Tambahkan instans ECS g8i ke kluster ACK dan gunakan Intel® Extension for PyTorch (IPEX) untuk menjalankan inferensi teks-ke-gambar yang dipercepat perangkat keras pada CPU secara hemat biaya — dengan opsi peningkatan ke VM rahasia Intel® Trust Domain Extensions (Intel® TDX) untuk workload yang memerlukan kerahasiaan data.
Topik ini menggunakan model stabilityai/sdxl-turbo sebagai contoh.
-
Alibaba Cloud tidak menjamin legalitas, keamanan, atau akurasi model pihak ketiga "Stable Diffusion" dan "stabilityai/sdxl-turbo". Alibaba Cloud tidak bertanggung jawab atas kerugian atau kerusakan apa pun yang timbul dari penggunaan model-model tersebut.
-
Patuhi perjanjian pengguna, spesifikasi penggunaan, serta hukum dan peraturan terkait dari model pihak ketiga tersebut. Penggunaan model-model ini sepenuhnya menjadi risiko Anda sendiri.
-
Layanan contoh dalam topik ini hanya untuk pembelajaran, pengujian, dan proof of concept (POC). Semua statistik hanya bersifat referensi. Hasil aktual dapat berbeda tergantung lingkungan Anda.
Kapan menggunakan inferensi CPU
Kombinasi g8i + IPEX + Advanced Matrix Extensions (AMX) merupakan alternatif praktis terhadap inferensi berbasis GPU ketika:
-
Biaya menjadi prioritas utama: Beralih dari
ecs.gn7i-c8g1.2xlarge(GPU) keecs.g8i.4xlargemengurangi biaya instans lebih dari 53%. -
Kebutuhan throughput moderat: Dengan step=4 dan ukuran batch=16,
ecs.g8i.8xlargemenghasilkan 1,2 gambar/detik — melebihi ambang batas 1 gambar/detik untuk banyak workload produksi. -
Diperlukan kerahasiaan data: Migrasikan ke kelompok node VM rahasia TDX tanpa mengubah kode aplikasi.
Jika SLO latensi Anda memerlukan throughput setara GPU (0,4 gambar/detik pada step=30, batch=16), tetap gunakan instans GPU. Jika throughput 1,2 gambar/detik pada pengaturan kualitas optimal (step=4) dapat diterima, g8i menyediakan jalur yang hemat biaya.
Latar Belakang
Keluarga instans g8i
Keluarga instans ECS tujuan umum g8i didukung oleh Cloud Infrastructure Processing Units (CIPUs) dan Apsara Stack. Instans ini menggunakan prosesor Intel® Xeon® Scalable generasi ke-5 (dengan nama kode Emerald Rapids) yang dilengkapi AMX untuk meningkatkan performa AI. Semua instans g8i mendukung Intel® TDX, yang memungkinkan Anda menjalankan workload di Trusted Execution Environment (TEE) tanpa memodifikasi kode aplikasi Anda.
Untuk spesifikasi lengkap, lihat g8i, general-purpose instance family.
Intel® TDX
Intel® TDX adalah teknologi berbasis perangkat keras CPU yang menyediakan isolasi dan enkripsi berbantuan perangkat keras untuk instans ECS, melindungi register CPU, data memori, dan injeksi interupsi saat runtime. Teknologi ini membantu mencegah akses tidak sah ke proses yang sedang berjalan dan data sensitif tanpa memerlukan perubahan kode aplikasi.
Untuk informasi lebih lanjut, lihat Intel® Trust Domain Extensions (Intel® TDX).
IPEX
Intel® Extension for PyTorch (IPEX) adalah ekstensi open source PyTorch yang meningkatkan performa aplikasi AI pada prosesor Intel. Ekstensi ini terus dioptimalkan seiring perkembangan teknologi perangkat keras dan perangkat lunak terbaru dari Intel.
Untuk informasi lebih lanjut, lihat IPEX.
