Kubernetes menghasilkan event saat terjadi perubahan status kluster—misalnya, ketika sebuah Pod di-evict, gagal menarik image, atau sebuah node melaporkan pengecualian perangkat keras. Secara default, Kubernetes hanya menyimpan event tersebut selama satu jam. Untuk mendeteksi anomali tepat waktu dan mencegah kehilangan data event, ACK menyediakan solusi pemantauan event end-to-end yang mengumpulkan, menyimpan, memberikan peringatan, serta mengarsipkan event kluster.
ACK secara default mengalirkan (sink) event kluster ke Simple Log Service dan menyimpannya secara gratis selama 90 hari. Untuk informasi lebih lanjut, lihat Buat dan gunakan pusat event.
Cara kerja
ACK menggunakan dua alat open-source untuk pemantauan event:
node-problem-detector (NPD) — Mendiagnosis node Kubernetes. NPD mendeteksi pengecualian pada node—seperti hang Docker engine, hang kernel Linux, pengecualian lalu lintas arah keluar, dan pengecualian deskriptor file—menghasilkan event node, serta berintegrasi dengan kube-eventer untuk menutup siklus manajemen peringatan. Untuk informasi selengkapnya, lihat NPD.
kube-eventer — Sebuah event emitter open-source yang dikelola oleh ACK. kube-eventer meneruskan event Kubernetes ke sink seperti DingTalk, Simple Log Service, dan EventBridge. Alat ini menyaring event berdasarkan tingkat keparahan, memungkinkan pengumpulan real-time, pemberian peringatan untuk event tertentu, serta pengarsipan asinkron. Untuk informasi lebih lanjut, lihat kube-eventer.

Kubernetes menghasilkan dua jenis event:
| Type | Kapan dihasilkan | Contoh |
|---|---|---|
| Normal | State machine berpindah ke status yang diharapkan | Pod dijadwalkan, kontainer dimulai |
| Warning | State machine berpindah ke status yang tidak diharapkan | Pod di-evict, gagal menarik image, CrashLoopBackOff |
Pilih skenario
Pilih skenario yang sesuai dengan kebutuhan pemantauan Anda:
| Skenario | Kapan digunakan |
|---|---|
| Skenario 1: Gunakan NPD dengan pusat event Simple Log Service | Mulai dengan cepat. Alirkan semua event kluster ke Simple Log Service untuk visualisasi, kueri, dan peringatan dari satu tempat. |
| Skenario 2: Jalankan diagnosis node NPD | Deteksi pengecualian tingkat node (tekanan disk, masalah jaringan, kegagalan daemon Docker) dan picu manajemen peringatan closed-loop. |
| Skenario 3: Kirim peringatan ke DingTalk | Teruskan event Warning ke grup DingTalk untuk notifikasi ChatOps real-time. |
| Skenario 4: Arsipkan event ke Simple Log Service | Simpan event Kubernetes secara persisten dalam Logstore khusus untuk penyimpanan jangka panjang, pengindeksan, dan analisis offline. |
| Skenario 5: Teruskan event ke EventBridge | Bangun arsitektur berbasis event—picu remediasi otomatis atau alur kerja downstream dari event kluster. |
Skenario 1: Gunakan NPD dengan pusat event Simple Log Service
NPD bekerja dengan plugin pihak ketiga untuk mendeteksi pengecualian node dan menghasilkan event kluster. Kubernetes juga menghasilkan event saat terjadi perubahan status kluster—misalnya, ketika sebuah Pod di-evict atau gagal menarik image. Pusat event Kubernetes dari Simple Log Service mengumpulkan, menyimpan, dan memvisualisasikan event tersebut, dilengkapi fitur kueri dan peringatan bawaan.
Langkah 1: Instal komponen ack-node-problem-detector
Jika Anda memilih Install node-problem-detector and Create Event Center saat membuat kluster, lewati ke Langkah 2: Lihat pusat event. Untuk informasi lebih lanjut tentang instalasi saat pembuatan kluster, lihat Buat kluster ACK yang dikelola.
