AHPA menggunakan data pemanfaatan GPU dari Prometheus Adapter, dikombinasikan dengan tren beban historis dan algoritma prediksi, untuk memperkirakan kebutuhan sumber daya GPU di masa depan. AHPA secara otomatis menyesuaikan jumlah replika pod atau mengalokasikan sumber daya GPU untuk melakukan scale-out sebelum sumber daya GPU menjadi terkendala, serta melakukan scale-in ketika sumber daya tidak digunakan. Pendekatan ini mengurangi biaya dan meningkatkan efisiensi kluster.
Prasyarat
-
Anda telah membuat kluster GPU terkelola. Untuk informasi selengkapnya, lihat Tambahkan node GPU ke kluster.
-
Pasang komponen AHPA dan konfigurasikan sumber metrik. Untuk informasi selengkapnya, lihat Prediksi skalabilitas elastis (AHPA).
-
Aktifkan pemantauan Prometheus dan pastikan setidaknya tujuh hari data aplikasi historis (GPU) telah dikumpulkan di Prometheus. Untuk informasi selengkapnya, lihat Hubungkan dan konfigurasikan pemantauan Prometheus Alibaba Cloud.
Cara kerja
Dalam komputasi kinerja tinggi (HPC), terutama untuk pelatihan model pembelajaran mendalam dan inferensi, manajemen detail halus serta penyesuaian dinamis sumber daya GPU meningkatkan pemanfaatan dan mengurangi biaya. Container Service for Kubernetes mendukung skalabilitas elastis berdasarkan metrik GPU. Anda dapat menggunakan Prometheus untuk mengumpulkan metrik GPU utama seperti pemanfaatan real-time dan penggunaan memori GPU. Kemudian, gunakan Prometheus Adapter untuk mengubah metrik tersebut ke dalam format yang kompatibel dengan Kubernetes dan integrasikan dengan AHPA. AHPA menggunakan data ini, bersama dengan tren beban historis dan algoritma prediksi, untuk memperkirakan kebutuhan sumber daya GPU di masa depan dan secara otomatis menyesuaikan jumlah replika pod atau alokasi sumber daya GPU. Hal ini memastikan scale-out terjadi sebelum sumber daya menjadi terkendala dan scale-in dilakukan segera saat sumber daya menganggur, sehingga mengurangi biaya dan meningkatkan efisiensi kluster.
Langkah 1: Deploy Metrics Adapter
-
Dapatkan titik akhir HTTP API internal.
-
Masuk ke ARMS console.
-
Di panel navigasi kiri, pilih .
-
Pada halaman Instances, pilih wilayah tempat kluster Container Service for Kubernetes Anda berada.
-
Klik nama Prometheus instance yang dituju. Di panel navigasi kiri, klik Settings untuk mendapatkan titik akhir internal di bawah alamat HTTP API.
-
-
Deploy ack-alibaba-cloud-metrics-adapter.
Masuk ke ACK console. Di panel navigasi kiri, klik .
-
Pada halaman Marketplace, klik tab App Catalog, cari ack-alibaba-cloud-metrics-adapter, lalu klik.
-
Pada halaman ack-alibaba-cloud-metrics-adapter, klik Quick Deployment di pojok kanan atas.
-
Pada wizard Basic Information, pilih Cluster dan Namespace Anda, lalu klik Next.
-
Pada wizard Parameters, pilih Chart Version. Di bagian Parameter, atur titik akhir HTTP API internal yang diperoleh pada Langkah 1 sebagai nilai untuk
prometheus.url, lalu klik OK.prometheus: enabled: true url: http://
Langkah 2: Implementasikan prediksi elastis AHPA berdasarkan metrik GPU
Topik ini menyebarkan layanan inferensi model pada GPU dan terus-menerus mengirim permintaan ke layanan tersebut. AHPA melakukan prediksi elastis berdasarkan pemanfaatan GPU.
-
Deploy layanan inferensi.
-
Jalankan perintah berikut untuk deploy layanan inferensi.
-
Jalankan perintah berikut untuk memeriksa status pod.
kubectl get pods -o wideExpected output:
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES bert-intent-detection-7b486f6bf-f**** 1/1 Running 0 3m24s 10.15.1.17 cn-beijing.192.168.94.107 <none> <none> -
Jalankan perintah berikut untuk memanggil layanan inferensi dan memverifikasi penerapan.
