obtain metric xxx. FederatedHPA gagal mengambil metrik dari workload di kluster anak.
-
Konfirmasi bahwa komponen ack-alibaba-cloud-metrics-adapter telah diinstal di semua kluster anak.
-
Konfirmasi bahwa parameter komponen ack-alibaba-cloud-metrics-adapter sudah benar di setiap kluster anak. Kueri metrik di dasbor kluster anak untuk verifikasi.
Mengapa saya tidak dapat melihat metrik di kluster anak?
Jalankan perintah berikut untuk memeriksa apakah metrik telah terdaftar. Jika tidak ada metrik yang muncul, tinjau ulang pengaturan parameter aplikasi Helm.
kubectl get --raw "/apis/custom.metrics.k8s.io/v1beta1" | jq .