Konfigurasikan Knative Pod Autoscaler (KPA) untuk menskalakan pod Knative Serving berdasarkan concurrency atau RPS di ACK.
Prasyarat
Sebelum memulai, pastikan Anda telah:
-
Membuat ACK managed cluster atau ACK Serverless cluster yang menjalankan Kubernetes 1.20 atau versi lebih baru.
-
Knative telah dideploy di kluster.
Cara kerja
Knative Serving menyuntikkan kontainer sidecar queue-proxy ke dalam setiap pod. Sidecar tersebut melaporkan metrik concurrency ke KPA, yang kemudian menyesuaikan jumlah pod berdasarkan metrik tersebut dan algoritma yang dikonfigurasi.

Algoritma penskalaan
KPA menghitung jumlah target pod dengan rumus berikut:
Jumlah pod = Jumlah permintaan konkuren / (Concurrency maksimum per pod × Utilisasi target)Contoh: Dengan containerConcurrency diatur ke 10 dan utilisasi target sebesar 70%, 100 permintaan konkuren menghasilkan: 100 / (10 × 0,7) = 15 pod (dibulatkan ke atas).
Mode stabil dan mode panic
KPA menggunakan dua mode untuk merespons pola lalu lintas:
Mode stabil — mode default. KPA menghitung rata-rata concurrency di seluruh pod selama jendela stabil (default: 60 detik) dan menyesuaikan jumlah pod agar sesuai.
Mode panic — dipicu saat terjadi lonjakan traffic. KPA menggunakan jendela panic yang lebih pendek (default: 6 detik; stable window × panic-window-percentage) untuk mendeteksi lonjakan. Ketika jumlah pod dalam mode panic ≥ panic-threshold-percentage / 100 × jumlah pod siap (default: 2×), KPA menggunakan jumlah pod dari mode panic alih-alih jumlah dari mode stabil.
Konfigurasi ConfigMap config-autoscaler
Pengaturan default global KPA terdapat di ConfigMap config-autoscaler dalam namespace knative-serving. Anotasi per-revision akan menggantikan pengaturan default ini.
Periksa konfigurasi saat ini:
kubectl -n knative-serving describe cm config-autoscalerTabel berikut mencantumkan parameter utama. Semua nilai merupakan nilai default.
| Parameter | Default | Deskripsi |
|---|---|---|
container-concurrency-target-default |
100 |
Maksimum permintaan konkuren per pod (batas lunak, global) |
container-concurrency-target-percentage |
70 |
Persentase utilisasi target untuk penskalaan berbasis concurrency |
requests-per-second-target-default |
200 |
Target RPS per pod |
target-burst-capacity |
211 |
Kapasitas burst sebelum Activator melakukan buffering permintaan. 0: Activator hanya digunakan saat skala ke nol. Lebih besar dari 0 dengan container-concurrency-target-percentage pada 100: selalu gunakan Activator. -1: tidak terbatas. |
stable-window |
60s |
Jendela waktu untuk penghitungan rata-rata dalam mode stabil |
panic-window-percentage |
10.0 |
Jendela panic sebagai persentase dari jendela stabil (default: 6 detik) |
panic-threshold-percentage |
200.0 |
Panic dipicu ketika jumlah pod yang diinginkan ≥ panic-threshold-percentage / 100 × jumlah pod siap |
max-scale-up-rate |
1000.0 |
Rasio maksimum jumlah pod yang diinginkan per event scale-out: ceil(max-scale-up-rate × readyPodsCount) |
max-scale-down-rate |
2.0 |
Pod diskalakan masuk hingga paling banyak separuh dari jumlah saat ini per aktivitas |
enable-scale-to-zero |
true |
Apakah layanan idle diskalakan menjadi nol pod |
scale-to-zero-grace-period |
30s |
Waktu maksimum untuk pemutusan jaringan selama proses scale-to-zero |
scale-to-zero-pod-retention-period |
0s |
Waktu minimum pod terakhir dipertahankan setelah traffic berhenti |
pod-autoscaler-class |
kpa.autoscaling.knative.dev |
Jenis autoscaler. Nilai yang didukung: kpa.autoscaling.knative.dev, hpa.autoscaling.knative.dev, aha.autoscaling.knative.dev. Gunakan mpa dengan MSE di kluster ACK Serverless untuk menskalakan ke nol. |
activator-capacity |
100.0 |
Kapasitas permintaan layanan Activator |
initial-scale |
1 |
Jumlah pod awal per revision |
allow-zero-initial-scale |
false |
Apakah sebuah revision dapat dimulai dengan nol pod |
min-scale |
0 |
Jumlah pod minimum per revision (0 = tanpa batas bawah) |
max-scale |
0 |
Jumlah pod maksimum per revision (0 = tidak terbatas) |
scale-down-delay |
0s |
Waktu pada concurrency yang berkurang sebelum scale-in. Berbeda dengan min-scale, pod akhirnya akan diskalakan masuk setelah penundaan ini. Menghindari cold start selama jeda traffic singkat. |
scale-to-zero-grace-period membatasi berapa lama pemrograman jaringan dapat berlangsung selama proses scale-to-zero. Sesuaikan hanya jika Anda mengalami permintaan yang terputus selama scale-to-zero — ini tidak mengontrol berapa lama pod terakhir tetap aktif. Untuk mempertahankan pod terakhir setelah traffic berakhir, gunakan scale-to-zero-pod-retention-period sebagai gantinya.
