Anda dapat menggunakan KServe pada ACK Knative untuk menerapkan model AI sebagai layanan inferensi tanpa server. Fitur utama yang disediakan meliputi penskalaan otomatis, manajemen multi-versi, dan rilis canary.
Langkah 1: Instal dan konfigurasikan KServe
Untuk memastikan integrasi yang lancar antara KServe dan Ingress ALB atau gerbang Kourier dari Knative, instal komponen KServe, lalu ubah pengaturan defaultnya untuk menonaktifkan pembuatan Istio VirtualService bawaannya.
Instal komponen KServe.
Masuk ke Konsol ACK. Di panel navigasi kiri, klik Clusters.
Di halaman Clusters, temukan kluster yang diinginkan dan klik namanya. Di panel navigasi kiri, pilih .
Di tab Components, temukan dan terapkan komponen KServe di bagian Add-on.
Nonaktifkan pembuatan Istio VirtualService.
Edit ConfigMap
inferenceservice-configuntuk mengaturdisableIstioVirtualHostmenjaditrue.kubectl get configmap inferenceservice-config -n kserve -o yaml \ | sed 's/"disableIstioVirtualHost": false/"disableIstioVirtualHost": true/g' \ | kubectl apply -f -Output yang diharapkan:
configmap/inferenceservice-config configuredVerifikasi perubahan konfigurasi.
kubectl get configmap inferenceservice-config -n kserve -o yaml \ | grep '"disableIstioVirtualHost":' \ | tail -n1 \ | awk -F':' '{gsub(/[ ,]/,"",$2); print $2}'Output harus berupa
true.Mulai ulang kontroler KServe untuk menerapkan perubahan.
kubectl rollout restart deployment kserve-controller-manager -n kserve
Langkah 2: Terapkan InferenceService
Contoh ini menerapkan model klasifikasi scikit-learn yang dilatih pada dataset Iris. Layanan ini menerima array empat pengukuran untuk sebuah bunga dan memprediksi spesies mana dari tiga spesies tersebut yang dimiliki.
Input (array dari empat fitur numerik):
| Output (indeks kelas yang diprediksi):
|
Buat file bernama
inferenceservice.yamluntuk menerapkan InferenceService.apiVersion: "serving.kserve.io/v1beta1" kind: "InferenceService" metadata: name: "sklearn-iris" spec: predictor: model: # Format model, dalam kasus ini scikit-learn modelFormat: name: sklearn image: "kube-ai-registry.cn-shanghai.cr.aliyuncs.com/ai-sample/kserve-sklearn-server:v0.12.0" command: - sh - -c - "python -m sklearnserver --model_name=sklearn-iris --model_dir=/models --http_port=8080"Terapkan InferenceService.
kubectl apply -f inferenceservice.yamlPeriksa status layanan.
kubectl get inferenceservices sklearn-irisDalam output, ketika kolom
READYmenunjukkanTrue, layanan sudah aktif dan berjalan.NAME URL READY PREV LATEST PREVROLLEDOUTREVISION LATESTREADYREVISION AGE sklearn-iris http://sklearn-iris-predictor-default.default.example.com True 100 sklearn-iris-predictor-default-00001 51s
Langkah 3: Akses layanan
Kirim permintaan inferensi ke layanan melalui gerbang masuk kluster.
Di tab Services pada halaman Knative, dapatkan alamat gerbang dan nama domain default untuk mengakses layanan.
Gambar berikut menunjukkan contoh menggunakan Ingress ALB. Antarmuka untuk gerbang Kourier serupa.
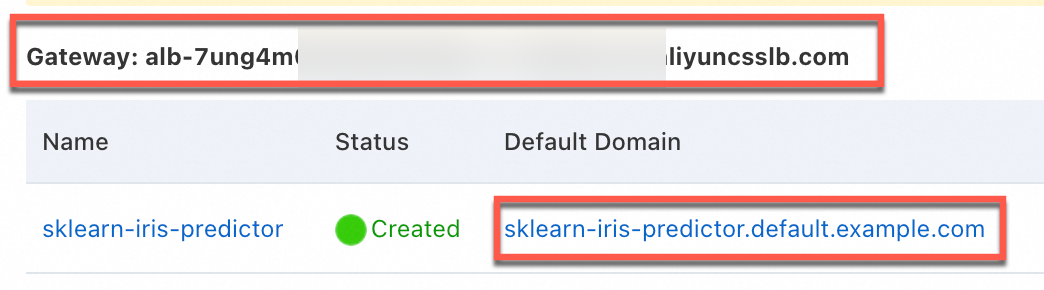
Siapkan data permintaan.