Jika Anda tidak memilih opsi ini, instal komponen secara manual:
Masuk ke Konsol ACK. Di panel navigasi kiri, klik Clusters.
Di halaman Clusters, temukan kluster dan klik namanya. Di panel navigasi kiri, klik Add-ons.
Di tab Logs and Monitoring, temukan dan instal ack-node-problem-detector.
Langkah 2: Lihat pusat event
Masuk ke Konsol ACK. Di panel navigasi sebelah kiri, klik Clusters.
Di halaman Clusters, temukan kluster dan klik namanya. Di panel navigasi kiri, pilih Operations > Event Center.
Di halaman Event Center, klik tab Event Overview (Event Center). Tab ini menampilkan semua event Kubernetes, informasi detailnya, serta siklus hidup Pod. Untuk informasi lebih lanjut, lihat Kumpulkan event Kubernetes.
Skenario 2: Jalankan diagnosis node NPD
NPD yang terintegrasi dengan kube-eventer menyediakan manajemen peringatan closed-loop untuk event node. Saat NPD mendeteksi pengecualian, kube-eventer meneruskan event tersebut ke sink yang dikonfigurasi dan memicu peringatan.
Prasyarat
Sebelum memulai, pastikan Anda telah:
Menginstal komponen ack-node-problem-detector. Jika belum diinstal, lihat Langkah 1: Instal komponen ack-node-problem-detector. Jika sudah diinstal, instal ulang terlebih dahulu—lihat Instal ulang komponen ack-node-problem-detector.
Verifikasi DaemonSet sedang berjalan
Di halaman Clusters, temukan kluster dan klik namanya. Di panel navigasi kiri, pilih Workloads > DaemonSets.
Di tab DaemonSets, pilih namespace kube-system dan verifikasi bahwa ack-node-problem-detector-daemonset sedang berjalan. Saat NPD dan kube-eventer keduanya berjalan, sistem akan mengalirkan event dan memicu peringatan berdasarkan konfigurasi kube-eventer.
Plugin diagnosis node
NPD mendukung plugin diagnosis node berikut:
| Plug-in | Apa yang diperiksa | Ambang batas default | Diaktifkan secara default |
|---|---|---|---|
ntp_check | Apakah jam sistem tersinkronisasi melalui Network Time Protocol (NTP) | — | Ya |
network_problem_check | Apakah penggunaan tabel connection tracking (conntrack) melebihi ambang batas | 90% | Ya |
inodes_usage_check | Apakah penggunaan inode pada sistem disk melebihi ambang batas (dapat disesuaikan) | 80% | Ya |
pid_pressure_check | Apakah rasio proses pid melebihi ambang batas maksimum kernel | 85% | Ya |
docker_offline_check | Apakah daemon Docker sedang berjalan | — | Ya |
fd_check | Apakah penggunaan file descriptor melebihi ambang batas (dapat disesuaikan). Catatan Plugin ini mengonsumsi sumber daya signifikan. Aktifkan hanya jika diperlukan. | 80% | Tidak |
ram_role_check | Apakah node memiliki role RAM dan ID/rahasia AccessKey yang diperlukan | — | Tidak |
nvidia_gpu_check | Apakah GPU NVIDIA dapat menghasilkan pesan Xid | — | Tidak |
csi_hang_check | Apakah plug-in Container Storage Interface (CSI) sedang berjalan | — | Tidak |
ps_hang_check | Apakah terdapat proses dalam keadaan sleep yang tidak dapat diinterupsi (D) | — | Tidak |
public_network_check | Apakah node dapat mengakses Internet | — | Tidak |
irqbalance_check | Apakah daemon irqbalance sedang berjalan | — | Tidak |
Skenario 3: Kirim peringatan ke DingTalk
Menggunakan chatbot DingTalk untuk menerima peringatan event Kubernetes merupakan implementasi ChatOps yang umum. Saat terjadi event tingkat Warning, kube-eventer mendorong pesan ke grup DingTalk melalui webhook.