Prasyarat
Sebelum memulai, pastikan Anda telah memiliki:
-
Kluster ACK Pro di wilayah China (Beijing). Untuk informasi lebih lanjut, lihat Create an ACK managed cluster.
-
Kelompok node dengan instans ECS g8i yang memenuhi persyaratan berikut:
-
Tipe instans: Minimal 16 vCPU. Direkomendasikan:
ecs.g8i.4xlarge,ecs.g8i.8xlarge, atauecs.g8i.12xlarge. -
Ruang disk: Minimal 200 GiB per node (disk sistem atau disk data).
-
Wilayah dan zona: Wilayah dan zona tempat instans g8i tersedia. Periksa Instance types available for each region.
-
-
kubectl yang terhubung ke kluster ACK. Untuk informasi lebih lanjut, lihat Connect to an ACK cluster by using kubectl.
Langkah 1: Siapkan model
Penerapan ini menggunakan model stabilityai/sdxl-turbo. Pilih salah satu opsi berikut berdasarkan lokasi penyimpanan model Anda.
Opsi 1: Gunakan model resmi (direkomendasikan)
Gambar Helm chart (v0.1.5) telah menyertakan model resmi stabilityai/sdxl-turbo. Buat file values.yaml dengan konten berikut. Sesuaikan CPU dan memori berdasarkan tipe instans Anda.
resources:
limits:
cpu: "16"
memory: 32Gi
requests:
cpu: "14"
memory: 24GiOpsi 2: Gunakan model kustom dari OSS
Jika Anda menyimpan model kustom stabilityai/sdxl-turbo di Object Storage Service (OSS), pasang model tersebut ke dalam penerapan menggunakan PersistentVolume (PV) dan PersistentVolumeClaim (PVC).
Buat Pengguna Resource Access Management (RAM) dengan izin baca OSS dan dapatkan Pasangan Kunci Aksesnya, lalu ikuti langkah-langkah berikut.
-
Buat file bernama
models-oss-secret.yamldengan konten berikut.apiVersion: v1 kind: Secret metadata: name: models-oss-secret namespace: default stringData: akId: <your-access-key-id> # ID AccessKey dari Pengguna RAM akSecret: <your-access-key-secret> # Rahasia AccessKey dari Pengguna RAM -
Terapkan Secret tersebut.
kubectl create -f models-oss-secret.yamlOutput yang diharapkan:
secret/models-oss-secret created -
Buat file bernama
models-oss-pv.yamldengan konten berikut. Ganti nilai placeholder dengan detail bucket OSS Anda.apiVersion: v1 kind: PersistentVolume metadata: name: models-oss-pv labels: alicloud-pvname: models-oss-pv spec: capacity: storage: 50Gi accessModes: - ReadOnlyMany persistentVolumeReclaimPolicy: Retain csi: driver: ossplugin.csi.alibabacloud.com volumeHandle: models-oss-pv nodePublishSecretRef: name: models-oss-secret namespace: default volumeAttributes: bucket: "<your-bucket-name>" # Bucket OSS yang akan dipasang url: "<your-oss-endpoint>" # Gunakan titik akhir internal, misalnya oss-cn-beijing-internal.aliyuncs.com otherOpts: "-o umask=022 -o max_stat_cache_size=0 -o allow_other" path: "/models" # Harus berisi subdirektori stabilityai/sdxl-turboUntuk detail parameter OSS, lihat Method 1: Use a Secret.