Di terminal lokal Anda, buat file bernama
./iris-input.jsonyang berisi muatan permintaan. Contoh ini mencakup dua sampel yang akan diprediksi.cat <<EOF > "./iris-input.json" { "instances": [ [6.8, 2.8, 4.8, 1.4], [6.0, 3.4, 4.5, 1.6] ] } EOFKirim permintaan inferensi dari terminal lokal Anda untuk mengakses layanan. Ganti
${INGRESS_DOMAIN}dengan alamat gerbang dari Langkah 1.curl -H "Content-Type: application/json" -H "Host: sklearn-iris-predictor.default.example.com" "http://${INGRESS_DOMAIN}/v1/models/sklearn-iris:predict" -d @./iris-input.jsonOutput menunjukkan bahwa model memprediksi kedua sampel input termasuk dalam kelas
1(Iris Versicolour).{"predictions":[1,1]}
Tagihan
Komponen KServe dan Knative itu sendiri tidak membebani biaya tambahan. Namun, Anda akan dikenakan biaya untuk sumber daya dasar yang Anda gunakan, termasuk sumber daya komputasi seperti instans Elastic Compute Service (ECS) dan Elastic Container Instance, serta sumber daya jaringan seperti instans Application Load Balancer (ALB) dan Classic Load Balancer (CLB). Untuk detailnya, lihat Biaya Sumber Daya Cloud.
FAQ
Mengapa InferenceService saya macet dalam keadaan Tidak Siap?
Untuk men-debug InferenceService yang gagal menjadi siap, pertama-tama periksa event-nya, lalu periksa status pod terkait, dan tinjau log kontainer.
Ikuti langkah-langkah berikut:
Jalankan
kubectl describe inferenceservice <your-service-name>dan periksa event untuk pesan kesalahan apa pun. Ganti<your-service-name>dengan nama layanan aktual Anda.Jalankan
kubectl get podsuntuk melihat apakah ada pod terkait layanan yang berada dalam keadaanErroratauCrashLoopBackOff. Pod untukInferenceServicebiasanya memiliki awalan nama layanan.Jika pod dalam keadaan error, periksa lognya dengan
kubectl logs <pod-name> -c kserve-containeruntuk mendiagnosis kegagalan. Ini dapat mengungkapkan masalah seperti model gagal mengunduh karena masalah jaringan atau format file model yang salah.
Bagaimana cara menerapkan model pelatihan kustom saya sendiri?
Unggah file model Anda ke Bucket Object Storage Service (OSS) yang dapat diakses.
Konfigurasikan
manifes InferenceServiceAnda untuk menunjuk ke model:Atur bidang
spec.predictor.model.storageUrike URI file model Anda di bucket OSS.Atur bidang
modelFormatberdasarkan framework model Anda, sepertitensorflow,pytorch, atauonnx.
Bagaimana cara mengonfigurasi sumber daya GPU untuk model saya?
Jika model Anda memerlukan GPU untuk inferensi, Anda dapat meminta sumber daya GPU dengan menambahkan bidang resources ke bagian predictor dari manifes YAML InferenceService Anda.
Untuk informasi lebih lanjut tentang penggunaan GPU dengan Knative, lihat Gunakan Sumber Daya GPU.
spec:
predictor:
resources:
requests:
nvidia.com/gpu: "1"
limits:
nvidia.com/gpu: "1"Referensi
Praktik Terbaik untuk Menerapkan Layanan Inferensi AI di Knative.
ACK Knative menyediakan templat aplikasi untuk Stable Diffusion. Untuk detailnya, lihat Terapkan Layanan Stable Diffusion dalam Lingkungan Produksi Berbasis Knative.