Topik ini menjelaskan cara memecahkan masalah pod, termasuk prosedur diagnostik dan solusi untuk masalah umum.
Untuk melakukan tugas pemecahan masalah pod umum di Konsol, seperti melihat status pod, informasi dasar, konfigurasi, event, dan log, mengakses kontainer menggunakan terminal, serta mengaktifkan diagnostik pod, lihat Prosedur Pemecahan Masalah Umum.
Prosedur diagnostik cepat
Untuk mendiagnosis pod workload yang tidak normal, buka halaman detail Pods yang dituju. Klik tab Events untuk meninjau deskripsi event tidak normal. Kemudian, klik tab Logs untuk memeriksa log tidak normal terbaru.
Pod dalam status Pending
Jika sebuah Pod memiliki status Unschedulable di bagian Status Details-nya atau muncul event FailedScheduling di Events, buka untuk memeriksa status kesehatan dan tingkat sumber daya (CPU dan memori) node target. Selain itu, periksa apakah kebijakan afinitas Pod terlalu ketat, termasuk konfigurasi nodeSelector, nodeAffinity, serta Taint dan Toleration-nya. Untuk pemecahan masalah lebih lanjut, lihat Masalah penjadwalan.
Gagal menarik gambar (ImagePullBackOff/ErrImagePull)
Di halaman detail Pods, buka tab Container dan periksa alamat Image. Login ke node pod tersebut dan jalankan crictl pull <image-address> atau curl -v https://<image-address> untuk memverifikasi konektivitas jaringan ke repositori gambar. Di pojok kanan atas, klik Edit YAML dan pastikan Secret yang ditentukan di field spec.imagePullSecrets workload ada dan valid. Untuk pemecahan masalah lebih lanjut, lihat masalah penarikan gambar.
Pod gagal dimulai (CrashLoopBackOff)
Kesalahan ini terjadi ketika aplikasi berulang kali crash dan restart. Di halaman detail Pods, klik tab Logs dan pilih Show the log of the last container exit untuk melihat penyebab kegagalan. Untuk pemecahan masalah lebih lanjut, lihat Memecahkan masalah kegagalan startup pod.
Pod Berjalan tetapi tidak siap
Status ini terjadi ketika pemeriksaan kesiapan (readiness probe) pod gagal. Di halaman Edit Workloads yang dituju, verifikasi bahwa path permintaan pemeriksaan kesehatan (misalnya, /healthz) dan port sesuai dengan yang disediakan oleh aplikasi. Untuk pemecahan masalah lebih lanjut, lihat Pod Berjalan tetapi tidak siap (Ready: False).
Anda dapat sementara menonaktifkan pemeriksaan kesehatan. Kemudian, akses terminal pod atau node host-nya dan gunakan perintah seperti curl untuk memverifikasi bahwa pemeriksaan kesehatan berhasil.
Pod mengalami OOMKilled
Di halaman detail Pods, klik tab Logs dan pilih Show the log of the last container exit untuk melihat log OOM. Periksa apakah aplikasi mengalami kebocoran memori atau error kehabisan memori (OOM). Untuk aplikasi Java, Anda dapat mengoptimalkan parameter -Xmx. Sesuaikan batas sumber daya memori aplikasi (resources.limits.memory) sesuai kebutuhan. Untuk pemecahan masalah lebih lanjut, lihat OOMKilled.
Jika pemeriksaan kelangsungan hidup (liveness probe) dikonfigurasi, pod hanya akan berada dalam status OOMKilled sebentar sebelum secara otomatis restart.
Alur kerja diagnostik
Untuk mendiagnosis pod yang tidak normal, periksa event, log, dan konfigurasinya.
Fase 1: Masalah penjadwalan
Pod belum dijadwalkan ke node
Jika pod tetap dalam status Pending dalam waktu lama, artinya pod tersebut belum dijadwalkan ke node. Bagian ini menjelaskan penyebab umum dan solusinya.
|
Pesan error |
Deskripsi |
Solusi |
|
|
Kluster tidak memiliki node yang tersedia untuk penjadwalan pod. |
|
|
Tidak ada node yang tersedia di kluster yang dapat memenuhi permintaan sumber daya CPU atau memori pod. Node dianggap tidak dapat dijadwalkan jika jumlah alokasi sumber daya
|
Di halaman detail kluster target, buka dan periksa tingkat alokasi requests CPU atau memori untuk node target. Anda dapat mengarahkan kursor ke tingkat alokasi untuk melihat nilai alokasi sumber daya spesifik.
