Topik ini menjelaskan cara mengimplementasikan penjadwalan kolokasi untuk Slurm dan Kubernetes dalam Container Service for Kubernetes (ACK) cluster. Solusi ini membantu Anda mengoptimalkan alokasi sumber daya dan penjadwalan beban kerja untuk pekerjaan komputasi kinerja tinggi (HPC) serta aplikasi berbasis kontainer di cluster Anda. Selain itu, solusi ini meningkatkan pemanfaatan sumber daya, stabilitas cluster, dan performa beban kerja. Anda dapat menggunakan solusi ini untuk memenuhi kebutuhan berbagai skenario komputasi dan membangun platform komputasi yang efisien dan fleksibel.
Ikhtisar
Mengapa kita perlu mengimplementasikan penjadwalan kolokasi di cluster ACK?
Solusi penjadwalan default: ACK secara statis mengalokasikan sumber daya. ACK dan Slurm menjadwalkan beban kerja secara terpisah. Di cluster Slurm, setiap pod Slurm memprakonsumsi sumber daya cluster. Kubernetes tidak dapat menggunakan sumber daya idle yang telah diprakonsumsi oleh pod Slurm. Hal ini menghasilkan fragmen sumber daya cluster. Jika Anda ingin memodifikasi konfigurasi sumber daya dari sebuah pod Slurm, Anda harus menghapus dan membuat ulang pod tersebut. Oleh karena itu, dalam skenario di mana ada kesenjangan besar antara sumber daya yang digunakan oleh cluster Slurm dan sumber daya yang digunakan oleh cluster Kubernetes, sulit untuk memigrasikan beban kerja ke node lain.
Solusi penjadwalan kolokasi: ACK menyediakan komponen ack-slurm-operator untuk mengimplementasikan penjadwalan kolokasi untuk Slurm dan Kubernetes di cluster ACK. Solusi ini menjalankan copilot di cluster Kubernetes dan plugin sumber daya ekstensi di cluster Slurm. Ini memungkinkan Kubernetes dan Slurm berbagi sumber daya cluster serta menghindari pengalokasian sumber daya berulang kali.
Gambar berikut menunjukkan solusi berbagi sumber daya sebelumnya.
Alokasi sumber daya statis dan penjadwalan beban kerja terpisah | Penjadwalan kolokasi untuk Slurm dan Kubernetes |
Gambar berikut menunjukkan cara kerja solusi penjadwalan kolokasi.
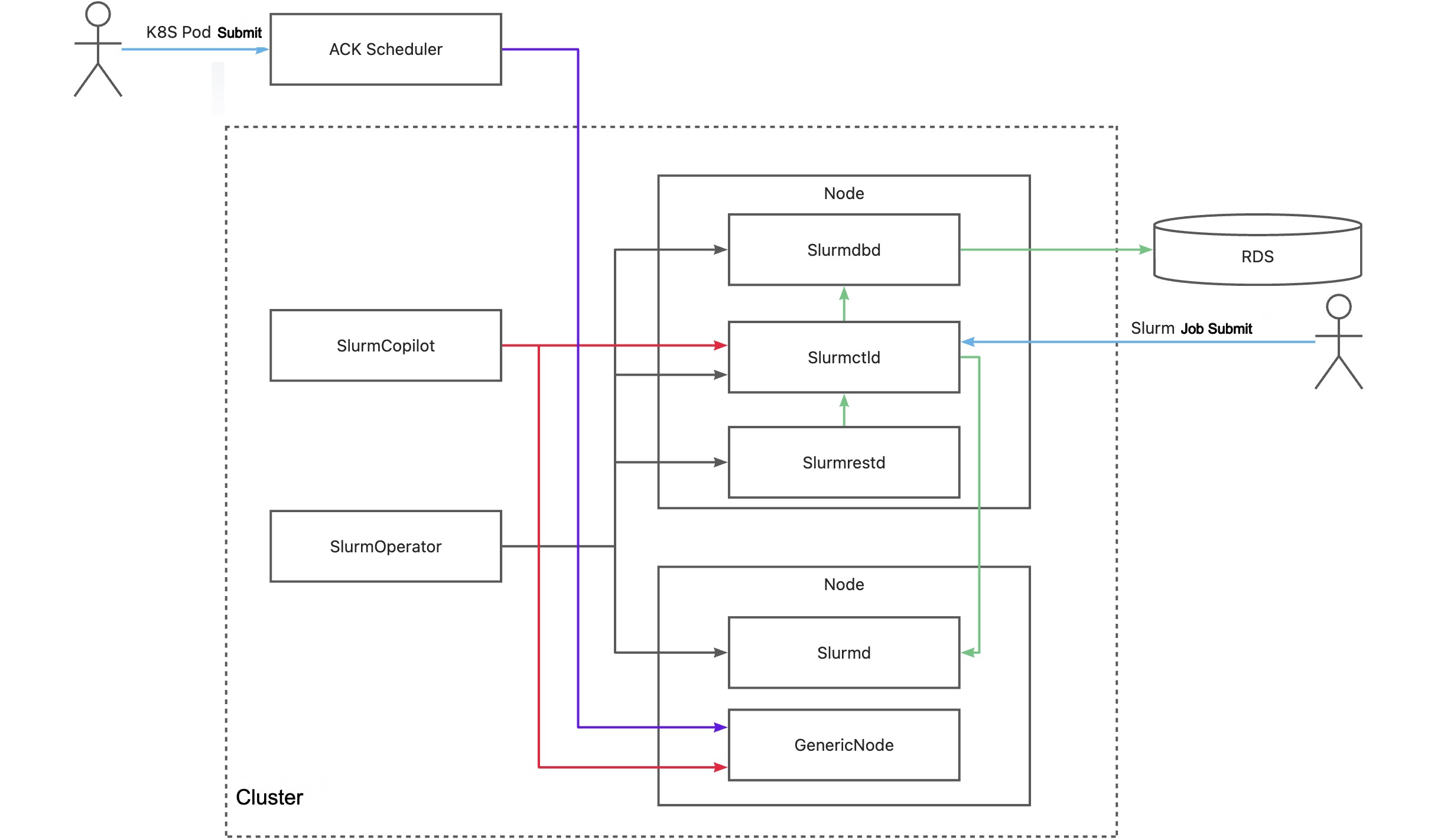
Komponen utama | Deskripsi |
SlurmOperator | Komponen ini meluncurkan kluster Slurm di dalam kluster ACK. Kluster Slurm di-container-kan dan setiap pod pekerja Slurm berjalan pada node terpisah. Komponen sistem Slurm lainnya dijadwalkan ke node acak. |