Prasyarat
Sebelum memulai, pastikan Anda telah:
Menginstal komponen ack-node-problem-detector. Jika belum diinstal, lihat Langkah 1: Instal komponen ack-node-problem-detector. Jika sudah diinstal, instal ulang terlebih dahulu—lihat Instal ulang komponen ack-node-problem-detector.
Langkah 1: Tambahkan chatbot DingTalk
Klik
 di pojok kanan atas kotak obrolan untuk membuka Group Settings.
di pojok kanan atas kotak obrolan untuk membuka Group Settings.Klik Bot, lalu klik Add Robot. Pilih Custom sebagai tipe chatbot.
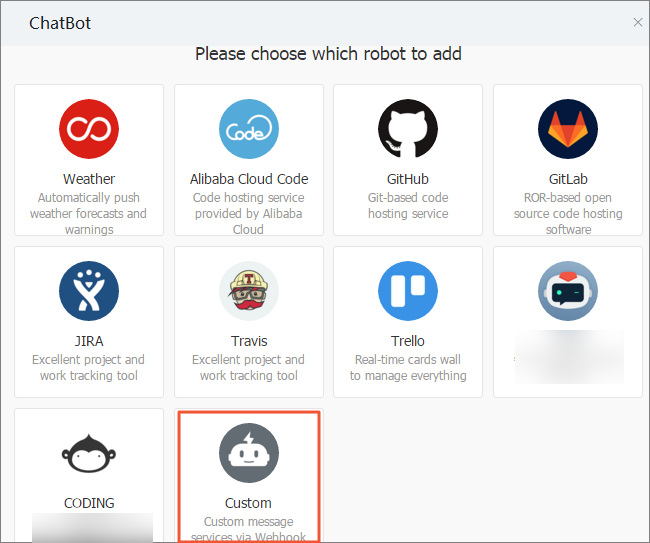
Di halaman Robot details, klik Add untuk membuka halaman Add Robot. Atur parameter berikut, terima Ketentuan Layanan DingTalk Custom Robot Service, lalu klik Finished:
Parameter Deskripsi Edit profile picture Avatar chatbot. Opsional. Chatbot name Nama tampilan chatbot. Add to Group Grup DingTalk tempat menambahkan chatbot. Security settings Terdapat tiga opsi: Custom Keywords, tanda tangan tambahan, dan alamat IP (atau Blok CIDR). Hanya Custom Keywords yang didukung untuk menyaring peringatan event kluster. Pilih Custom Keywords dan masukkan Warning. Tambahkan kata kunci lain untuk mempersempit filter — hingga 10 kata kunci.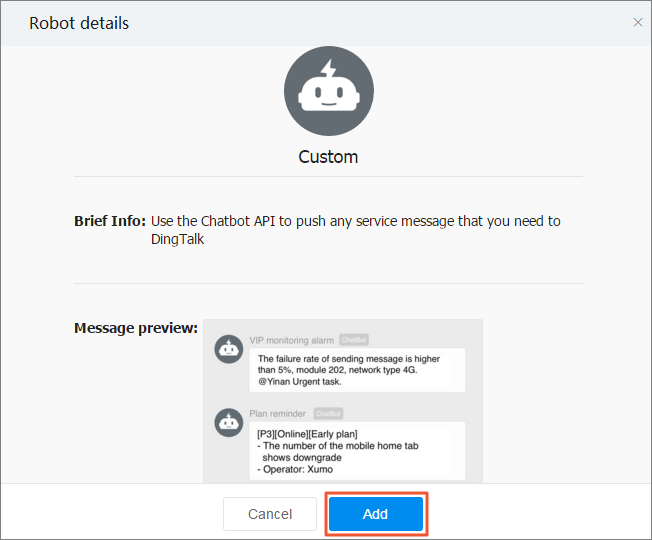
Klik Copy untuk menyalin URL webhook.