Konfigurasi metrik penskalaan
Tetapkan metrik penskalaan per revision dengan anotasi autoscaling.knative.dev/metric. Default: concurrency.
| Metrik | Jenis autoscaler yang diperlukan | Deskripsi |
|---|---|---|
concurrency |
kpa.autoscaling.knative.dev (default) |
Permintaan in-flight konkuren per pod |
rps |
kpa.autoscaling.knative.dev (default) |
Permintaan per detik per pod |
cpu |
hpa.autoscaling.knative.dev |
Utilisasi CPU |
memory |
hpa.autoscaling.knative.dev |
Utilisasi memori |
| Metrik kustom | Bervariasi | Metrik kustom sesuai kebutuhan aplikasi |
Metrik concurrency (default)
apiVersion: serving.knative.dev/v1
kind: Service
metadata:
name: helloworld-go
namespace: default
spec:
template:
metadata:
annotations:
autoscaling.knative.dev/metric: "concurrency"Metrik RPS
apiVersion: serving.knative.dev/v1
kind: Service
metadata:
name: helloworld-go
namespace: default
spec:
template:
metadata:
annotations:
autoscaling.knative.dev/metric: "rps"Metrik CPU
Penskalaan berbasis CPU memerlukan kelas autoscaler HPA.
apiVersion: serving.knative.dev/v1
kind: Service
metadata:
name: helloworld-go
namespace: default
spec:
template:
metadata:
annotations:
autoscaling.knative.dev/class: "hpa.autoscaling.knative.dev"
autoscaling.knative.dev/metric: "cpu"Metrik memori
Penskalaan berbasis memori juga memerlukan kelas autoscaler HPA.
apiVersion: serving.knative.dev/v1
kind: Service
metadata:
name: helloworld-go
namespace: default
spec:
template:
metadata:
annotations:
autoscaling.knative.dev/class: "hpa.autoscaling.knative.dev"
autoscaling.knative.dev/metric: "memory"Konfigurasi target penskalaan
Target penskalaan menetapkan nilai metrik yang dipertahankan KPA per pod. Konfigurasi dapat dilakukan per revision atau secara global.
Target concurrency
Per revision — gunakan autoscaling.knative.dev/target:
apiVersion: serving.knative.dev/v1
kind: Service
metadata:
name: helloworld-go
namespace: default
spec:
template:
metadata:
annotations:
autoscaling.knative.dev/target: "50"Global — perbarui ConfigMap config-autoscaler:
apiVersion: v1
kind: ConfigMap
metadata:
name: config-autoscaler
namespace: knative-serving
data:
container-concurrency-target-default: "200"Target RPS
Per revision:
apiVersion: serving.knative.dev/v1
kind: Service
metadata:
name: helloworld-go
namespace: default
spec:
template:
metadata:
annotations:
autoscaling.knative.dev/target: "150"
autoscaling.knative.dev/metric: "rps"
spec:
containers:
- image: registry.cn-hangzhou.aliyuncs.com/knative-sample/helloworld-go:73fbdd56Global:
apiVersion: v1
kind: ConfigMap
metadata:
name: config-autoscaler
namespace: knative-serving
data:
requests-per-second-target-default: "150"Konfigurasi batas concurrency
Batas concurrency membatasi jumlah permintaan konkuren per pod. KPA mendukung dua jenis batas.
Batas concurrency lunak
Batas lunak adalah target yang dituju oleh KPA saat menskalakan. Batas ini tidak diberlakukan secara ketat — lonjakan dapat melebihi batas tersebut sesaat.
Per revision:
apiVersion: serving.knative.dev/v1
kind: Service
metadata:
name: helloworld-go
namespace: default
spec:
template:
metadata:
annotations:
autoscaling.knative.dev/target: "200"Global:
apiVersion: v1
kind: ConfigMap
metadata:
name: config-autoscaler
namespace: knative-serving
data:
container-concurrency-target-default: "200"Batas concurrency keras
Batas keras diberlakukan secara ketat — permintaan berlebih akan dibuffer. Tetapkan batas keras hanya jika aplikasi Anda memiliki batas atas concurrency yang pasti; nilai rendah akan mengurangi throughput dan meningkatkan latency.
Per revision — gunakan bidang spesifikasi containerConcurrency (bukan anotasi):
apiVersion: serving.knative.dev/v1
kind: Service
metadata:
name: helloworld-go
namespace: default
spec:
template:
spec:
containerConcurrency: 50Utilisasi target
Utilisasi target mengontrol seberapa penuh pod berjalan sebelum KPA melakukan scale-out. Pada utilisasi 70% dengan containerConcurrency: 10, KPA membuat pod baru ketika rata-rata concurrency di seluruh pod yang ada mencapai 7. Nilai yang lebih rendah membuat KPA melakukan scale-out lebih awal, sehingga mengurangi latency cold start.
Per revision:
apiVersion: serving.knative.dev/v1
kind: Service
metadata:
name: helloworld-go
namespace: default
spec:
template:
metadata:
annotations:
autoscaling.knative.dev/target-utilization-percentage: "70"
spec:
containers:
- image: registry.cn-hangzhou.aliyuncs.com/knative-sample/helloworld-go:73fbdd56Global:
apiVersion: v1
kind: ConfigMap
metadata:
name: config-autoscaler
namespace: knative-serving
data:
container-concurrency-target-percentage: "70"Konfigurasi scale-to-zero
Aktifkan atau nonaktifkan scale-to-zero secara global
Atur enable-scale-to-zero ke "false" untuk memastikan setidaknya satu pod tetap berjalan ketika layanan idle:
apiVersion: v1
kind: ConfigMap
metadata:
name: config-autoscaler
namespace: knative-serving
data:
enable-scale-to-zero: "false"Konfigurasi periode tenggang scale-to-zero
scale-to-zero-grace-period membatasi berapa lama pemrograman jaringan dapat berlangsung selama proses scale-to-zero.