SlurmCopilot | Komponen ini menggunakan token kluster untuk berkoordinasi dengan slurmctld dalam alokasi sumber daya. Secara default, ketika slurmctld dijalankan, komponen ini secara otomatis menghasilkan token dan memperbarui token tersebut ke Secret menggunakan kubectl. Untuk memperbarui token secara manual, Anda dapat menggunakan skrip inisialisasi kustom atau mencabut izin pembaruan Secret. Kemudian, Anda perlu memperbarui token secara manual ke ack-slurm-jwt-token di namespace ack-slurm-operator. ack-slurm-jwt-token adalah pasangan nilai-kunci. Kuncinya adalah nama kluster dan nilainya adalah konten token yang dihasilkan dan di-enkode Base64 (base64 --wrap=0). Setelah pemeriksaan admission ditambahkan ke GenericNode, komponen ini memodifikasi jumlah sumber daya yang tersedia pada node yang sesuai di slurmctld. Setelah modifikasi selesai, status sumber daya diperbarui ke GenericNode. Lalu, komponen ini memberi tahu ACK scheduler untuk melakukan penjadwalan beban kerja. |
Slurmctld | Pengelola pusat dari Slurm. Komponen ini memantau sumber daya dan pekerjaan di kluster Slurm, menjadwalkan pekerjaan, dan mengalokasikan sumber daya. Untuk meningkatkan ketersediaan slurmctld, Anda dapat mengonfigurasi pod sekunder untuk slurmctld. |
GenericNodes | Komponen ini adalah resource kustom yang berfungsi sebagai buku besar sumber daya antara Kubernetes dan Slurm. Ketika scheduler ACK menjadwalkan pod ke node, pemeriksaan masuk ditambahkan ke GenericNode dari node untuk meminta sistem Slurm mengonfirmasi alokasi sumber daya. |
Slurmd | Daemon yang berjalan di setiap node komputasi. Komponen ini menjalankan pekerjaan dan melaporkan status node dan pekerjaan ke slurmctld. |
Slurmdbd | Daemon database Slurm. Komponen ini mencatat dan mengelola informasi buku besar dari pekerjaan yang berbeda dan menyediakan operasi API untuk kueri data dan statistik. slurmdbd adalah komponen opsional. Jika Anda tidak menginstal slurmdbd, Anda dapat mencatat informasi buku besar dalam file. |
Slurmrested | Daemon API RESTful yang memungkinkan Anda berinteraksi dengan Slurm dan menggunakan fitur-fitur Slurm dengan memanggil API RESTful. slurmrestd adalah komponen opsional. Jika Anda tidak menginstal slurmrestd, Anda dapat menggunakan alat baris perintah untuk berinteraksi dengan Slurm. |
1. Persiapkan lingkungan
1.1 Instal ack-slurm-operator
Sebuah cluster ACK yang menjalankan Kubernetes 1.26 atau lebih baru telah dibuat. Untuk informasi lebih lanjut, lihat Buat Cluster ACK dengan Node GPU-accelerated dan Perbarui Cluster.