Untuk melihat penggunaan sumber daya node secara rinci, lihat Gunakan kubectl untuk melihat penggunaan sumber daya node.
|
|
|
Node yang ada di kluster tidak sesuai dengan kebijakan afinitas node ( |
|
|
|
|
|
|
Penjadwalan gagal karena konflik afinitas node volume. Ini biasanya terjadi karena disk cloud tidak dapat dipasang lintas zona berbeda. |
|
|
|
Instans ECS tidak mendukung tipe disk cloud yang ditentukan. |
Lihat Famili instans untuk mengonfirmasi tipe disk cloud yang didukung oleh instans ECS Anda. Saat memasang, perbarui tipe disk cloud ke tipe yang didukung oleh instans ECS. |
|
|
Pod tidak dapat dijadwalkan ke node karena tidak memiliki toleransi terhadap salah satu taint node tersebut. |
|
|
|
Node memiliki penyimpanan sementara yang tidak mencukupi. |
|
|
|
Pod gagal mengikat klaim volume persisten (PVC). |
Periksa apakah PVC atau PV yang ditentukan oleh pod telah dibuat. Jalankan |

Pod telah dijadwalkan tetapi tetap dalam status Pending
Jika pod telah dijadwalkan ke node tetapi tetap dalam status Pending, ikuti langkah-langkah berikut untuk menyelesaikan masalah.
-
Tentukan apakah Pod dikonfigurasi dengan
hostPort: Jika Pod dikonfigurasi denganhostPort, hanya satu instance Pod yang menggunakanhostPorttersebut yang dapat berjalan di setiap node. Oleh karena itu, nilaiReplicasdalam Deployment atau ReplicationController tidak boleh melebihi jumlah node di kluster. Jika port ini sedang digunakan oleh aplikasi lain, penjadwalan Pod gagal.hostPortmenimbulkan beberapa kompleksitas manajemen dan penjadwalan. Kami menyarankan Anda menggunakan Service untuk mengakses Pod. Untuk informasi lebih lanjut, lihat Service. -
Jika Pod tidak dikonfigurasi dengan
hostPort, ikuti langkah-langkah berikut untuk pemecahan masalah.-
Jalankan
kubectl describe pod <pod-name>untuk melihat event pod dan selesaikan masalah yang ditemukan. Event dapat menjelaskan mengapa pod gagal dimulai, dengan alasan umum termasuk kegagalan penarikan gambar, sumber daya tidak mencukupi, pembatasan kebijakan keamanan, atau kesalahan konfigurasi. -
Jika objek Event tidak berisi informasi berguna, periksa log kubelet di node untuk memecahkan masalah selama proses startup Pod. Anda dapat menggunakan perintah
grep -i <pod name> /var/log/messages* | lessuntuk mencari file log sistem (/var/log/messages*) guna menemukan entri log yang berisi nama Pod tertentu.
-
Fase 2: Masalah penarikan gambar
ImagePullBackOff atau ErrImagePull
Status pod ImagePullBackOff atau ErrImagePull menunjukkan bahwa penarikan gambar gagal. Dalam kasus ini, periksa event pod dan gunakan informasi di bawah ini untuk memecahkan masalah.
|
Pesan error |
Deskripsi |
Solusi yang disarankan |
||||||
|
|
Akses ke repositori gambar ditolak karena |
Verifikasi bahwa Secret yang ditentukan di field Saat menggunakan Container Registry (ACR), Anda dapat menggunakan credential helper untuk menarik gambar tanpa kata sandi. Untuk informasi lebih lanjut, lihat Menarik gambar dari akun yang sama. |
||||||
|
|
Alamat repositori gambar tidak dapat diselesaikan saat menarik gambar melalui HTTPS. |
|
||||||
|
|
Node memiliki ruang disk yang tidak mencukupi. |
Login ke node tempat pod berjalan (untuk informasi lebih lanjut, lihat Memilih metode koneksi jarak jauh ECS) dan jalankan |
||||||
|
|
Repositori gambar pihak ketiga menggunakan sertifikat yang ditandatangani oleh Certificate Authority (CA) yang tidak dikenal atau tidak aman. |
KonsolMengonfigurasi parameter containerd menggunakan konsolPenting
Perubahan ini tidak memengaruhi kontainer yang sudah ada. Untuk menjaga stabilitas kluster, lakukan operasi ini selama jam sepi.