Di halaman ChatBot, klik
 di samping chatbot untuk mengubah avatar dan nama, mengaktifkan atau menonaktifkan dorongan pesan, mereset URL webhook, atau menghapus chatbot.
di samping chatbot untuk mengubah avatar dan nama, mengaktifkan atau menonaktifkan dorongan pesan, mereset URL webhook, atau menghapus chatbot.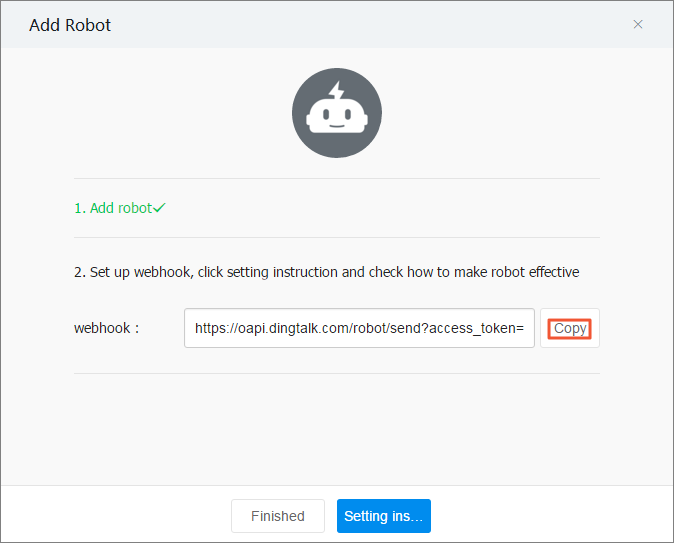
Langkah 2: Konfigurasikan kube-eventer untuk mengirim event ke DingTalk
Di halaman Clusters, temukan kluster dan klik namanya. Di panel navigasi kiri, pilih Applications > Helm.
Di halaman Helm, temukan ack-node-problem-detector dan klik Update di kolom Actions.
Atur parameter berikut, lalu klik OK:
Di bagian
npd, aturenabledmenjadifalse.Atur
eventer.sinks.dingtalk.enabledmenjaditrue.Masukkan token dari URL webhook yang telah Anda salin.
Hasil
kube-eventer berlaku 30 detik setelah deployment. Saat terjadi event tingkat Warning, peringatan akan dikirim ke grup DingTalk.
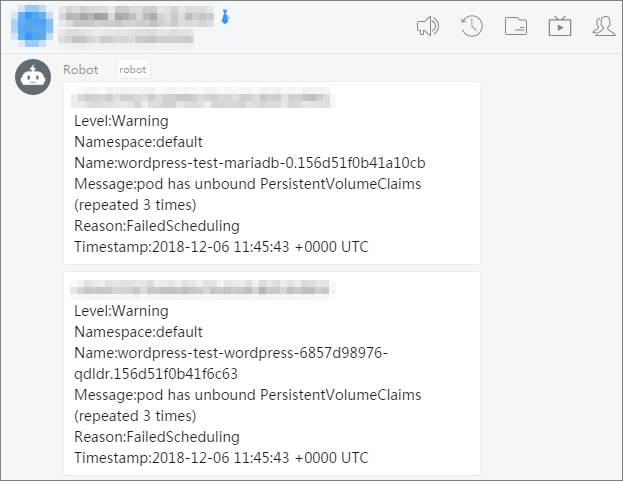
Skenario 4: Arsipkan event ke Simple Log Service
Alirkan event Kubernetes ke Simple Log Service untuk penyimpanan persisten, pengindeksan, dan audit. Untuk retensi jangka panjang atau pengarsipan offline, konfigurasikan pengaturan Logstore dan pengiriman data opsional ke MaxCompute atau Object Storage Service (OSS). Untuk informasi lebih lanjut, lihat Buat dan gunakan pusat event.