Instal ack-slurm-operator dan aktifkan fitur Copilot. Dengan cara ini, Anda dapat menggunakan Slurm untuk menjadwalkan pekerjaan dan menggunakan Kubernetes untuk menjadwalkan pod pada batch server fisik yang sama.
Masuk ke Konsol ACK. Klik nama cluster yang Anda buat. Pada halaman detail cluster, klik callout secara berurutan untuk menginstal ack-slurm-operator.
Parameter Application Name dan Namespace bersifat opsional. Klik Next (callout ④). Dalam pesan Confirm, klik Yes. Dalam kasus ini, aplikasi default ack-slurm-operator dan namespace default ack-slurm-operator digunakan.
Pilih versi terbaru untuk Chart Version. Atur
enableCopilot(callout ②) menjaditruedanwatchNamespace(callout ③) menjadidefault. Anda dapat mengatur watchNamespace ke namespace kustom berdasarkan kebutuhan bisnis Anda. Lalu, klik OK untuk menginstal ack-slurm-operator.
Opsional: Perbarui ack-slurm-operator.
Masuk ke Konsol ACK. Pada halaman Informasi Cluster, pilih Aplikasi > Helm. Pada halaman Aplikasi, temukan ack-slurm-operator dan klik Perbarui.
1.2 Instal dan konfigurasikan ack-slurm-cluster
Untuk menerapkan dan mengelola cluster Slurm dengan cepat serta memodifikasi konfigurasi cluster secara fleksibel, Anda dapat menggunakan Helm untuk menginstal paket SlurmClusterart yang disediakan oleh Alibaba Cloud. Unduh Helm chart untuk cluster Slurm dari charts-incubator dan atur parameter yang relevan. Lalu, Helm akan membuat sumber daya kontrol akses berbasis peran (RBAC), ConfigMaps, Secrets, dan cluster Slurm untuk Anda.
Lakukan operasi berikut:
Jalankan perintah berikut untuk menambahkan repositori chart yang disediakan oleh Alibaba Cloud ke klien Helm Anda: Setelah repositori ditambahkan, Anda dapat mengakses Helm chart yang disediakan oleh Alibaba Cloud, seperti chart komponen ack-slurm-cluster.
helm repo add aliyun https://aliacs-app-catalog.oss-cn-hangzhou.aliyuncs.com/charts-incubator/Jalankan perintah berikut untuk menarik dan mendekompres chart ack-slurm-cluster. Operasi ini membuat subdirektori bernama
ack-slurm-clusterdi direktori saat ini. Direktori ack-slurm-cluster berisi semua file dan template yang termasuk dalam chart.helm pull aliyun/ack-slurm-cluster --untar=trueJalankan perintah berikut untuk memodifikasi parameter chart di file values.yaml.
File values.yaml berisi konfigurasi default dari chart. Anda dapat memodifikasi pengaturan parameter di file berdasarkan kebutuhan bisnis Anda. Pengaturan tersebut mencakup konfigurasi Slurm, permintaan sumber daya dan batasnya, serta konfigurasi penyimpanan.
cd ack-slurm-cluster vi values.yamlJalankan perintah berikut untuk menginstal chart ack-slurm-cluster. Jika chart ack-slurm-cluster sudah diinstal, Anda dapat menjalankan perintah helm upgrade untuk memperbarui chart yang telah diinstal. Setelah Anda memperbarui chart yang telah diinstal, Anda harus secara manual menghapus pod yang ada dan StatefulSet yang dibuat untuk slurmctld agar pembaruan berlaku.
cd .. helm install my-slurm-cluster ack-slurm-cluster # Ganti my-slurm-cluster dengan nilai aktual.Setelah menginstal chart, jalankan perintah
helm listuntuk memeriksa apakah chart ack-slurm-cluster berhasil diinstal.helm listKeluaran yang diharapkan:
NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSION ack-slurm-cluster default 1 2024-07-19 14:47:58.126357 +0800 CST deployed ack-slurm-cluster-2.0.0 2.0.0Periksa apakah slurmrestd dan slurmdbd berjalan sesuai harapan.