Tingkatkan hanya jika Anda mengalami permintaan yang terputus selama scale-to-zero. Ini tidak mengontrol berapa lama pod terakhir tetap aktif. Untuk mempertahankan pod terakhir, gunakan scale-to-zero-pod-retention-period sebagai gantinya.
apiVersion: v1
kind: ConfigMap
metadata:
name: config-autoscaler
namespace: knative-serving
data:
scale-to-zero-grace-period: "40s"Konfigurasi periode retensi pod
scale-to-zero-pod-retention-period mempertahankan pod terakhir selama durasi minimum setelah traffic berhenti, sehingga menghindari cold start pada layanan dengan traffic intermiten.
Per revision:
apiVersion: serving.knative.dev/v1
kind: Service
metadata:
name: helloworld-go
namespace: default
spec:
template:
metadata:
annotations:
autoscaling.knative.dev/scale-to-zero-pod-retention-period: "1m5s"
spec:
containers:
- image: registry.cn-hangzhou.aliyuncs.com/knative-sample/helloworld-go:73fbdd56Global:
apiVersion: v1
kind: ConfigMap
metadata:
name: config-autoscaler
namespace: knative-serving
data:
scale-to-zero-pod-retention-period: "42s"Konfigurasi batas skala
Batas skala menetapkan jumlah replika minimum dan maksimum untuk sebuah revision.
