Container Service for Kubernetes (ACK) mendukung penjadwalan dan operasi GPU. Mode penggunaan GPU default-nya mengikuti pola komunitas Kubernetes hulu. Topik ini memandu Anda dalam menerapkan workload TensorFlow contoh untuk memvalidasi penjadwalan GPU.
Prasyarat
Pastikan Anda memiliki:
-
Kluster ACK dengan setidaknya satu node GPU
-
kubectl yang telah dikonfigurasi untuk terhubung ke kluster
-
Akses ke Konsol ACK
Hindari melewati permintaan sumber daya GPU standar
Untuk node GPU yang dikelola ACK, mintalah sumber daya GPU hanya melalui mekanisme sumber daya ekstensi Kubernetes standar (nvidia.com/gpu dalam resources.limits). Tindakan berikut melewati mekanisme ini dan menimbulkan risiko keamanan:
-
Menjalankan aplikasi GPU secara langsung di node
-
Menggunakan
docker,podman, ataunerdctluntuk membuat kontainer atau meminta sumber daya GPU (misalnya,docker run --gpus allataudocker run -e NVIDIA_VISIBLE_DEVICES=all) -
Menambahkan
NVIDIA_VISIBLE_DEVICES=allatauNVIDIA_VISIBLE_DEVICES=<GPU ID>ke bagianenvfile YAML Pod -
Menggunakan variabel lingkungan
NVIDIA_VISIBLE_DEVICESuntuk meminta sumber daya GPU bagi sebuah Pod -
Menetapkan nilai default
NVIDIA_VISIBLE_DEVICESmenjadialldalam gambar kontainer jika tidak diatur dalam file YAML Pod -
Menyetel
privileged: truedalamsecurityContextPod dan menjalankan program GPU
Mengapa ini penting: Permintaan GPU non-standar tidak terlihat oleh pelacakan sumber daya penjadwal. Ketidaksesuaian ini dapat menyebabkan penjadwal mengalokasikan GPU secara berlebihan pada suatu node, sehingga beberapa Pod bersaing untuk kartu GPU yang sama (misalnya, bersaing untuk memori GPU) dan menyebabkan kegagalan workload. Metode-metode ini juga dapat memicu error yang dilaporkan komunitas NVIDIA.
Verifikasi ketersediaan GPU
Sebelum menerapkan workload, pastikan node GPU Anda mengekspos kapasitas GPU ke penjadwal Kubernetes.
-
Tampilkan daftar node dalam kluster:
kubectl get nodes -
Jelaskan detail node GPU untuk memeriksa kapasitasnya:
kubectl describe node <gpu-node-name>Dalam bagian Capacity,
nvidia.com/gpuharus menunjukkan nilai bukan nol:Capacity: nvidia.com/gpu: 1Jika
nvidia.com/gputidak ada atau menunjukkan0, plugin perangkat NVIDIA mungkin tidak berjalan di node tersebut. Periksa penerapan DaemonSet plugin, driver GPU, dan konfigurasi node sebelum melanjutkan.
Terapkan aplikasi GPU
-
Masuk ke Konsol ACK. Di panel navigasi kiri, klik Clusters.
-
Di halaman Clusters, klik kluster target. Di panel navigasi kiri, pilih Workloads > Deployments.
-
Di halaman Deployments, klik Create from YAML dan tempel manifes berikut:
apiVersion: v1 kind: Pod metadata: name: tensorflow-mnist namespace: default spec: containers: - image: registry.cn-beijing.aliyuncs.com/acs/tensorflow-mnist-sample:v1.5 name: tensorflow-mnist command: - python - tensorflow-sample-code/tfjob/docker/mnist/main.py - --max_steps=100000 - --data_dir=tensorflow-sample-code/data resources: limits: nvidia.com/gpu: 1 # Meminta satu kartu GPU untuk kontainer ini. workingDir: /root restartPolicy: AlwaysSumber daya ekstensi GPU hanya memerlukan
limits, bukanrequests. Kubernetes tidak mengizinkanrequeststanpalimitsyang sesuai untuk sumber daya ekstensi. Penjadwal menggunakan nilailimitssebagai permintaan efektif. -
Di panel navigasi kiri, pilih Workloads > Pods. Temukan dan klik Pod tersebut.