Gunakan kubectl untuk terhubung ke cluster dan periksa apakah pod slurmdbd berjalan sesuai harapan.
kubectl get podKeluaran sampel berikut menunjukkan bahwa satu pod pekerja dan tiga pod kontrol plane berjalan di cluster.
NAME READY STATUS RESTARTS AGE slurm-test-slurmctld-dlncz 1/1 Running 0 3h49m slurm-test-slurmdbd-8f75r 1/1 Running 0 3h49m slurm-test-slurmrestd-mjdzt 1/1 Running 0 3h49m slurm-test-worker-cpu-0 1/1 Running 0 166mJalankan perintah berikut untuk menanyakan log. Anda dapat melihat log untuk memeriksa apakah slurmdbd berjalan sesuai harapan.
kubectl exec slurm-test-slurmdbd-8f75r cat /var/log/slurmdbd.log | headKeluaran yang diharapkan:
kubectl exec [POD] [COMMAND] is DEPRECATED and will be removed in a future version. Use kubectl exec [POD] -- [COMMAND] instead. [2024-07-22T19:52:55.727] accounting_storage/as_mysql: _check_mysql_concat_is_sane: Versi server MySQL adalah: 8.0.34 [2024-07-22T19:52:55.737] error: Pengaturan database bukan nilai yang direkomendasikan: innodb_lock_wait_timeout [2024-07-22T19:52:56.089] slurmdbd versi 23.02.7 dimulai
Klik Tampilkan Langkah-langkah untuk Membangun Image Slurm untuk melihat cara menginstal dependensi di Slurm.
2. Uji penjadwalan kolokasi
2.1 Uji penjadwalan kolokasi
Periksa status GenericNodes untuk melihat beban kerja Slurm dan beban kerja Kubernetes.
kubectl get genericnodeKeluaran yang diharapkan:
NAME CLUSTERNAME ALIAS TYPE ALLOCATEDRESOURCES cn-hongkong.10.1.0.19 slurm-test-worker-cpu-0 Slurm [{"allocated":{"cpu":"0","memory":"0"},"type":"Slurm"},{"allocated":{"cpu":"1735m","memory":"2393Mi"},"type":"Kubernetes"}]Jalankan perintah berikut untuk mengirim pekerjaan ke cluster Slurm dan menanyakan GenericNodes. GenericNode yang dikembalikan mencatat penggunaan sumber daya dari pekerjaan di cluster Slurm dan penggunaan sumber daya dari pekerjaan di cluster Kubernetes.
root@iZj6c1wf3c25dbynbna3qgZ ~]# kubectl exec slurm-test-slurmctld-dlncz -- nohup srun --cpus-per-task=3 --mem=4000 --gres=k8scpu:3,k8smemory:4000 sleep inf & [1] 4132674 [root@iZj6c1wf3c25dbynbna3qgZ ~]# kubectl scale deployment nginx-deployment-basic --replicas 2 deployment.apps/nginx-deployment-basic scaled [root@iZj6c1wf3c25dbynbna3qgZ ~]# kubectl get genericnode NAME CLUSTERNAME ALIAS TYPE ALLOCATEDRESOURCES cn-hongkong.10.1.0.19 slurm-test-worker-cpu-0 Slurm [{"allocated":{"cpu":"3","memory":"4000Mi"},"type":"Slurm"},{"allocated":{"cpu":"2735m","memory":"3417Mi"},"type":"Kubernetes"}]Dalam kasus ini, jika Anda mengirim pekerjaan lain ke cluster Slurm, pekerjaan kedua akan memasuki status Pending.
