Penjadwalan GPU yang sadar topologi memilih kombinasi GPU optimal dari node berakselerasi GPU untuk meminimalkan overhead komunikasi antar worker. Fitur ini diimplementasikan oleh ACK menggunakan Kubernetes Scheduling Framework, sehingga efektif untuk pekerjaan pelatihan terdistribusi yang bergantung pada interkoneksi GPU berbandwidth tinggi.
Topik ini menjelaskan cara mengaktifkan penjadwalan GPU yang sadar topologi di ACK dan menjalankan pekerjaan pelatihan terdistribusi PyTorch menggunakan Arena.
Prasyarat
Sebelum memulai, pastikan Anda telah memiliki:
-
Kluster ACK Pro. Lihat Buat kluster ACK Pro
-
Arena yang telah diinstal. Lihat Repositori GitHub Arena
-
ack-ai-installer yang telah diinstal. Lihat Instal ack-ai-installer
-
Node yang memenuhi persyaratan versi berikut:
Komponen Versi yang dibutuhkan Kubernetes V1.18.8 dan yang lebih baru Helm 3.0 dan yang lebih baru Nvidia 418.87.01 dan yang lebih baru NVIDIA Collective Communications Library (NCCL) 2.7+ Docker 19.03.5 OS CentOS 7.6, CentOS 7.7, Ubuntu 16.04 dan 18.04, serta Alibaba Cloud Linux 2 GPU V100
Batasan
-
Penjadwalan GPU yang sadar topologi hanya berlaku untuk pekerjaan Message Passing Interface (MPI) yang dilatih dengan framework terdistribusi.
-
Semua Pod dalam suatu pekerjaan harus dapat dijadwalkan secara bersamaan sebelum pekerjaan dimulai. Jika sumber daya tidak mencukupi, pekerjaan akan tetap dalam status pending hingga semua sumber daya yang diminta tersedia.
Langkah 1: Beri label node untuk penjadwalan yang sadar topologi
Tambahkan label ack.node.gpu.schedule=topology ke setiap node tempat Anda ingin mengaktifkan penjadwalan yang sadar topologi:
kubectl label node <your-node-name> ack.node.gpu.schedule=topologyNode yang diberi label untuk penjadwalan yang sadar topologi tidak dapat menggunakan penjadwalan GPU biasa secara bersamaan. Untuk mengembalikan node ke penjadwalan GPU biasa, jalankan:
kubectl label node <your-node-name> ack.node.gpu.schedule=default --overwriteLangkah 2: Kirim pekerjaan pelatihan terdistribusi
Kirim pekerjaan MPI dengan kedua flag --gputopology=true dan --gang. Flag --gang mengaktifkan gang scheduling, yang memastikan semua worker dialokasikan secara bersamaan—mencegah deadlock ketika node memiliki jumlah GPU yang terbatas.
arena submit mpi --gputopology=true --gang <other-flags>(Opsional) Contoh benchmark dan perbandingan performa
Contoh berikut membandingkan throughput antara penjadwalan GPU yang sadar topologi dan penjadwalan GPU biasa menggunakan model VGG16 dan ResNet50. Lingkungan pengujian menggunakan dua server, masing-masing dengan delapan GPU V100. Jalankan benchmark ini di lingkungan Anda sendiri untuk mengevaluasi peningkatan performa bagi beban kerja Anda.
Latih VGG16 dengan penjadwalan yang sadar topologi
-
Kirim pekerjaan:
arena submit mpi \ --name=pytorch-topo-4-vgg16 \ --gpus=1 \ --workers=4 \ --gang \ --gputopology=true \ --image=registry.cn-hangzhou.aliyuncs.com/kubernetes-image-hub/pytorch-benchmark:torch1.6.0-py3.7-cuda10.1 \ "mpirun --allow-run-as-root -np "4" -bind-to none -map-by slot -x NCCL_DEBUG=INFO -x NCCL_SOCKET_IFNAME=eth0 -x LD_LIBRARY_PATH -x PATH --mca pml ob1 --mca btl_tcp_if_include eth0 --mca oob_tcp_if_include eth0 --mca orte_keep_fqdn_hostnames t --mca btl ^openib python /examples/pytorch_synthetic_benchmark.py --model=vgg16 --batch-size=64" -
Periksa status pekerjaan:
arena get pytorch-topo-4-vgg16 --type mpijobOutput yang diharapkan:
Name: pytorch-topo-4-vgg16 Status: RUNNING Namespace: default Priority: N/A Trainer: MPIJOB Duration: 11s Instances: NAME STATUS AGE IS_CHIEF GPU(Requested) NODE ---- ------ --- -------- -------------- ---- pytorch-topo-4-vgg16-launcher-mnjzr Running 11s true 0 cn-shanghai.192.168.16.173 pytorch-topo-4-vgg16-worker-0 Running 11s false 1 cn-shanghai.192.168.16.173 pytorch-topo-4-vgg16-worker-1 Running 11s false 1 cn-shanghai.192.168.16.173 pytorch-topo-4-vgg16-worker-2 Running 11s false 1 cn-shanghai.192.168.16.173 pytorch-topo-4-vgg16-worker-3 Running 11s false 1 cn-shanghai.192.168.16.173 -
Lihat log pekerjaan:
arena logs -f pytorch-topo-4-vgg16Output yang diharapkan:
Model: vgg16 Batch size: 64 Number of GPUs: 4 Running warmup... Running benchmark... Iter #0: 205.5 img/sec per GPU Iter #1: 205.2 img/sec per GPU Iter #2: 205.1 img/sec per GPU Iter #3: 205.5 img/sec per GPU Iter #4: 205.1 img/sec per GPU Iter #5: 205.1 img/sec per GPU Iter #6: 205.3 img/sec per GPU Iter #7: 204.3 img/sec per GPU Iter #8: 205.0 img/sec per GPU Iter #9: 204.9 img/sec per GPU Img/sec per GPU: 205.1 +-0.6 Total img/sec on 4 GPU(s): 820.5 +-2.5
Latih VGG16 dengan penjadwalan GPU biasa
-
Kirim pekerjaan:
arena submit mpi \ --name=pytorch-4-vgg16 \ --gpus=1 \ --workers=4 \ --image=registry.cn-hangzhou.aliyuncs.com/kubernetes-image-hub/pytorch-benchmark:torch1.6.0-py3.7-cuda10.1 \ "mpirun --allow-run-as-root -np "4" -bind-to none -map-by slot -x NCCL_DEBUG=INFO -x NCCL_SOCKET_IFNAME=eth0 -x LD_LIBRARY_PATH -x PATH --mca pml ob1 --mca btl_tcp_if_include eth0 --mca oob_tcp_if_include eth0 --mca orte_keep_fqdn_hostnames t --mca btl ^openib python /examples/pytorch_synthetic_benchmark.py --model=vgg16 --batch-size=64" -
Periksa status pekerjaan:
arena get pytorch-4-vgg16 --type mpijobOutput yang diharapkan:
Name: pytorch-4-vgg16 Status: RUNNING Namespace: default Priority: N/A Trainer: MPIJOB Duration: 10s Instances: NAME STATUS AGE IS_CHIEF GPU(Requested) NODE ---- ------ --- -------- -------------- ---- pytorch-4-vgg16-launcher-qhnxl Running 10s true 0 cn-shanghai.192.168.16.173 pytorch-4-vgg16-worker-0 Running 10s false 1 cn-shanghai.192.168.16.173 pytorch-4-vgg16-worker-1 Running 10s false 1 cn-shanghai.192.168.16.173 pytorch-4-vgg16-worker-2 Running 10s false 1 cn-shanghai.192.168.16.173 pytorch-4-vgg16-worker-3 Running 10s false 1 cn-shanghai.192.168.16.173 -
Lihat log pekerjaan:
arena logs -f pytorch-4-vgg16Output yang diharapkan:
Model: vgg16 Batch size: 64 Number of GPUs: 4 Running warmup... Running benchmark... Iter #0: 113.1 img/sec per GPU Iter #1: 109.5 img/sec per GPU Iter #2: 106.5 img/sec per GPU Iter #3: 108.5 img/sec per GPU Iter #4: 108.1 img/sec per GPU Iter #5: 111.2 img/sec per GPU Iter #6: 110.7 img/sec per GPU Iter #7: 109.8 img/sec per GPU Iter #8: 102.8 img/sec per GPU Iter #9: 107.9 img/sec per GPU Img/sec per GPU: 108.8 +-5.3 Total img/sec on 4 GPU(s): 435.2 +-21.1
Latih ResNet50 dengan penjadwalan yang sadar topologi
-
Kirim pekerjaan:
arena submit mpi \ --name=pytorch-topo-4-resnet50 \ --gpus=1 \ --workers=4 \ --gang \ --gputopology=true \ --image=registry.cn-hangzhou.aliyuncs.com/kubernetes-image-hub/pytorch-benchmark:torch1.6.0-py3.7-cuda10.1 \ "mpirun --allow-run-as-root -np "4" -bind-to none -map-by slot -x NCCL_DEBUG=INFO -x NCCL_SOCKET_IFNAME=eth0 -x LD_LIBRARY_PATH -x PATH --mca pml ob1 --mca btl_tcp_if_include eth0 --mca oob_tcp_if_include eth0 --mca orte_keep_fqdn_hostnames t --mca btl ^openib python /examples/pytorch_synthetic_benchmark.py --model=resnet50 --batch-size=64" -
Periksa status pekerjaan:
arena get pytorch-topo-4-resnet50 --type mpijobOutput yang diharapkan:
Name: pytorch-topo-4-resnet50 Status: RUNNING Namespace: default Priority: N/A Trainer: MPIJOB Duration: 8s Instances: NAME STATUS AGE IS_CHIEF GPU(Requested) NODE ---- ------ --- -------- -------------- ---- pytorch-topo-4-resnet50-launcher-x7r2n Running 8s true 0 cn-shanghai.192.168.16.173 pytorch-topo-4-resnet50-worker-0 Running 8s false 1 cn-shanghai.192.168.16.173 pytorch-topo-4-resnet50-worker-1 Running 8s false 1 cn-shanghai.192.168.16.173 pytorch-topo-4-resnet50-worker-2 Running 8s false 1 cn-shanghai.192.168.16.173 pytorch-topo-4-resnet50-worker-3 Running 8s false 1 cn-shanghai.192.168.16.173 -
Lihat log pekerjaan:
arena logs -f pytorch-topo-4-resnet50Output yang diharapkan:
Model: resnet50 Batch size: 64 Number of GPUs: 4 Running warmup... Running benchmark... Iter #0: 331.0 img/sec per GPU Iter #1: 330.6 img/sec per GPU Iter #2: 330.9 img/sec per GPU Iter #3: 330.4 img/sec per GPU Iter #4: 330.7 img/sec per GPU Iter #5: 330.8 img/sec per GPU Iter #6: 329.9 img/sec per GPU Iter #7: 330.5 img/sec per GPU Iter #8: 330.4 img/sec per GPU Iter #9: 329.7 img/sec per GPU Img/sec per GPU: 330.5 +-0.8 Total img/sec on 4 GPU(s): 1321.9 +-3.2
Latih ResNet50 dengan penjadwalan GPU biasa
-
Kirim pekerjaan:
arena submit mpi \ --name=pytorch-4-resnet50 \ --gpus=1 \ --workers=4 \ --image=registry.cn-hangzhou.aliyuncs.com/kubernetes-image-hub/pytorch-benchmark:torch1.6.0-py3.7-cuda10.1 \ "mpirun --allow-run-as-root -np "4" -bind-to none -map-by slot -x NCCL_DEBUG=INFO -x NCCL_SOCKET_IFNAME=eth0 -x LD_LIBRARY_PATH -x PATH --mca pml ob1 --mca btl_tcp_if_include eth0 --mca oob_tcp_if_include eth0 --mca orte_keep_fqdn_hostnames t --mca btl ^openib python /examples/pytorch_synthetic_benchmark.py --model=resnet50 --batch-size=64" -
Periksa status pekerjaan:
arena get pytorch-4-resnet50 --type mpijobOutput yang diharapkan:
Name: pytorch-4-resnet50 Status: RUNNING Namespace: default Priority: N/A Trainer: MPIJOB Duration: 10s Instances: NAME STATUS AGE IS_CHIEF GPU(Requested) NODE ---- ------ --- -------- -------------- ---- pytorch-4-resnet50-launcher-qw5k6 Running 10s true 0 cn-shanghai.192.168.16.173 pytorch-4-resnet50-worker-0 Running 10s false 1 cn-shanghai.192.168.16.173 pytorch-4-resnet50-worker-1 Running 10s false 1 cn-shanghai.192.168.16.173 pytorch-4-resnet50-worker-2 Running 10s false 1 cn-shanghai.192.168.16.173 pytorch-4-resnet50-worker-3 Running 10s false 1 cn-shanghai.192.168.16.173 -
Lihat log pekerjaan:
arena logs -f pytorch-4-resnet50Output yang diharapkan:
Model: resnet50 Batch size: 64 Number of GPUs: 4 Running warmup... Running benchmark... Iter #0: 313.1 img/sec per GPU Iter #1: 312.8 img/sec per GPU Iter #2: 313.0 img/sec per GPU Iter #3: 312.2 img/sec per GPU Iter #4: 313.7 img/sec per GPU Iter #5: 313.2 img/sec per GPU Iter #6: 313.6 img/sec per GPU Iter #7: 313.0 img/sec per GPU Iter #8: 311.3 img/sec per GPU Iter #9: 313.6 img/sec per GPU Img/sec per GPU: 313.0 +-1.3 Total img/sec on 4 GPU(s): 1251.8 +-5.3
Perbandingan performa
Gambar berikut membandingkan throughput antara penjadwalan GPU yang sadar topologi dan penjadwalan GPU biasa untuk kedua model tersebut.
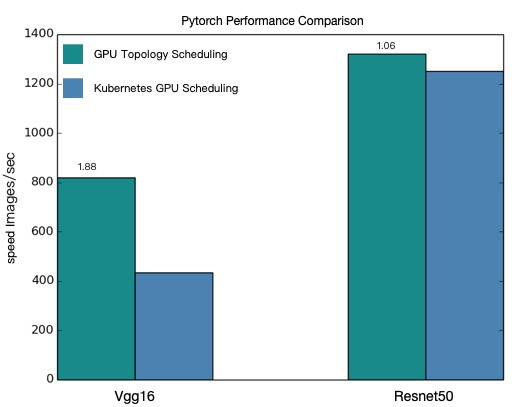
Penjadwalan GPU yang sadar topologi memberikan throughput lebih tinggi untuk pekerjaan pelatihan terdistribusi VGG16 maupun ResNet50.
Nilai performa dalam topik ini merupakan nilai teoretis. Performa penjadwalan GPU yang sadar topologi bervariasi tergantung pada arsitektur model dan konfigurasi kluster Anda. Gunakan statistik performa aktual yang berlaku.