| Anotasi | Parameter (global) | Tujuan |
|---|---|---|
autoscaling.knative.dev/min-scale |
min-scale |
Batas bawah — KPA tidak pernah menskalakan di bawah jumlah ini |
autoscaling.knative.dev/max-scale |
max-scale |
Batas atas — KPA tidak pernah menskalakan di atas jumlah ini (0 = tidak terbatas) |
min-scalemempertahankan batas bawah pod permanen. Untuk menunda scale-in tanpa batas bawah permanen, gunakanscale-down-delaydiconfig-autoscalersebagai gantinya — pod tetap akan diskalakan masuk setelah penundaan tersebut.
Contoh
Contoh 1: Skala berdasarkan target concurrency
Deploy aplikasi auto-scaling dengan target concurrency 10 dan uji dengan 50 permintaan konkuren.
-
Buat file
autoscale-go.yamldengan konten berikut:apiVersion: serving.knative.dev/v1 kind: Service metadata: name: autoscale-go namespace: default spec: template: metadata: labels: app: autoscale-go annotations: autoscaling.knative.dev/target: "10" # Target concurrency: 10 permintaan per pod spec: containers: - image: registry.cn-hangzhou.aliyuncs.com/knative-sample/autoscale-go:0.1 -
Terapkan manifes:
kubectl apply -f autoscale-go.yaml -
Dapatkan alamat gateway Ingress. ALB:
kubectl get albconfig knative-internetOutput yang diharapkan:
NAME ALBID DNSNAME PORT&PROTOCOL CERTID AGE knative-internet alb-hvd8nngl0lsdra15g0 alb-hvd8nng******.cn-beijing.alb.aliyuncs.com 2MSE:
kubectl -n knative-serving get ing stats-ingressOutput yang diharapkan:
NAME CLASS HOSTS ADDRESS PORTS AGE stats-ingress knative-ingressclass * 101.201.XX.XX,192.168.XX.XX 80 15dASM:
kubectl get svc istio-ingressgateway --namespace istio-system --output jsonpath="{.status.loadBalancer.ingress[*]['ip']}"Output yang diharapkan:
121.XX.XX.XXKourier:
kubectl -n knative-serving get svc kourierOutput yang diharapkan:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kourier LoadBalancer 10.0.XX.XX 39.104.XX.XX 80:31133/TCP,443:32515/TCP 49m -
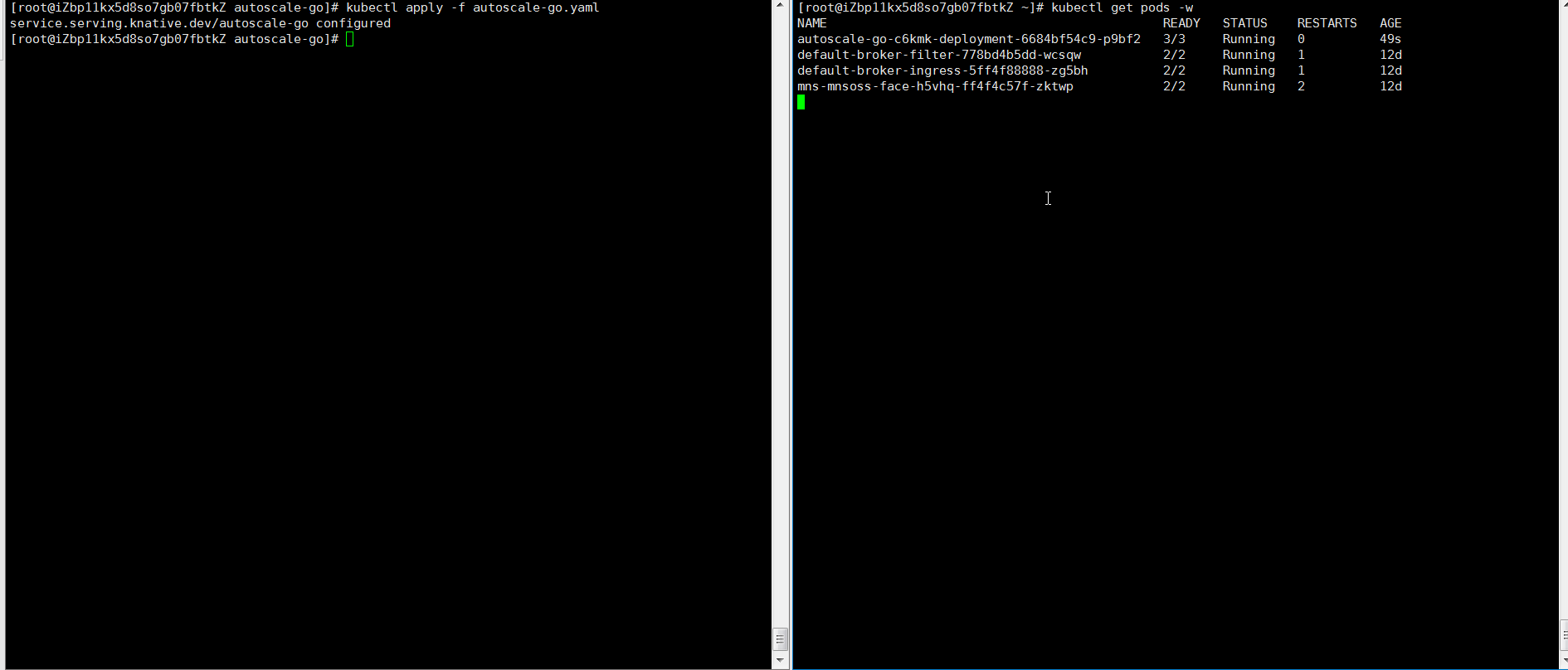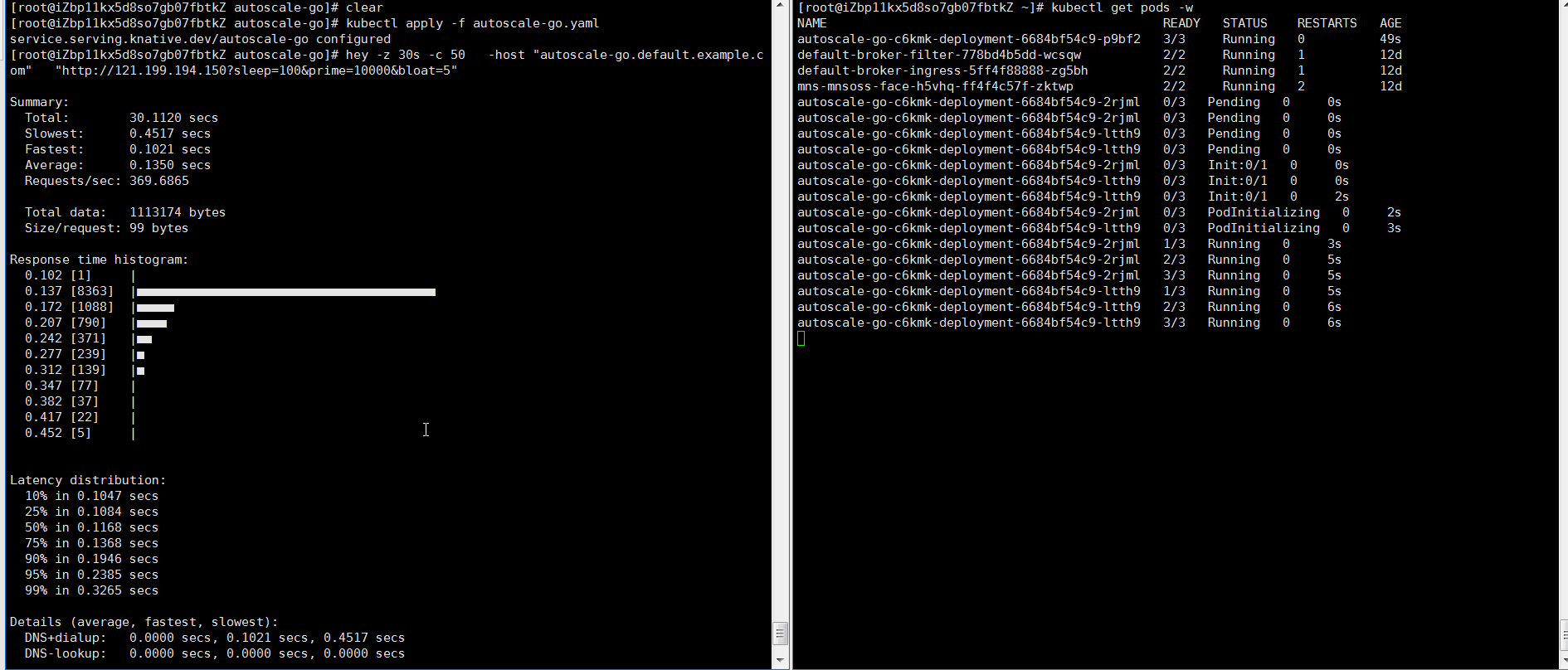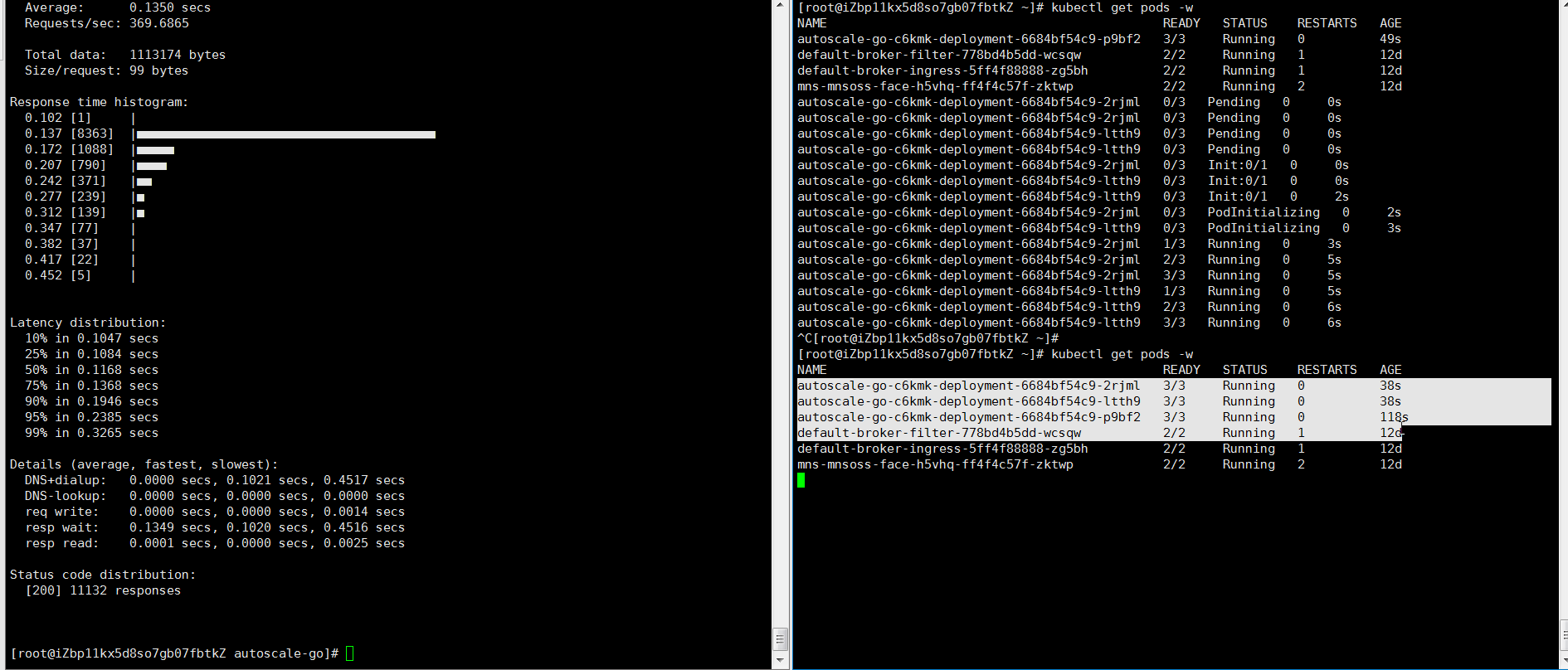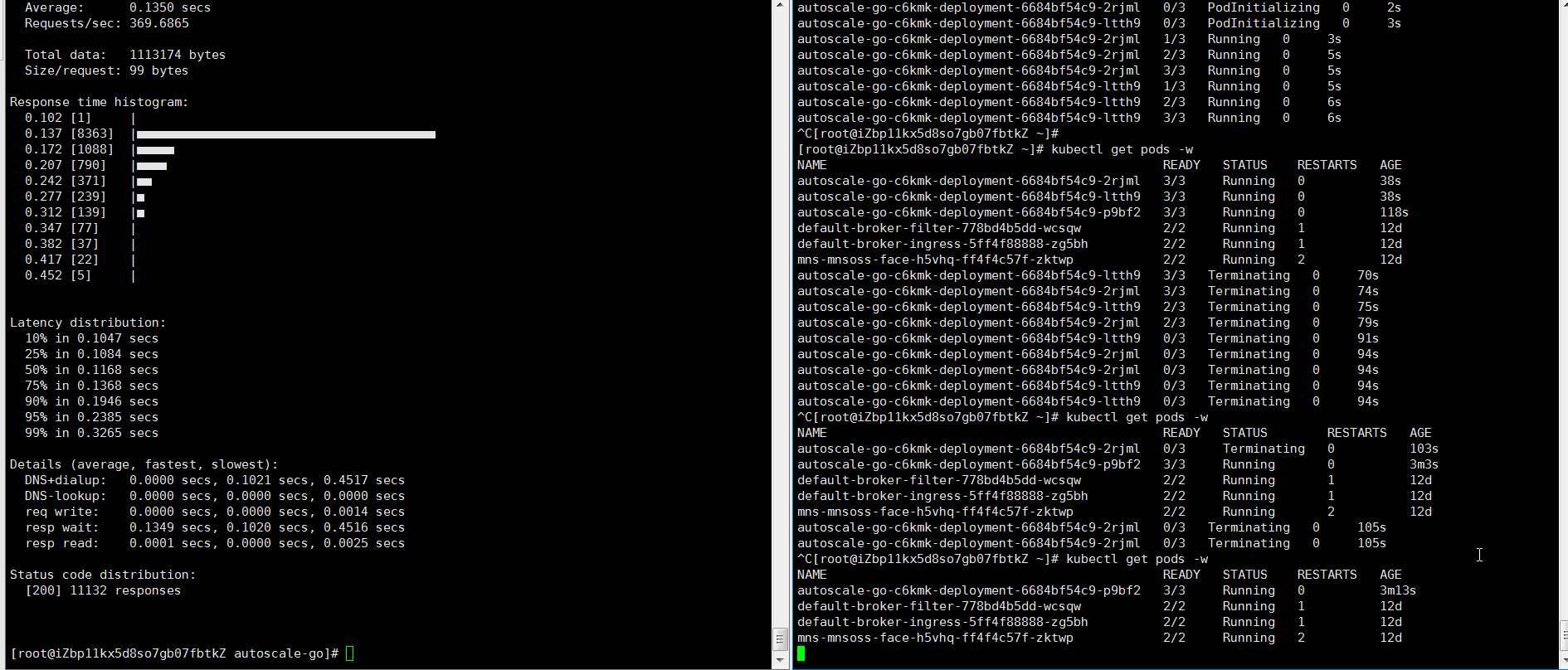
Kirim 50 permintaan konkuren selama 30 detik menggunakan hey:
hey -z 30s -c 50 \ -host "autoscale-go.default.example.com" \ "http://121.199.XXX.XXX" # Ganti dengan alamat gateway Ingress AndaOutput yang diharapkan: KPA menambahkan 5 pod: 50 permintaan konkuren ÷ target 10 = 5 pod.
