Beban kerja pelatihan terdistribusi yang tersebar di beberapa node GPU mengalami overhead komunikasi antarnode yang signifikan selama sinkronisasi gradien. ACK mendukung penjadwalan GPU yang sadar topologi berdasarkan framework penjadwalan, yang memilih GPU berdasarkan topologi interkoneksi fisiknya—menempatkan worker pada GPU yang berbagi koneksi NVLink ber-bandwidth tinggi—untuk mengurangi overhead tersebut dan memaksimalkan throughput pelatihan. Topik ini menjelaskan cara menerapkan penjadwalan GPU yang sadar topologi pada pekerjaan pelatihan terdistribusi TensorFlow dan membandingkan hasilnya dengan penjadwalan GPU biasa.
Prasyarat
Sebelum memulai, pastikan Anda telah:
Membuat kluster ACK Pro dengan tipe instans diatur ke Elastic GPU Service. Lihat Create an ACK managed cluster.
Arena telah terinstal.
Komponen penjadwalan GPU yang sadar topologi telah terinstal
Memastikan versi komponen memenuhi persyaratan berikut:
| Component | Required version | Check command |
|---|---|---|
| Kubernetes | 1.18.8 dan yang lebih baru | kubectl version --short |
| NVIDIA driver | 418.87.01 dan yang lebih baru | nvidia-smi --query-gpu=driver_version --format=csv,noheader |
| NCCL (NVIDIA Collective Communications Library) | 2.7 dan yang lebih baru | python3 -c "import torch; print(torch.cuda.nccl.version())" |
| Operating system | CentOS 7.6, CentOS 7.7, Ubuntu 16.04, Ubuntu 18.04, Alibaba Cloud Linux 2, Alibaba Cloud Linux 3 | cat /etc/os-release |
| GPU | V100 | nvidia-smi --query-gpu=name --format=csv,noheader |
Lengkapi prasyarat secara berurutan: buat kluster ACK Pro terlebih dahulu, lalu instal Arena, dan akhirnya instal komponen penjadwalan GPU yang sadar topologi. Menginstal komponen tidak sesuai urutan dapat menyebabkan kegagalan.
Batasan
Penjadwalan GPU yang sadar topologi hanya berlaku untuk pekerjaan Message Passing Interface (MPI) yang dilatih dengan framework terdistribusi.
Penjadwalan GPU biasa menetapkan GPU hanya berdasarkan ketersediaan, tanpa mempertimbangkan topologi interkoneksi fisik. Hal ini berarti worker dapat ditempatkan pada GPU di node berbeda yang hanya terhubung melalui tautan jaringan yang lebih lambat, sehingga komunikasi antar-GPU menjadi bottleneck utama. Penjadwalan yang sadar topologi mengatasi hal ini dengan mengelompokkan worker pada GPU yang berbagi koneksi NVLink dalam satu node yang sama, sehingga secara signifikan mengurangi latensi sinkronisasi gradien.
Pod hanya dibuat ketika semua sumber daya yang diminta dapat dipenuhi secara bersamaan (gang scheduling). Jika sumber daya tidak mencukupi, pekerjaan akan tetap dalam status pending hingga GPU yang cukup tersedia.
Konfigurasi node
Beri label setiap node untuk mengaktifkan penjadwalan GPU yang sadar topologi:
kubectl label node <your-node-name> ack.node.gpu.schedule=topologyMengaktifkan penjadwalan yang sadar topologi pada suatu node akan menonaktifkan penjadwalan GPU biasa untuk node tersebut. Untuk kembali ke penjadwalan GPU biasa, jalankan:
kubectl label node <your-node-name> ack.node.gpu.schedule=default --overwriteKirim pekerjaan
Kirim pekerjaan MPI dengan --gputopology=true dan --gang:
arena submit mpi --gputopology=true --gang <other-parameters>Kedua flag wajib digunakan: --gputopology=true mengaktifkan pemilihan GPU yang sadar topologi, dan --gang memberlakukan gang scheduling agar semua worker dimulai secara bersamaan.
Contoh 1: Latih VGG16
Kluster pada contoh ini memiliki dua node, masing-masing dengan delapan GPU V100.