-
Klik tab Logs. Proses pull gambar dan startup Pod mungkin memerlukan beberapa menit. Setelah berjalan, output log mengonfirmasi bahwa penjadwalan GPU berfungsi dengan benar.
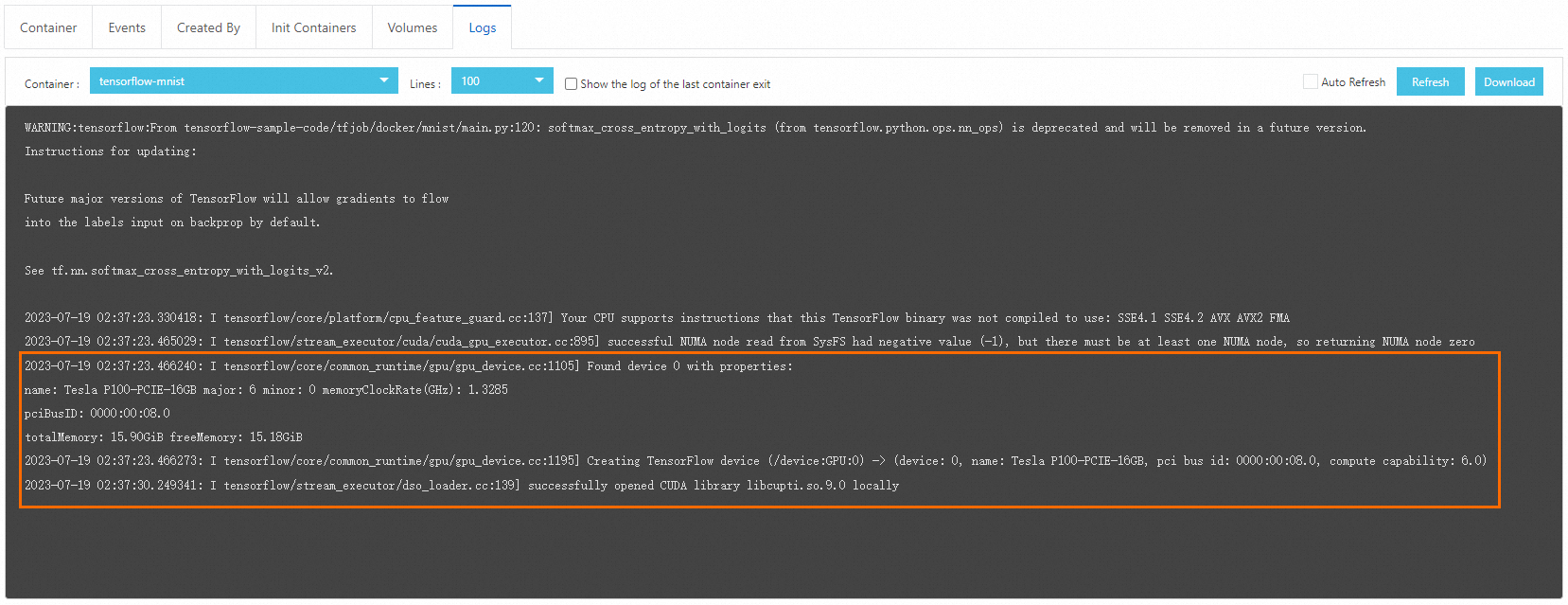
Langkah selanjutnya
-
Untuk menargetkan jenis GPU tertentu dalam kluster heterogen, gunakan label node dan selector. Beri label node GPU berdasarkan tipe akselerator (misalnya,
kubectl label nodes <node-name> accelerator=<gpu-model>), lalu tambahkannodeSelectorke spesifikasi Pod Anda. -
Untuk opsi penjadwalan GPU lanjutan seperti berbagi dan isolasi GPU, lihat dokumentasi penjadwalan GPU ACK.