Gunakan perintah
kubectl get svc bert-intent-detection-svcuntuk mendapatkan alamat IP node GPU dan ganti47.95.XX.XXpada perintah berikut.curl -v "http://47.95.XX.XX/predict?query=Music"Expected output:
* Trying 47.95.XX.XX... * TCP_NODELAY set * Connected to 47.95.XX.XX (47.95.XX.XX) port 80 (#0) > GET /predict?query=Music HTTP/1.1 > Host: 47.95.XX.XX > User-Agent: curl/7.64.1 > Accept: */* > * HTTP 1.0, assume close after body < HTTP/1.0 200 OK < Content-Type: text/html; charset=utf-8 < Content-Length: 9 < Server: Werkzeug/1.0.1 Python/3.6.9 < Date: Wed, 16 Feb 2022 03:52:11 GMT < * Closing connection 0 PlayMusic #Intent recognition result.Jika permintaan HTTP mengembalikan kode status
200dan hasil pengenalan maksud, layanan inferensi berhasil diterapkan.
-
-
Konfigurasikan AHPA.
Contoh ini menggunakan pemanfaatan GPU. Scale-out dipicu ketika pemanfaatan GPU sebuah pod melebihi 20%.
-
Konfigurasikan sumber metrik AHPA.
-
Buat file bernama application-intelligence.yaml dengan konten berikut.
prometheusUrlmengatur titik akhir untuk Alibaba Cloud Prometheus. Gunakan titik akhir internal yang diperoleh pada Langkah 1.apiVersion: v1 kind: ConfigMap metadata: name: application-intelligence namespace: kube-system data: prometheusUrl: "http://cn-shanghai-intranet.arms.aliyuncs.com:9090/api/v1/prometheus/da9d7dece901db4c9fc7f5b*******/1581204543170*****/c54417d182c6d430fb062ec364e****/cn-shanghai" -
Jalankan perintah berikut untuk menerapkan application-intelligence.
kubectl apply -f application-intelligence.yaml
-
-
Deploy AHPA.
-
Buat file bernama fib-gpu.yaml dengan konten berikut.
Mode diatur ke
observer. Untuk informasi selengkapnya tentang parameter, lihat deskripsi metrik. -
Jalankan perintah berikut untuk menerapkan AHPA.
kubectl apply -f fib-gpu.yaml -
Jalankan perintah berikut untuk memeriksa status AHPA.
kubectl get ahpaExpected output:
NAME STRATEGY REFERENCE METRIC TARGET(%) CURRENT(%) DESIREDPODS REPLICAS MINPODS MAXPODS AGE fib-gpu observer bert-intent-detection gpu 20 0 0 1 10 50 6d19hOutput yang diharapkan menunjukkan bahwa
CURRENT(%)adalah0danTARGET(%)adalah20. Artinya, pemanfaatan GPU saat ini adalah 0%. Scale-out elastis dipicu ketika pemanfaatan GPU melebihi 20%.
-
-
-
Uji skalabilitas elastis untuk layanan inferensi.
-
Jalankan perintah berikut untuk mengakses layanan inferensi.
-
Saat mengakses layanan, jalankan perintah berikut untuk memeriksa status AHPA.
kubectl get ahpaExpected output:
NAME STRATEGY REFERENCE METRIC TARGET(%) CURRENT(%) DESIREDPODS REPLICAS MINPODS MAXPODS AGE fib-gpu observer bert-intent-detection gpu 20 189 10 4 10 50 6d19hOutput yang diharapkan menunjukkan bahwa pemanfaatan GPU saat ini
CURRENT(%)melebihi nilaiTARGET(%). Skalabilitas elastis dipicu, dan jumlah pod yang diinginkanDESIREDPODSadalah10. -
Jalankan perintah berikut untuk melihat tren prediksi.