Prasyarat
Sebelum memulai, pastikan Anda telah:
Menginstal komponen ack-node-problem-detector. Tentukan proyek dan Logstore saat instalasi. Jika sudah diinstal, instal ulang terlebih dahulu—lihat Instal ulang komponen ack-node-problem-detector.
Langkah 1: Buat proyek Simple Log Service dan Logstore
Masuk ke Konsol Simple Log Service.
Di bagian Projects, klik Create Project. Di panel Create Project, atur parameter dan klik Create.
Buat proyek Simple Log Service di wilayah yang sama dengan kluster Anda. Transmisi antar-wilayah yang sama menggunakan jaringan internal, sehingga mengurangi latensi dan menghilangkan biaya bandwidth cross-region. Contoh ini membuat proyek bernama
k8s-log4jdi wilayah China (Hangzhou).Di bagian Projects, klik k8s-log4j untuk membuka halaman detail proyek.
Di panel Logstores, klik + untuk membuka panel Create Logstore.
Atur parameter dan klik OK. Contoh ini membuat Logstore bernama
k8s-logstore.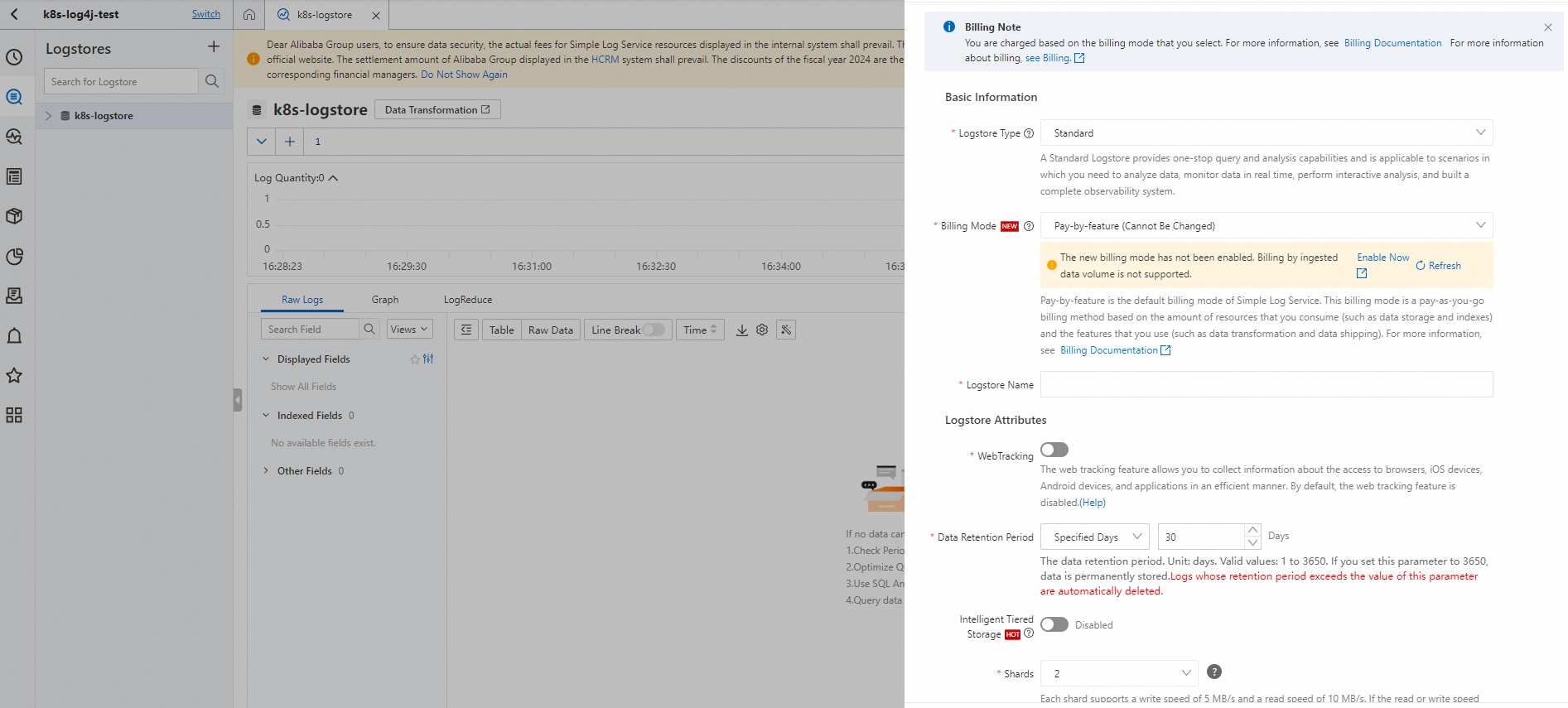
Setelah Logstore dibuat, klik Data Import Wizard. Kotak dialog Import Data muncul.