[root@iZj6c1wf3c25dbynbna3qgZ ~]# kubectl exec slurm-test-slurmctld-dlncz -- nohup srun --cpus-per-task=3 --mem=4000 sleep inf & [2] 4133454 [root@iZj6c1wf3c25dbynbna3qgZ ~]# srun: job 2 queued and waiting for resources [root@iZj6c1wf3c25dbynbna3qgZ ~]# kubectl exec slurm-test-slurmctld-dlncz -- squeue JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON) 2 debug sleep root PD 0:00 1 (Resources) 1 debug sleep root R 2:34 1 slurm-test-worker-cpu-0
Dalam contoh ini, tidak ada GRE yang ditentukan secara manual. Namun, GRE masih ditampilkan dalam perintah srun sebelumnya. Hal ini karena cluster Slurm telah diinstal sebelumnya dengan plugin job_resource_completion, yang secara otomatis menambahkan GRE berdasarkan permintaan CPU dan permintaan memori. Jika job_resource_completion tidak diinstal, Anda harus secara manual menentukan GRE. Dalam contoh ini, konfigurasi GRE berikut ditentukan: --gres=k8scpu:3,k8smemory:4000. Klik Tampilkan Deskripsi Skrip Pekerjaan Slurm untuk melihat cara menentukan parameter dalam skrip pekerjaan Slurm.
Opsional: 2.2 Implementasikan penjadwalan kolokasi di cluster Slurm non-kontainer
SlurmCopilot menggunakan API Slurm untuk berinteraksi dengan Slurm. Metode interaksi ini juga berlaku untuk skenario cluster Slurm non-kontainer.
Dalam skenario cluster Slurm non-kontainer, sumber daya Kubernetes tertentu hanya dapat dibuat secara manual, termasuk token yang disebutkan di bagian sebelumnya. Bagian berikut menjelaskan sumber daya Kubernetes yang harus dibuat secara manual.
Buat Service untuk setiap cluster Slurm.
SlurmCopilot menanyakan informasi tentang Service dari cluster dan mengirimkan permintaan API ke endpoint
${.metadata.name}.${.metadata.namespace}.svc.cluster.local:${.spec.ports[0].port}. Dalam skenario cluster Slurm non-kontainer, Anda harus membuat Service untuk setiap cluster Slurm. Blok kode berikut memberikan contoh konfigurasi Service. Perhatikan bahwa nama Service dari cluster Slurm harus dalam format ${slurmCluster}-slurmrestd. Nilai ${slurmCluster} harus sesuai dengan GenericNodes di cluster Slurm.apiVersion: v1 kind: Service metadata: name: slurm-slurmrestd namespace: default spec: ports: - name: slurmrestd port: 8080 protocol: TCP targetPort: 8080Konfigurasikan catatan DNS untuk setiap cluster Slurm.
Untuk mengaktifkan akses ke proses slurmrestd, Anda harus mengonfigurasi catatan DNS dalam konfigurasi SlurmCopilot untuk menunjuk
${.metadata.name}.${.metadata.namespace}.svc.cluster.local:${.spec.ports[0].port}ke alamat IP proses slurmrestd.Buat GenericNodes untuk node di cluster Slurm.
SlurmCopilot menggunakan GenericNodes sebagai alias node di cluster Slurm. Jika Anda tidak membuat GenericNode untuk node di cluster Slurm, SlurmCopolit tidak dapat memperoleh informasi tentang node tersebut. Nama GenericNode untuk sebuah node harus sama dengan nama node dalam sistem Kubernetes. Nilai parameter
.spec.aliasharus sama dengan nama node dalam sistem Slurm. Labelkai.alibabacloud.com/cluster-namedankai.alibabacloud.com/cluster-namespaceharus sesuai dengan Service cluster Slurm.apiVersion: kai.alibabacloud.com/v1alpha1 kind: GenericNode metadata: labels: kai.alibabacloud.com/cluster-name: slurm-test kai.alibabacloud.com/cluster-namespace: default name: cn-hongkong.10.1.0.19 spec: alias: slurm-test-worker-cpu-0 type: Slurm
Ringkasan
Dalam lingkungan beban kerja kolokasi, Anda dapat menggunakan Slurm untuk menjadwalkan pekerjaan HPC dan menggunakan Kubernetes untuk mengatur beban kerja berbasis kontainer. Solusi penjadwalan kolokasi ini memungkinkan Anda menggunakan ekosistem dan layanan Kubernetes, termasuk Helm chart, pipeline integrasi berkelanjutan/pengiriman berkelanjutan (CI/CD), dan alat pemantauan. Selain itu, Anda dapat menggunakan platform terpadu untuk menjadwalkan, mengirim, dan mengelola baik pekerjaan HPC maupun beban kerja berbasis kontainer. Dengan cara ini, pekerjaan HPC dan beban kerja berbasis kontainer Kubernetes dapat diterapkan di cluster yang sama untuk memanfaatkan sepenuhnya sumber daya perangkat keras.