Penjadwalan GPU yang sadar topologi
Kirim pekerjaan pelatihan:
arena submit mpi \ --name=tensorflow-topo-4-vgg16 \ --gpus=1 \ --workers=4 \ --gang \ --gputopology=true \ --image=registry.cn-hangzhou.aliyuncs.com/kubernetes-image-hub/tensorflow-benchmark:tf2.3.0-py3.7-cuda10.1 \ "mpirun --allow-run-as-root -np 4 -bind-to none -map-by slot -x NCCL_DEBUG=INFO -x NCCL_SOCKET_IFNAME=eth0 -x LD_LIBRARY_PATH -x PATH --mca pml ob1 --mca btl_tcp_if_include eth0 --mca oob_tcp_if_include eth0 --mca orte_keep_fqdn_hostnames t --mca btl ^openib python /tensorflow/benchmarks/scripts/tf_cnn_benchmarks/tf_cnn_benchmarks.py --model=vgg16 --batch_size=64 --variable_update=horovod"Periksa status pekerjaan:
arena get tensorflow-topo-4-vgg16 --type mpijobOutput yang diharapkan:
Name: tensorflow-topo-4-vgg16 Status: RUNNING Namespace: default Priority: N/A Trainer: MPIJOB Duration: 2m Instances: NAME STATUS AGE IS_CHIEF GPU(Requested) NODE ---- ------ --- -------- -------------- ---- tensorflow-topo-4-vgg16-launcher-lmhjl Running 2m true 0 cn-shanghai.192.168.16.172 tensorflow-topo-4-vgg16-worker-0 Running 2m false 1 cn-shanghai.192.168.16.173 tensorflow-topo-4-vgg16-worker-1 Running 2m false 1 cn-shanghai.192.168.16.173 tensorflow-topo-4-vgg16-worker-2 Running 2m false 1 cn-shanghai.192.168.16.173 tensorflow-topo-4-vgg16-worker-3 Running 2m false 1 cn-shanghai.192.168.16.173Keempat worker ditempatkan pada node yang sama, berbagi interkoneksi GPU ber-bandwidth tinggi.
Lihat log pelatihan:
arena logs -f tensorflow-topo-4-vgg16Output yang diharapkan:
total images/sec: 991.92
Penjadwalan GPU biasa
Kirim pekerjaan pelatihan tanpa flag topologi:
arena submit mpi \ --name=tensorflow-4-vgg16 \ --gpus=1 \ --workers=4 \ --image=registry.cn-hangzhou.aliyuncs.com/kubernetes-image-hub/tensorflow-benchmark:tf2.3.0-py3.7-cuda10.1 \ "mpirun --allow-run-as-root -np 4 -bind-to none -map-by slot -x NCCL_DEBUG=INFO -x NCCL_SOCKET_IFNAME=eth0 -x LD_LIBRARY_PATH -x PATH --mca pml ob1 --mca btl_tcp_if_include eth0 --mca oob_tcp_if_include eth0 --mca orte_keep_fqdn_hostnames t --mca btl ^openib python /tensorflow/benchmarks/scripts/tf_cnn_benchmarks/tf_cnn_benchmarks.py --model=vgg16 --batch_size=64 --variable_update=horovod"Periksa status pekerjaan:
arena get tensorflow-4-vgg16 --type mpijobOutput yang diharapkan:
Name: tensorflow-4-vgg16 Status: RUNNING Namespace: default Priority: N/A Trainer: MPIJOB Duration: 9s Instances: NAME STATUS AGE IS_CHIEF GPU(Requested) NODE ---- ------ --- -------- -------------- ---- tensorflow-4-vgg16-launcher-xc28k Running 9s true 0 cn-shanghai.192.168.16.172 tensorflow-4-vgg16-worker-0 Running 9s false 1 cn-shanghai.192.168.16.172 tensorflow-4-vgg16-worker-1 Running 9s false 1 cn-shanghai.192.168.16.173 tensorflow-4-vgg16-worker-2 Running 9s false 1 cn-shanghai.192.168.16.172 tensorflow-4-vgg16-worker-3 Running 9s false 1 cn-shanghai.192.168.16.173Worker tersebar di dua node, sehingga memerlukan komunikasi antarnode pada setiap langkah sinkronisasi gradien.