Pilih Log4j 1/2 dan selesaikan langkah konfigurasi. Contoh ini menggunakan pengaturan default.
Langkah 2: Konfigurasikan kube-eventer untuk mengalirkan event ke Simple Log Service
Di halaman Clusters, temukan kluster dan klik namanya. Di panel navigasi kiri, pilih Applications > Helm.
Di halaman Helm, temukan ack-node-problem-detector dan klik Update di kolom Actions.
Atur parameter berikut, lalu klik OK:
Di bagian
npd, aturenabledmenjadifalse.Atur
eventer.sinks.sls.enabledmenjaditrue.
Langkah 3: Verifikasi pengumpulan event dan atur pengindeksan
Picu event kluster—misalnya, hapus sebuah Pod atau buat aplikasi.
Masuk ke Konsol Simple Log Service untuk melihat event yang dikumpulkan. Untuk informasi lebih lanjut, lihat Konsumsi data log menggunakan SDK Simple Log Service.
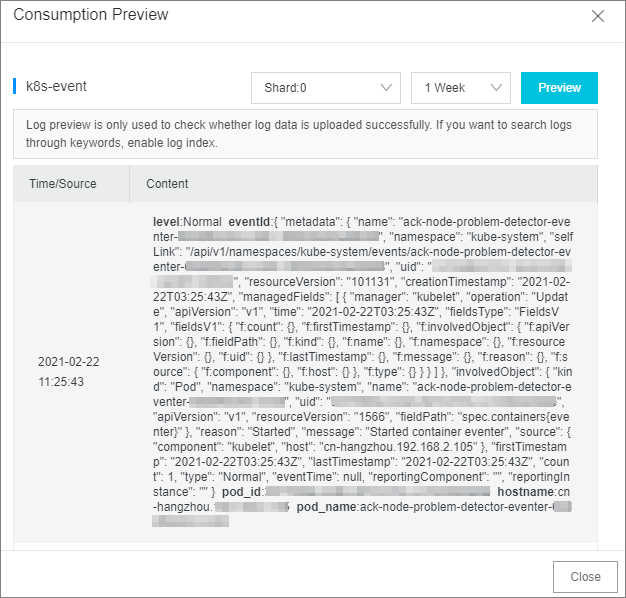
Atur pengindeksan untuk kueri dan analisis. Untuk informasi lebih lanjut, lihat Buat indeks.
Di bagian Projects, klik nama proyek.
Klik
 di samping nama Logstore dan pilih Search & Analysis.
di samping nama Logstore dan pilih Search & Analysis.Di pojok kanan atas, klik Enable Index.
Di panel Search & Analysis, atur parameter dan klik OK. Halaman kueri dan analisis log muncul.