-
Buat PV tersebut.
kubectl create -f models-oss-pv.yamlOutput yang diharapkan:
persistentvolume/models-oss-pv created -
Buat file bernama
models-oss-pvc.yamldengan konten berikut.apiVersion: v1 kind: PersistentVolumeClaim metadata: name: models-oss-pvc spec: accessModes: - ReadOnlyMany resources: requests: storage: 50Gi selector: matchLabels: alicloud-pvname: models-oss-pv -
Terapkan PVC tersebut.
kubectl create -f models-oss-pvc.yamlOutput yang diharapkan:
persistentvolumeclaim/models-oss-pvc created -
Buat file
values.yamlyang mengaktifkan volume model kustom. Sesuaikan resource berdasarkan tipe instans Anda.resources: limits: cpu: "16" memory: 32Gi requests: cpu: "14" memory: 24Gi # Setel ke true untuk memasang model kustom dari OSS alih-alih menggunakan model yang disertakan dalam gambar. useCustomModels: true volumes: models: name: data-volume persistentVolumeClaim: claimName: models-oss-pvc
Referensi values.yaml lengkap
Helm chart mendukung opsi konfigurasi tambahan selain resource dan sumber model. Nilai default lengkapnya adalah:
# Jumlah replika pod.
replicaCount: 1
# Konfigurasi gambar kontainer.
image:
repository: registry-vpc.cn-beijing.aliyuncs.com/eric-dev/stable-diffusion-ipex
pullPolicy: IfNotPresent
tag: "v0.1.5" # Menyertakan model resmi stabilityai/sdxl-turbo
tagOnlyApi: "v0.1.5-lite" # Gambar hanya API; memerlukan pemasangan model manual (lihat useCustomModels)
# Kredensial untuk menarik gambar kontainer privat.
imagePullSecrets: []
# Jalur output untuk gambar yang dihasilkan di dalam kontainer.
outputDirPath: /tmp/sd
# Setel ke true untuk menggunakan model kustom yang dipasang melalui PVC volumes.models.
# Jika false, gambar.image.tag (yang mencakup model) digunakan.
useCustomModels: false
volumes:
# Volume untuk jalur output gambar.
output:
name: output-volume
emptyDir: {}
# Volume untuk model kustom. Hanya aktif saat useCustomModels: true.
# Tempatkan model di subdirektori stabilityai/sdxl-turbo dari jalur pemasangan.
models:
name: data-volume
persistentVolumeClaim:
claimName: models-oss-pvc
# Atau, gunakan jalur host:
# models:
# hostPath:
# path: /data/models
# type: DirectoryOrCreate
# Konfigurasi layanan.
service:
type: ClusterIP
port: 5000
# Batas dan permintaan resource kontainer.
resources:
limits:
cpu: "16"
memory: 32Gi
requests:
cpu: "14"
memory: 24Gi
# Strategi pembaruan workload.
strategy:
type: RollingUpdate
# Konfigurasi penjadwalan.
nodeSelector: {}
tolerations: []
affinity: {}
# Pengaturan keamanan kontainer.
securityContext:
capabilities:
drop:
- ALL
runAsNonRoot: true
runAsUser: 1000
# Konfigurasi Horizontal Pod Autoscaler (HPA).
# https://kubernetes.io/docs/tasks/run-application/horizontal-pod-autoscale/
autoscaling:
enabled: false
minReplicas: 1
maxReplicas: 3
targetCPUUtilizationPercentage: 80
targetMemoryUtilizationPercentage: 90Langkah 2: Terapkan layanan
-
Terapkan layanan Stable Diffusion XL Turbo yang dipercepat IPEX menggunakan Helm.
helm install stable-diffusion-ipex \ https://aliacs-app-catalog.oss-cn-hangzhou.aliyuncs.com/pre/charts-incubator/stable-diffusion-ipex-0.1.7.tgz \ -f values.yamlOutput yang diharapkan:
NAME: stable-diffusion-ipex LAST DEPLOYED: Mon Jan 22 20:42:35 2024 NAMESPACE: default STATUS: deployed REVISION: 1 TEST SUITE: None -
Tunggu sekitar 10 menit hingga model dimuat, lalu verifikasi pod sedang berjalan.
kubectl get pod | grep stable-diffusion-ipexOutput yang diharapkan:
stable-diffusion-ipex-65d98cc78-vmj49 1/1 Running 0 1m44s
Saat pod sedang berjalan, layanan ini mengekspos API teks-ke-gambar pada port 5000. Lihat Referensi API untuk daftar parameter lengkap.