Lihat log pelatihan:
arena logs -f tensorflow-4-vgg16Output yang diharapkan:
total images/sec: 200.47
Contoh 2: Latih ResNet50
Penjadwalan GPU yang sadar topologi
Kirim pekerjaan pelatihan:
arena submit mpi \ --name=tensorflow-topo-4-resnet50 \ --gpus=1 \ --workers=4 \ --gang \ --gputopology=true \ --image=registry.cn-hangzhou.aliyuncs.com/kubernetes-image-hub/tensorflow-benchmark:tf2.3.0-py3.7-cuda10.1 \ "mpirun --allow-run-as-root -np 4 -bind-to none -map-by slot -x NCCL_DEBUG=INFO -x NCCL_SOCKET_IFNAME=eth0 -x LD_LIBRARY_PATH -x PATH --mca pml ob1 --mca btl_tcp_if_include eth0 --mca oob_tcp_if_include eth0 --mca orte_keep_fqdn_hostnames t --mca btl ^openib python /tensorflow/benchmarks/scripts/tf_cnn_benchmarks/tf_cnn_benchmarks.py --model=resnet50 --batch_size=64 --variable_update=horovod"Periksa status pekerjaan:
arena get tensorflow-topo-4-resnet50 --type mpijobOutput yang diharapkan:
Name: tensorflow-topo-4-resnet50 Status: RUNNING Namespace: default Priority: N/A Trainer: MPIJOB Duration: 8s Instances: NAME STATUS AGE IS_CHIEF GPU(Requested) NODE ---- ------ --- -------- -------------- ---- tensorflow-topo-4-resnet50-launcher-7ln8j Running 8s true 0 cn-shanghai.192.168.16.172 tensorflow-topo-4-resnet50-worker-0 Running 8s false 1 cn-shanghai.192.168.16.173 tensorflow-topo-4-resnet50-worker-1 Running 8s false 1 cn-shanghai.192.168.16.173 tensorflow-topo-4-resnet50-worker-2 Running 8s false 1 cn-shanghai.192.168.16.173 tensorflow-topo-4-resnet50-worker-3 Running 8s false 1 cn-shanghai.192.168.16.173Lihat log pelatihan:
arena logs -f tensorflow-topo-4-resnet50Output yang diharapkan:
total images/sec: 1471.55
Penjadwalan GPU biasa
Kirim pekerjaan pelatihan tanpa flag topologi:
arena submit mpi \ --name=tensorflow-4-resnet50 \ --gpus=1 \ --workers=4 \ --image=registry.cn-hangzhou.aliyuncs.com/kubernetes-image-hub/tensorflow-benchmark:tf2.3.0-py3.7-cuda10.1 \ "mpirun --allow-run-as-root -np 4 -bind-to none -map-by slot -x NCCL_DEBUG=INFO -x NCCL_SOCKET_IFNAME=eth0 -x LD_LIBRARY_PATH -x PATH --mca pml ob1 --mca btl_tcp_if_include eth0 --mca oob_tcp_if_include eth0 --mca orte_keep_fqdn_hostnames t --mca btl ^openib python /tensorflow/benchmarks/scripts/tf_cnn_benchmarks/tf_cnn_benchmarks.py --model=resnet50 --batch_size=64 --variable_update=horovod"Periksa status pekerjaan:
arena get tensorflow-4-resnet50 --type mpijobOutput yang diharapkan:
Name: tensorflow-4-resnet50 Status: RUNNING Namespace: default Priority: N/A Trainer: MPIJOB Duration: 9s Instances: NAME STATUS AGE IS_CHIEF GPU(Requested) NODE ---- ------ --- -------- -------------- ---- tensorflow-4-resnet50-launcher-q24hv Running 9s true 0 cn-shanghai.192.168.16.172 tensorflow-4-resnet50-worker-0 Running 9s false 1 cn-shanghai.192.168.16.172 tensorflow-4-resnet50-worker-1 Running 9s false 1 cn-shanghai.192.168.16.173 tensorflow-4-resnet50-worker-2 Running 9s false 1 cn-shanghai.192.168.16.172 tensorflow-4-resnet50-worker-3 Running 9s false 1 cn-shanghai.192.168.16.173Lihat log pelatihan:
arena logs -f tensorflow-4-resnet50Output yang diharapkan:
total images/sec: 745.38
Perbandingan performa
Grafik berikut menunjukkan throughput pelatihan VGG16 dan ResNet50 dengan penjadwalan GPU yang sadar topologi dan penjadwalan GPU biasa.
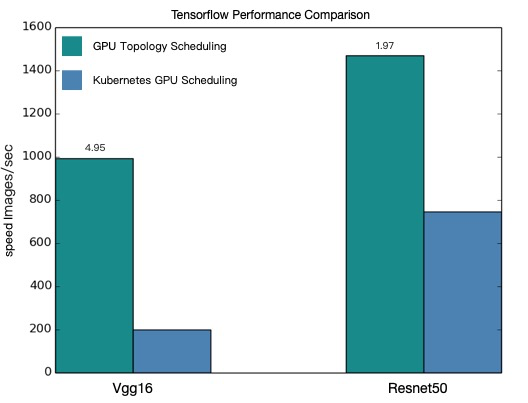
| Model | Sadar topologi (images/sec) | Biasa (images/sec) | Peningkatan |
|---|---|---|---|
| VGG16 | 991.92 | 200.47 | ~4.9x |
| ResNet50 | 1471.55 | 745.38 | ~2.0x |
Nilai performa dalam topik ini merupakan nilai teoretis. Hasil aktual bervariasi tergantung pada arsitektur model, konfigurasi kluster, dan kondisi jaringan Anda. Jalankan contoh di atas pada kluster Anda sendiri untuk mengukur peningkatan aktual.