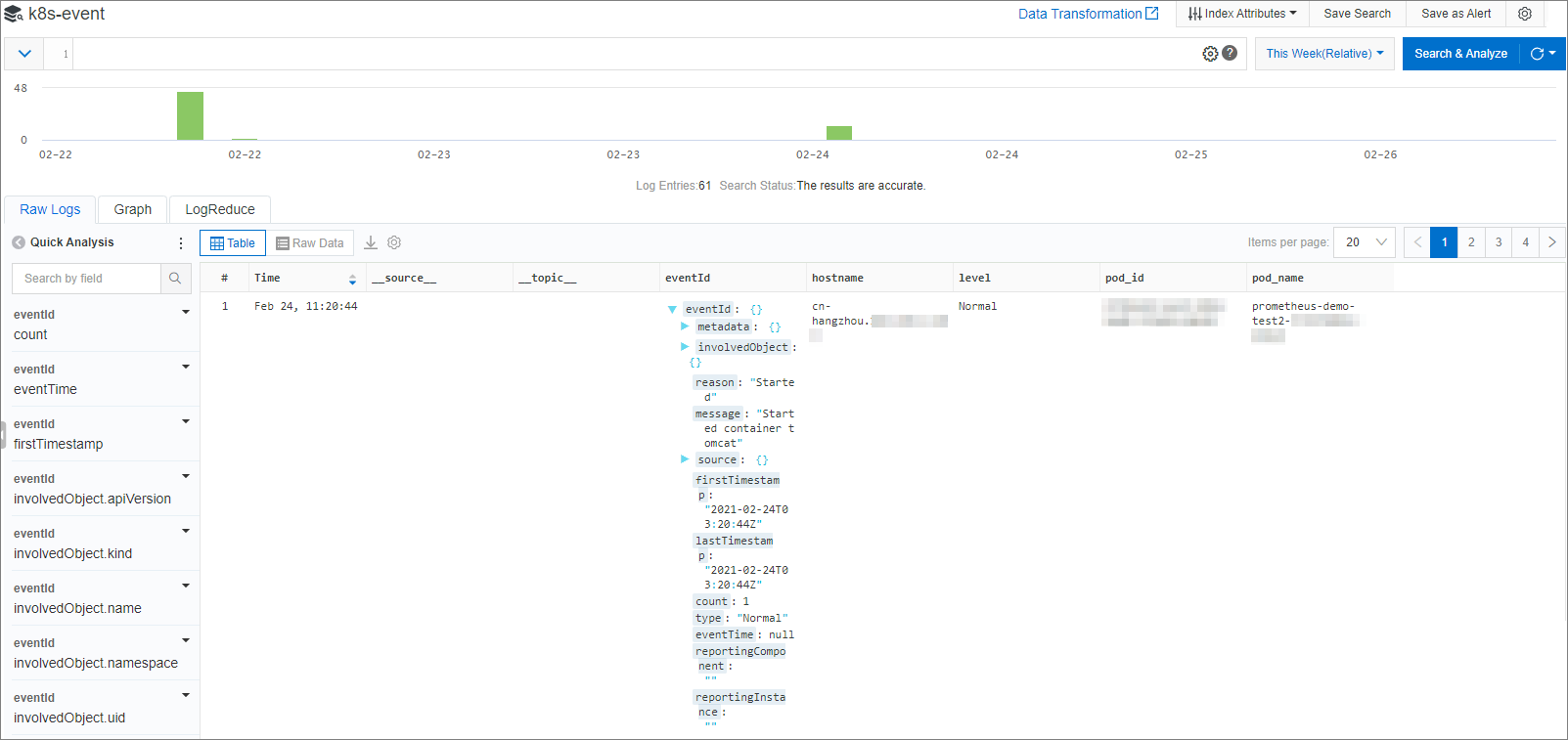 > Note: Konfigurasi indeks berlaku dalam 1 menit dan hanya berlaku untuk data yang masuk setelah indeks diaktifkan atau dimodifikasi.
> Note: Konfigurasi indeks berlaku dalam 1 menit dan hanya berlaku untuk data yang masuk setelah indeks diaktifkan atau dimodifikasi.(Opsional) Untuk mengarsipkan event guna analisis offline, kirim data dari Logstore ke MaxCompute atau Object Storage Service (OSS). Untuk informasi lebih lanjut, lihat Buat pekerjaan pengiriman data versi baru untuk mengirim data ke MaxCompute dan Buat pekerjaan pengiriman data OSS (versi baru).