Langkah 3: Uji layanan
-
Teruskan port layanan ke mesin lokal Anda.
kubectl port-forward svc/stable-diffusion-ipex 5000:5000Output yang diharapkan:
Forwarding from 127.0.0.1:5000 -> 5000 Forwarding from [::1]:5000 -> 5000 -
Kirim permintaan pembuatan gambar. Layanan ini mendukung ukuran output
512x512dan1024x1024. Gambar 512x512curl -X POST http://127.0.0.1:5000/api/text2image \ -d '{"prompt": "A panda listening to music with headphones. highly detailed, 8k.", "number": 1}'Output yang diharapkan:
{ "averageImageGenerationTimeSeconds": 2.0333826541900635, "generationTimeSeconds": 2.0333826541900635, "id": "9ae43577-170b-45c9-ab80-69c783b41a70", "meta": { "input": { "batch": 1, "model": "stabilityai/sdxl-turbo", "number": 1, "prompt": "A panda listening to music with headphones. highly detailed, 8k.", "size": "512x512", "step": 4 } }, "output": [ { "latencySeconds": 2.0333826541900635, "url": "http://127.0.0.1:5000/images/9ae43577-170b-45c9-ab80-69c783b41a70/0_0.png" } ], "status": "success" }Gambar 1024x1024
curl -X POST http://127.0.0.1:5000/api/text2image \ -d '{"prompt": "A panda listening to music with headphones. highly detailed, 8k.", "number": 1, "size": "1024x1024"}'Output yang diharapkan:
{ "averageImageGenerationTimeSeconds": 8.635204315185547, "generationTimeSeconds": 8.635204315185547, "id": "ac341ced-430d-4952-b9f9-efa57b4eeb60", "meta": { "input": { "batch": 1, "model": "stabilityai/sdxl-turbo", "number": 1, "prompt": "A panda listening to music with headphones. highly detailed, 8k.", "size": "1024x1024", "step": 4 } }, "output": [ { "latencySeconds": 8.635204315185547, "url": "http://127.0.0.1:5000/images/ac341ced-430d-4952-b9f9-efa57b4eeb60/0_0.png" } ], "status": "success" }Buka nilai
urldi browser untuk melihat gambar yang dihasilkan.
Tolok ukur performa
Tabel berikut menunjukkan waktu pembuatan rata-rata pada berbagai tipe instans g8i (batch: 1, step: 4). Hasil hanya untuk referensi.
| Tipe instans | Permintaan/batas pod (vCPU) | Durasi rata-rata — 512x512 | Durasi rata-rata — 1024x1024 |
|---|---|---|---|
| ecs.g8i.4xlarge (16 vCPU, 64 GiB) | 14/16 | 2,2 dtk | 8,8 dtk |
| ecs.g8i.8xlarge (32 vCPU, 128 GiB) | 24/32 | 1,3 dtk | 4,7 dtk |
| ecs.g8i.12xlarge (48 vCPU, 192 GiB) | 32/32 | 1,1 dtk | 3,9 dtk |
Rekomendasi: ecs.g8i.8xlarge menawarkan keseimbangan terbaik antara biaya dan throughput. Pada step=4, batch=16, instans ini menghasilkan 1,2 gambar/detik — di atas satu gambar per detik tanpa mengorbankan kualitas gambar.
(Opsional) Langkah 4: Migrasikan ke kelompok node VM rahasia TDX
Migrasikan layanan yang telah diterapkan ke kelompok node VM rahasia TDX untuk menambahkan isolasi dan enkripsi memori berbasis perangkat keras. Tidak diperlukan perubahan kode aplikasi.
Prasyarat
Kelompok node VM rahasia TDX sudah ada di kluster ACK dengan konfigurasi berikut:
-
Tipe instans: Minimal 16 vCPU. Direkomendasikan:
ecs.g8i.4xlarge. -
Ruang disk: Minimal 200 GiB per node.