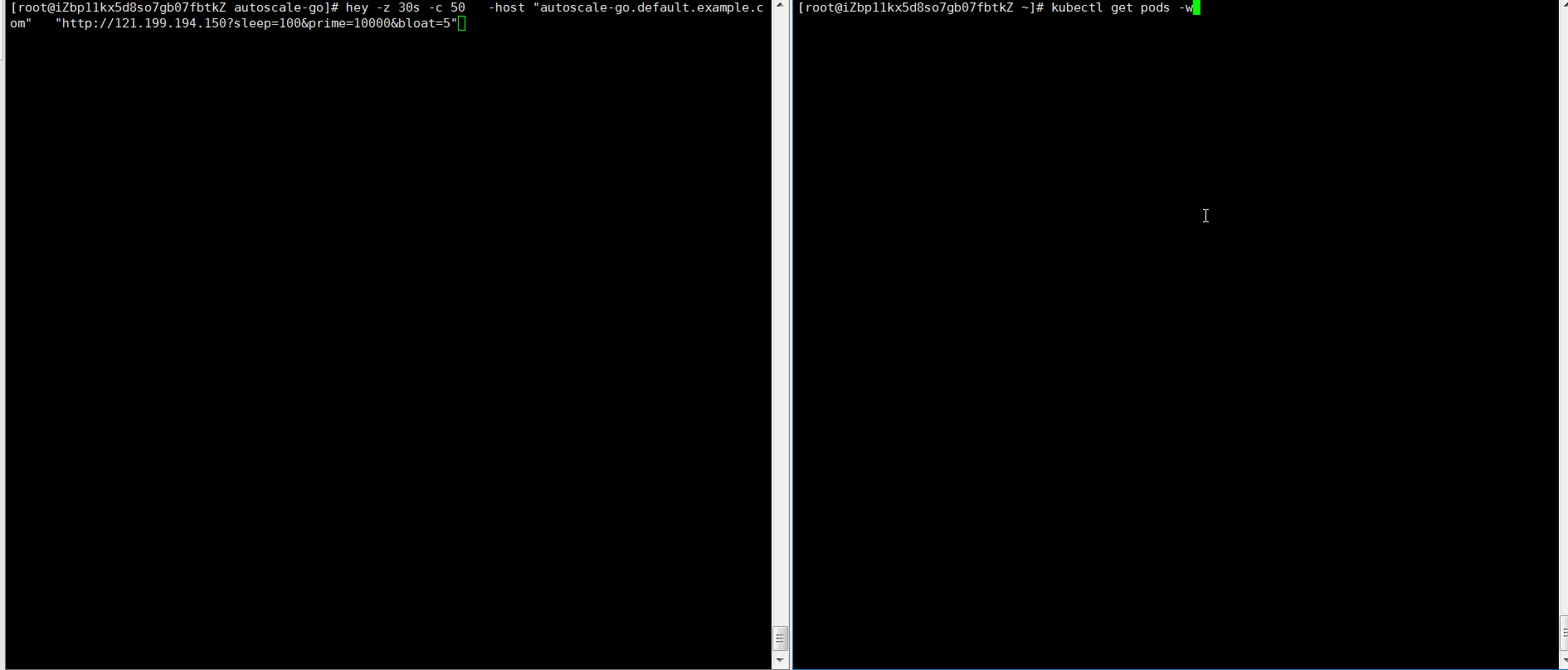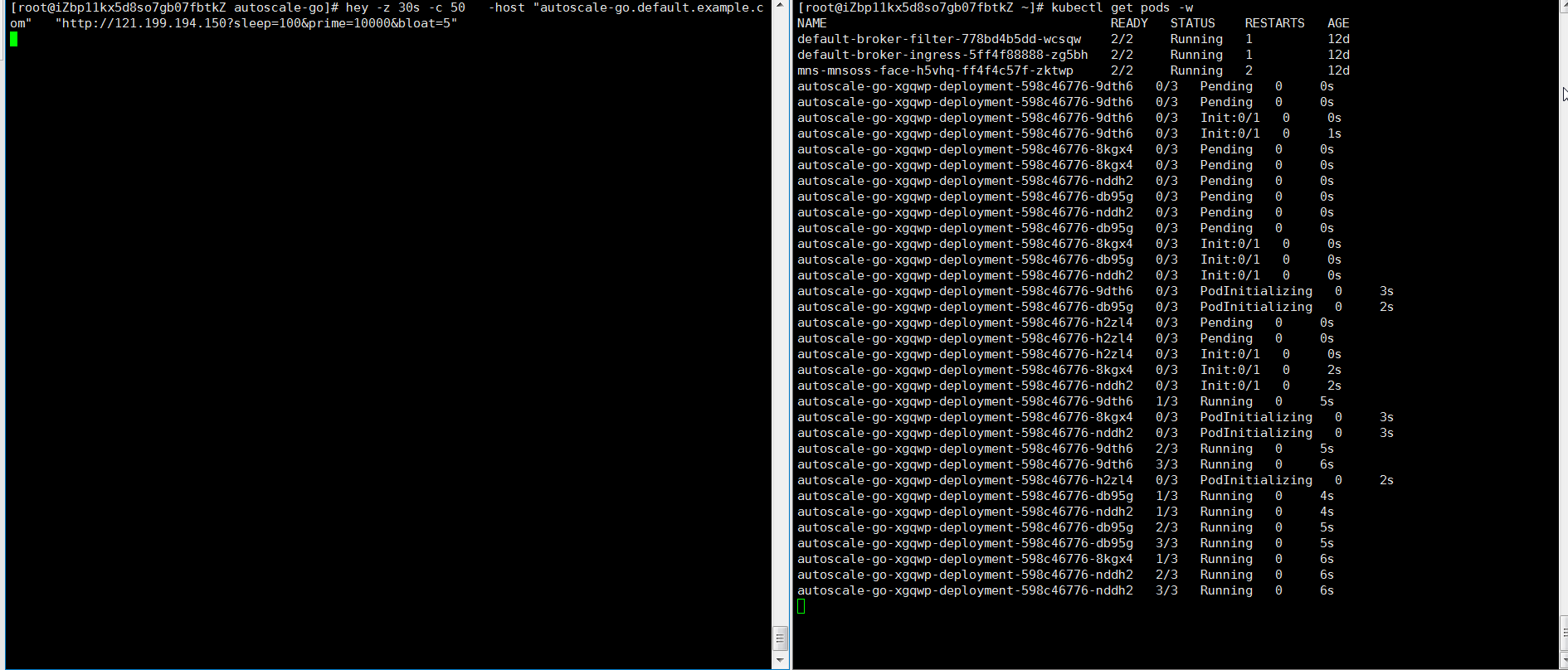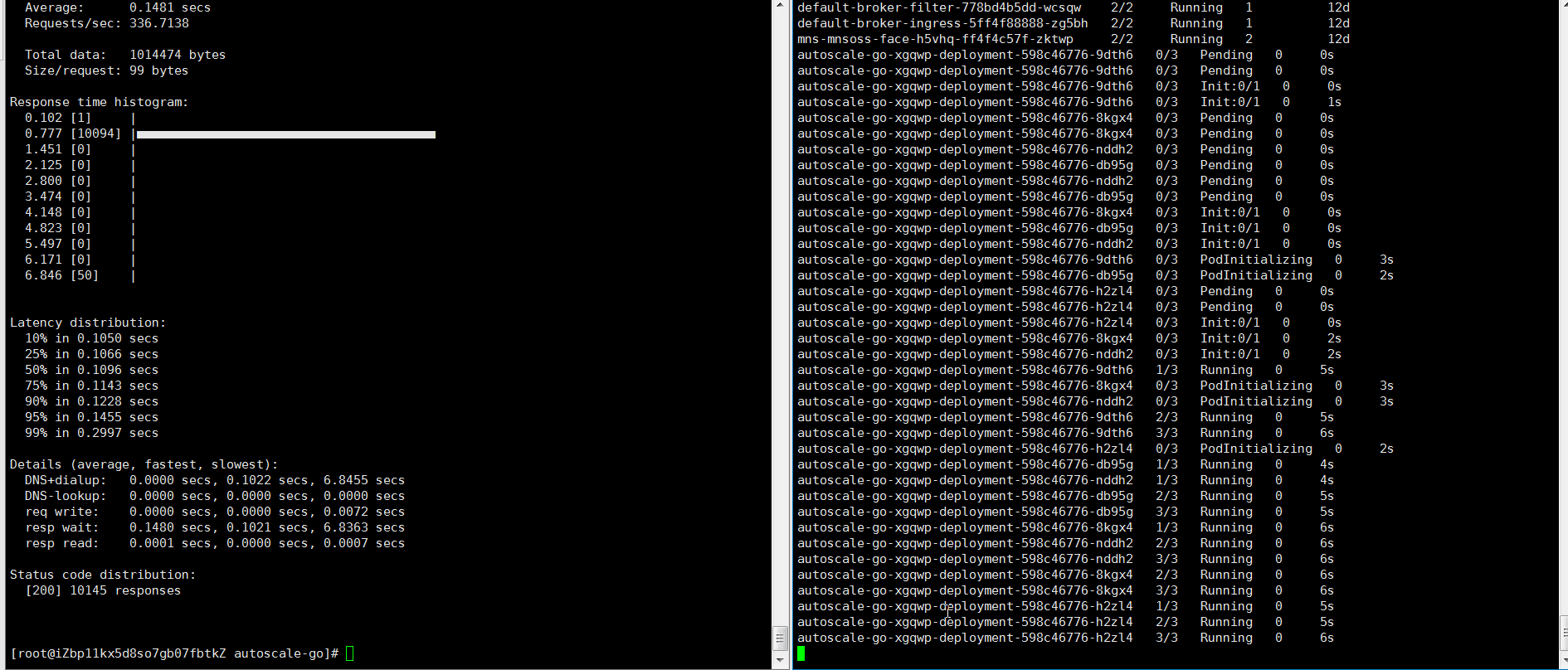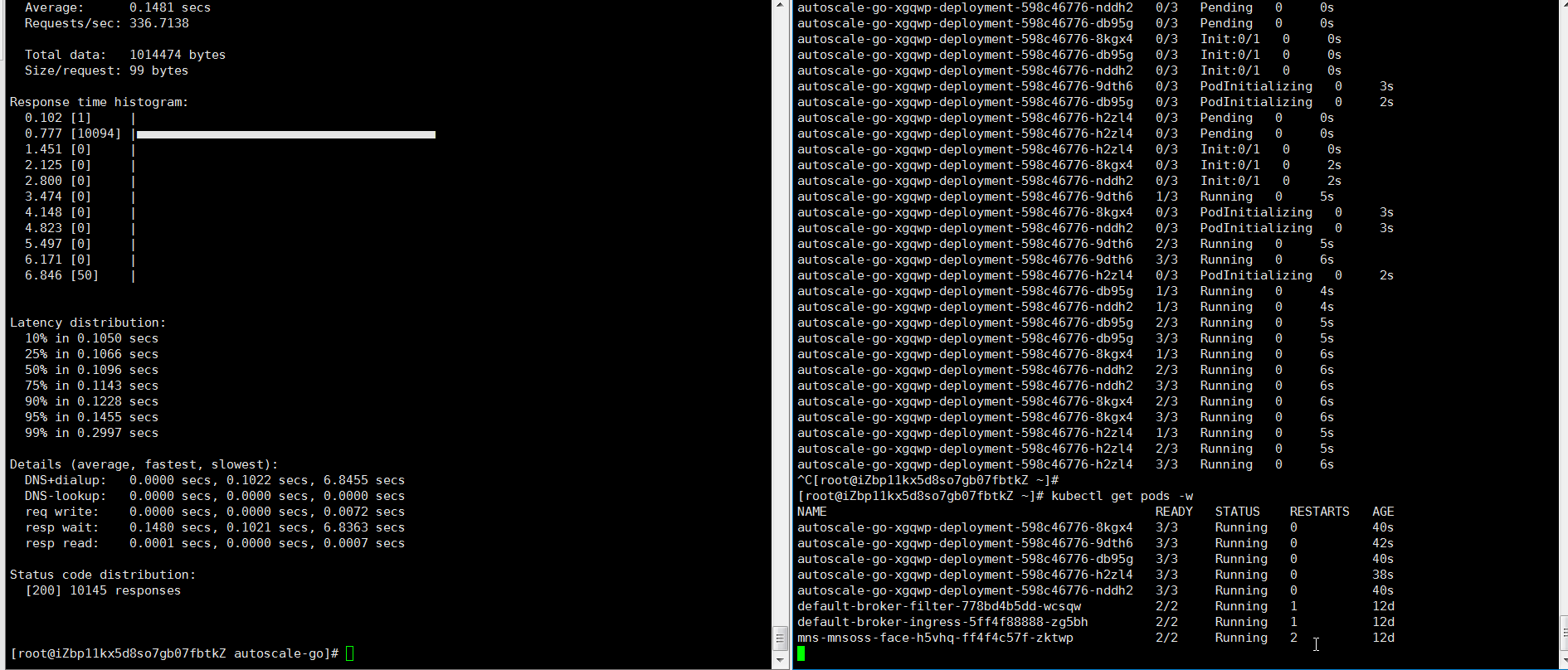
Contoh 2: Skala dengan batas
Tambahkan min-scale: 1 dan max-scale: 3 untuk memastikan satu pod tetap berjalan dan membatasi deployment maksimal tiga pod.
-
Buat file
autoscale-go.yamldengan konten berikut:apiVersion: serving.knative.dev/v1 kind: Service metadata: name: autoscale-go namespace: default spec: template: metadata: labels: app: autoscale-go annotations: autoscaling.knative.dev/target: "10" autoscaling.knative.dev/min-scale: "1" # Pertahankan minimal 1 pod berjalan autoscaling.knative.dev/max-scale: "3" # Batasi maksimal 3 pod spec: containers: - image: registry.cn-hangzhou.aliyuncs.com/knative-sample/autoscale-go:0.1 -
Terapkan manifes:
kubectl apply -f autoscale-go.yaml -
Dapatkan alamat gateway Ingress (Contoh 1, langkah 4).
-
Kirim 50 permintaan konkuren selama 30 detik:
hey -z 30s -c 50 \ -host "autoscale-go.default.example.com" \ "http://121.199.XXX.XXX" # Ganti dengan alamat gateway Ingress AndaOutput yang diharapkan: KPA menskalakan hingga 3 pod (maksimum) selama beban tinggi, lalu kembali ke 1 pod (minimum) — tidak ada cold start pada permintaan berikutnya.