kubectl get --raw '/apis/metrics.alibabacloud.com/v1beta1/namespaces/default/predictionsobserver/fib-gpu'|jq -r '.content' |base64 -d > observer.htmlGambar berikut menunjukkan contoh tren prediksi berdasarkan metrik GPU selama tujuh hari:
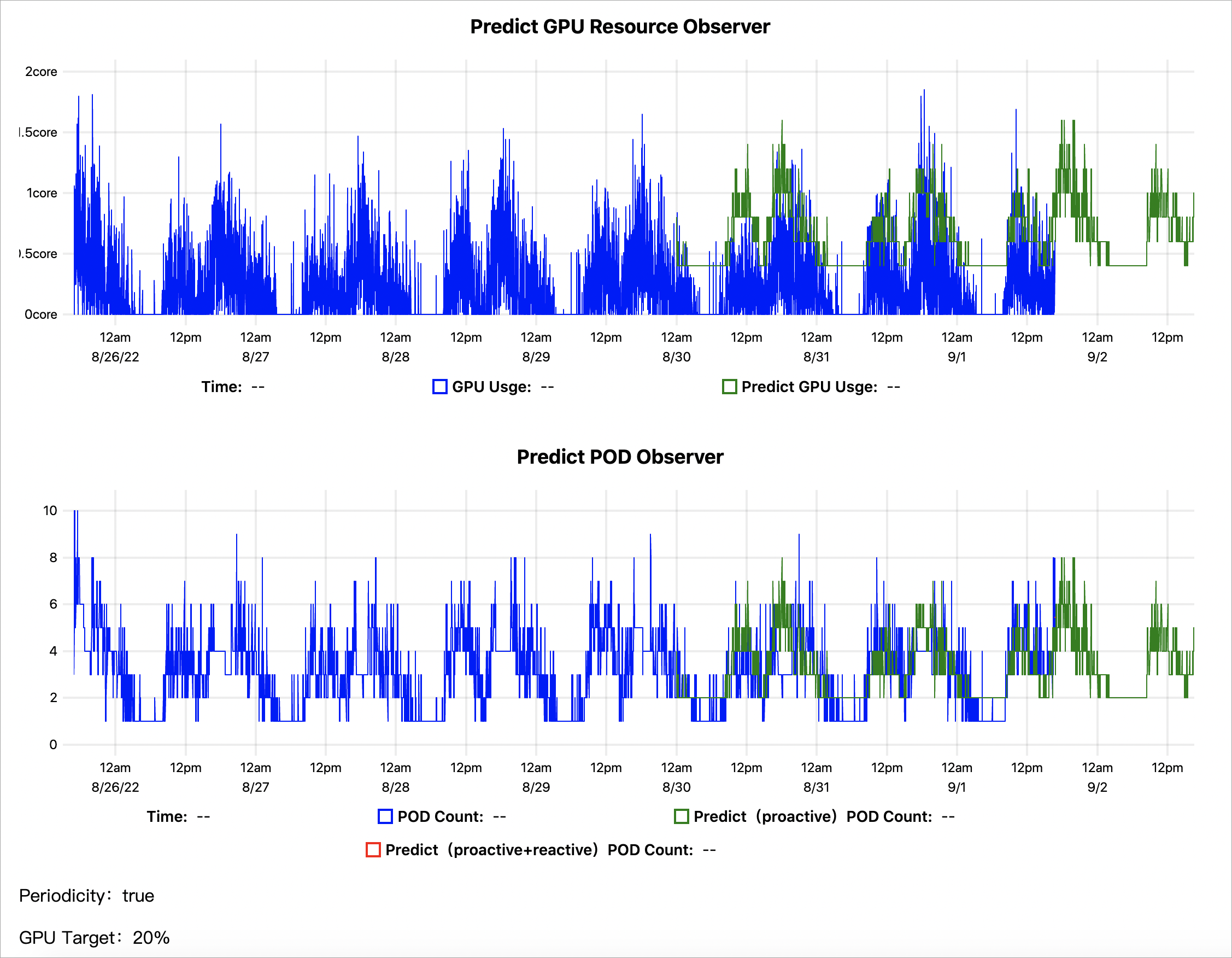
-
Predict GPU Resource Observer: Garis biru menunjukkan penggunaan GPU aktual. Garis hijau menunjukkan penggunaan GPU yang diprediksi oleh AHPA. Kurva hijau umumnya berada di atas kurva biru, menandakan kapasitas GPU yang diprediksi mencukupi.
-
Predict POD Observer: Garis biru menunjukkan jumlah pod yang diskalakan secara aktual. Garis hijau menunjukkan jumlah pod yang diprediksi oleh AHPA. Kurva hijau umumnya berada di bawah kurva biru, menandakan AHPA memprediksi lebih sedikit pod. Anda dapat mengatur mode skalabilitas elastis ke
autountuk menggunakan jumlah pod yang diprediksi, sehingga menghemat sumber daya pod dan menghindari pemborosan.
Hasil prediksi sesuai ekspektasi. Setelah observasi, jika hasil tetap memuaskan, atur mode skalabilitas elastis ke
autoagar AHPA menangani penskalaan. -
-
Referensi
-
Knative Serverless mendukung kemampuan elastis AHPA (Advanced Horizontal Pod Autoscaler). Ketika kebutuhan sumber daya aplikasi bersifat periodik, prediksi elastis memanaskan sumber daya terlebih dahulu dan mengatasi masalah cold start di Knative. Untuk informasi selengkapnya, lihat Gunakan prediksi elastis AHPA di Knative.
-
Dalam banyak skenario, aplikasi harus diskalakan berdasarkan metrik kustom seperti QPS permintaan HTTP atau panjang antrian pesan. AHPA menyediakan mekanisme External Metrics. Dikombinasikan dengan komponen alibaba-cloud-metrics-adapter, fitur ini menawarkan opsi penskalaan yang lebih kaya. Untuk informasi selengkapnya, lihat Konfigurasikan metrik kustom dengan AHPA untuk menskalakan aplikasi.