-
Label node:
nodepool-label=tdx-vm-pool.
Untuk instruksi penyiapan, lihat Create a node pool that supports TDX confidential VMs.
Migrasikan layanan
-
Buat file bernama
tdx_values.yamldengan selector node berikut. Gantitdx-vm-pooljika Anda menggunakan nilai label berbeda untuk kelompok node tersebut.nodeSelector: nodepool-label: tdx-vm-pool -
Tingkatkan rilis Helm untuk menjadwalkan ulang pod ke kelompok node TDX.
helm upgrade stable-diffusion-ipex \ https://aliacs-app-catalog.oss-cn-hangzhou.aliyuncs.com/pre/charts-incubator/stable-diffusion-ipex-0.1.7.tgz \ -f tdx_values.yamlOutput yang diharapkan:
Release "stable-diffusion-ipex" has been upgraded. Happy Helming! NAME: stable-diffusion-ipex LAST DEPLOYED: Wed Jan 24 16:38:04 2024 NAMESPACE: default STATUS: deployed REVISION: 2 TEST SUITE: None -
Tunggu sekitar 10 menit, lalu verifikasi pod sedang berjalan di kelompok node TDX.
kubectl get pod | grep stable-diffusion-ipexOutput yang diharapkan:
stable-diffusion-ipex-7f8c4f88f5-r478t 1/1 Running 0 1m44s -
Ulangi Langkah 3: Uji layanan untuk memverifikasi model berfungsi dengan benar di kelompok node TDX.
Referensi API
Setelah penerapan, layanan ini mengekspos REST API pada port 5000.
Sintaksis permintaan
POST /api/text2imageParameter permintaan
Contoh permintaan
Parameter respons
Contoh respons
Perbandingan performa
Kelompok node g8i menggunakan AMX dan IPEX untuk mempercepat inferensi pada CPU. Data berikut dihasilkan pada ecs.g8i.8xlarge (32 vCPU, 128 GiB) menggunakan alat tolok ukur lambda-diffusers. Hasil hanya untuk referensi.
Tolok ukur akselerasi CPU
| Tipe instans | Model | Step | Perintah |
|---|---|---|---|
| ecs.g8i.8xlarge (32 vCPU, 128 GiB) | sdxl-turbo | 4 | python sd_pipe_sdxl_turbo.py --bf16 --batch 1 --height 512 --width 512 --repeat 5 --step 4 --prompt "A panda listening to music with headphones. highly detailed, 8k" |
| ecs.g8i.8xlarge (32 vCPU, 128 GiB) | stable-diffusion-2-1-base | 30 | python sd_pipe_infer.py --model /data/models/stable-diffusion-2-1-base --bf16 --batch 1 --height 512 --width 512 --repeat 5 --step 30 --prompt "A panda listening to music with headphones. highly detailed, 8k" |
Hasil performa (gambar/detik):
| Konfigurasi | Throughput |
|---|---|
| ecs.g8i.8xlarge, step=4, batch=16 (sdxl-turbo) | 1,2 gambar/detik |
| ecs.g8i.8xlarge, step=30, batch=16 (sd-2-1-base) | 0,14 gambar/detik |
Tolok ukur akselerasi GPU
Data tolok ukur GPU bersumber dari Lambda Diffusers Benchmarking inference. Hasil aktual dapat berbeda.