Skenario 5: Teruskan event ke EventBridge
EventBridge adalah layanan event arsitektur tanpa server yang memungkinkan layanan Alibaba Cloud, aplikasi kustom, dan aplikasi software as a service (SaaS) terhubung secara terstandarisasi dan terpusat. Mengarahkan event ACK ke EventBridge memungkinkan Anda membangun arsitektur berbasis event yang loosely coupled—misalnya, memicu alur kerja remediasi otomatis saat event tertentu terjadi. Untuk informasi lebih lanjut, lihat Apa itu EventBridge?.
Prasyarat
Sebelum memulai, pastikan Anda telah:
Mengaktifkan EventBridge. Untuk informasi lebih lanjut, lihat Aktifkan EventBridge dan berikan izin kepada Pengguna RAM.
Menginstal komponen ack-node-problem-detector. Jika belum diinstal, lihat Langkah 1: Instal komponen ack-node-problem-detector. Jika sudah diinstal, instal ulang terlebih dahulu—lihat Instal ulang komponen ack-node-problem-detector.
Aktifkan EventBridge sebagai sink event
Di halaman Clusters, temukan kluster dan klik namanya. Di panel navigasi kiri, pilih Applications > Helm.
Di halaman Helm, temukan ack-node-problem-detector dan klik Update di kolom Actions.
Atur
eventer.sinks.eventbridge.enablemenjaditrue, lalu klik OK.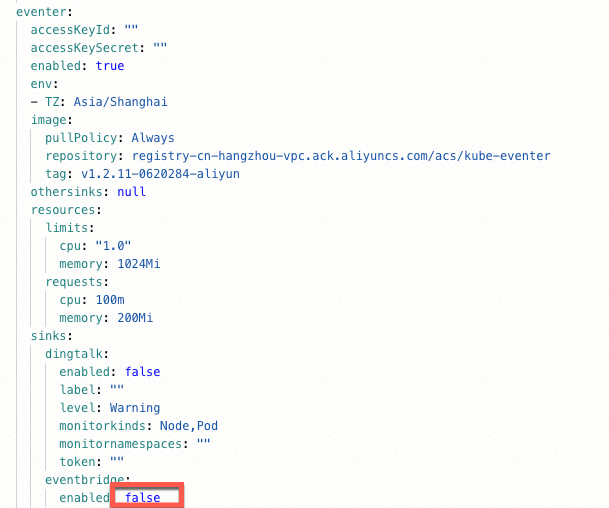
Lihat event Kubernetes di EventBridge
Masuk ke Konsol EventBridge.
Di panel navigasi kiri, klik Event Buses.
Di halaman Event Buses, klik event bus target.
Di panel navigasi kiri, klik Event Tracking.
Pilih metode kueri, atur kondisi kueri, lalu klik Query.
Temukan event dan klik Details di kolom Actions. Untuk informasi lebih lanjut, lihat Kueri event berdasarkan ID event.
Instal ulang komponen ack-node-problem-detector
Instal ulang komponen ini saat Anda mengubah target sink (misalnya, beralih dari Simple Log Service ke DingTalk) atau saat memperbarui konfigurasi komponen.
Masuk ke ACK console. Di panel navigasi sebelah kiri, klik Clusters.
Di halaman Clusters, temukan kluster dan klik namanya. Di panel navigasi kiri, pilih Workloads > Jobs.
Di halaman Jobs, klik More di samping
kube-eventer-init-v1.7-xxxxdan klik Delete.Di halaman Clusters, temukan kluster dan klik namanya. Di panel navigasi kiri, pilih Applications > Helm.
Di halaman Helm, hapus komponen ack-node-problem-detector.
Di halaman Clusters, temukan kluster dan klik namanya. Di panel navigasi kiri, pilih Operations > Add-ons.
Di tab Logging and Monitoring, temukan dan instal ulang ack-node-problem-detector.