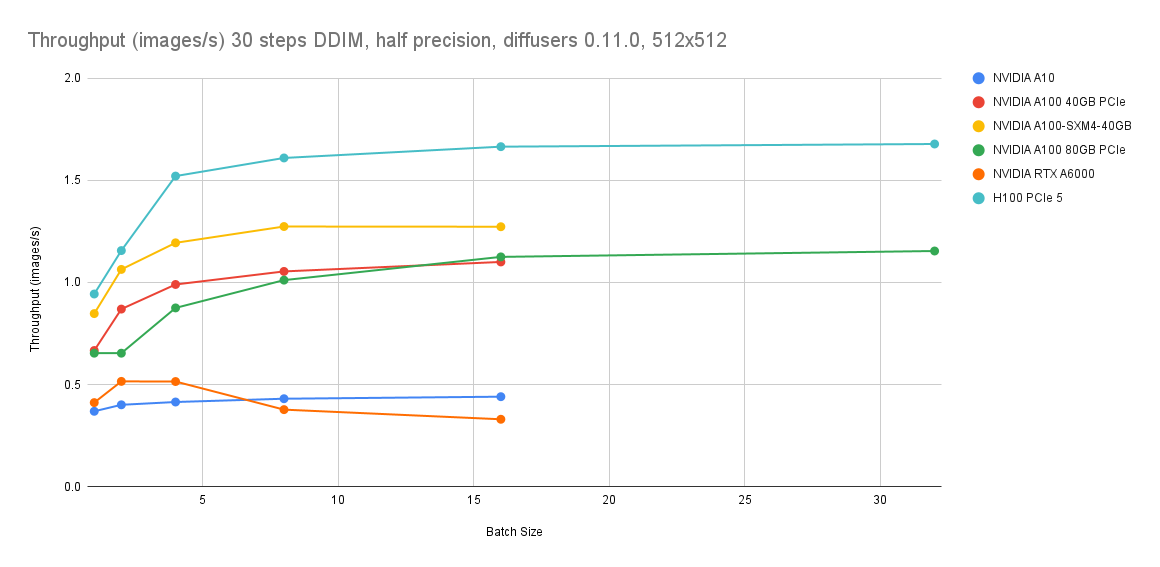
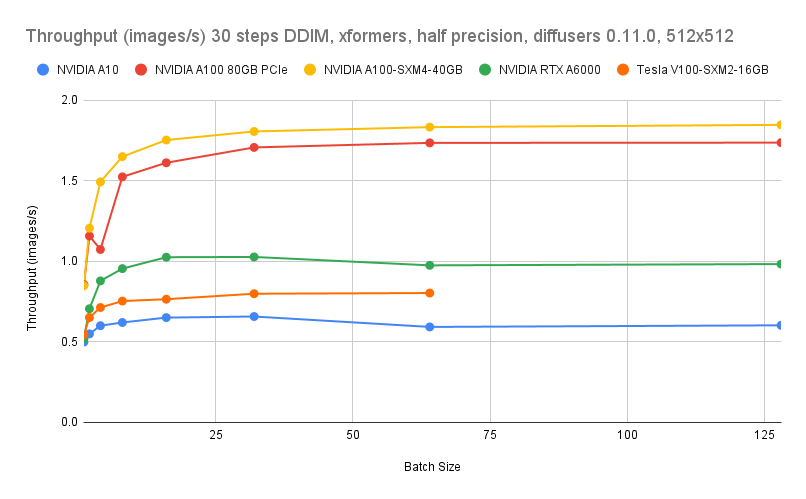
Perbandingan biaya
Estimasi berikut membandingkan instans CPU g8i dengan ecs.gn7i-c8g1.2xlarge (GPU). Untuk harga terkini, lihat tab Pricing di halaman Elastic Compute Service.
| Tipe instans | Biaya vs. ecs.gn7i-c8g1.2xlarge | Throughput pada step=4, batch=16 |
|---|---|---|
| ecs.g8i.8xlarge | 9% lebih rendah | 1,2 gambar/detik |
| ecs.g8i.4xlarge | >53% lebih rendah | 0,5 gambar/detik |
Gunakan ecs.g8i.8xlarge ketika Anda membutuhkan penghematan biaya sekaligus throughput di atas 1 gambar/detik. Gunakan ecs.g8i.4xlarge ketika pengurangan biaya menjadi tujuan utama dan 0,5 gambar/detik memenuhi kebutuhan Anda.