Contoh konfigurasi
CLI
|
||||||
|
|
Operasi dibatalkan, kemungkinan karena file gambar terlalu besar. Kubernetes memiliki timeout default untuk menarik gambar. Jika penarikan tidak menunjukkan progres selama periode tertentu, Kubernetes menganggap operasi gagal atau tidak merespons dan membatalkan tugas. |
|
||||||
|
|
Tidak dapat terhubung ke repositori gambar karena masalah jaringan. |
|
||||||
|
|
Koneksi timeout karena masalah jaringan saat menarik gambar dari repositori luar negeri. |
Menarik gambar dari repositori luar negeri, seperti Docker Hub, mungkin gagal di kluster ACK karena jaringan penyedia layanan tidak stabil. Untuk mengatasi hal ini, pertimbangkan solusi berikut:
|
||||||
|
|
Docker Hub memberlakukan pembatasan laju pada permintaan penarikan gambar. |
Unggah gambar ke Container Registry (ACR) dan tarik dari repositori gambar ACR. |
||||||
|
Status |
Mekanisme pembatasan laju penarikan gambar kubelet mungkin telah dipicu. |
Sesuaikan |



Fase 3: Masalah startup
Pod dalam status Init
|
Pesan error |
Deskripsi |
Solusi |
|
Terkunci dalam status |
Pod berisi M init container. N di antaranya telah selesai, tetapi M-N init container yang tersisa gagal dimulai. |
Untuk informasi lebih lanjut tentang init container, lihat Debug init containers. |
|
Terkunci dalam status |
Init container di pod gagal dimulai. |
|
|
Terkunci dalam status |
Init container di pod gagal dimulai dan berada dalam loop restart. |
Pod dalam status Creating
|
Pesan error |
Deskripsi |
Solusi |
|
|
Ini adalah perilaku yang diharapkan karena desain plugin jaringan Flannel. |
Tingkatkan komponen Flannel ke v0.15.1.11-7e95fe23-aliyun atau yang lebih baru. Untuk informasi lebih lanjut, lihat Flannel. |
|
Di kluster yang menjalankan versi Kubernetes sebelum 1.20, kebocoran alamat IP dapat terjadi jika pod restart berulang kali atau jika pod dari CronJob menyelesaikan tugasnya dan keluar dengan cepat. |
Tingkatkan kluster ke Kubernetes 1.20 atau yang lebih baru. Kami menyarankan menggunakan versi kluster terbaru. Untuk informasi lebih lanjut, lihat Meningkatkan kluster secara manual. |
|
|
Cacat pada containerd dan runC menyebabkan masalah ini. |
Untuk perbaikan darurat, lihat Mengapa pod saya gagal dimulai dengan error "no IP addresses available in range"? |
|
|
|
Plugin jaringan Terway memelihara basis data internal di node untuk melacak dan mengelola elastic network interfaces (ENIs). Error ini terjadi ketika status basis data tidak konsisten dengan konfigurasi perangkat jaringan aktual, menyebabkan alokasi ENI gagal. |
|
|
Plugin jaringan Terway mungkin gagal meminta alamat IP dari vSwitch. |
|
Pod gagal dimulai (CrashLoopBackOff)
|
Pesan error |
Deskripsi |
Solusi |
|
Log berisi |
|
|
|
Event pod menunjukkan |
Pemeriksaan kelangsungan hidup (liveness probe) gagal, menyebabkan aplikasi restart. |
|
|
Event pod menunjukkan |
Pemeriksaan startup gagal, menyebabkan aplikasi restart. |
|
|
Log pod berisi |
Ruang disk cloud tidak mencukupi. |
|
|
Startup gagal tanpa informasi event. |
Masalah ini terjadi ketika kontainer memerlukan lebih banyak sumber daya daripada batas yang dideklarasikan, menyebabkan kegagalan. |
Periksa apakah konfigurasi sumber daya pod benar. Anda dapat mengaktifkan profil sumber daya untuk mendapatkan rekomendasi konfigurasi Request dan Limit untuk kontainer. |
|
Log pod menunjukkan |
Terjadi konflik port antara kontainer dalam pod yang sama. |
|
|
Log pod menunjukkan |
Workload memasang Secret, tetapi nilai dalam Secret tidak di-encode Base64. |
|
|
Masalah spesifik aplikasi. |
Periksa log pod untuk memecahkan masalah. |
|
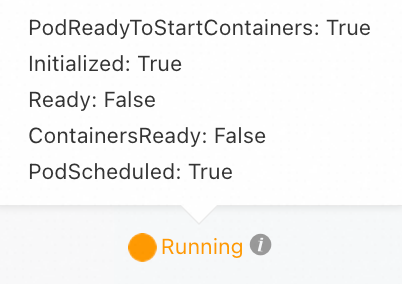
Pod Berjalan tetapi tidak siap (Ready: False)
|
Pesan error |
Deskripsi |
Solusi |
|
|
Pemeriksaan kesiapan (readiness probe) gagal, mencegah pod target menerima trafik. |
|
|
Status pod sama seperti di atas. Event pod menunjukkan |
Pemeriksaan startup yang gagal menyebabkan kontainer restart. Error ini seharusnya tidak menghasilkan status Running/NotReady yang persisten, melainkan status 'CrashLoopBackOff'. |
Pecahkan masalah ini seperti yang dijelaskan di bagian "Pod gagal dimulai (CrashLoopBackOff)" untuk Startup. |
 Event pod menunjukkan
Event pod menunjukkan Fase 4: Masalah runtime Pod
OOMKilled
Ketika kontainer di kluster Anda menggunakan lebih banyak memori daripada batas yang ditentukan, kontainer tersebut mungkin dihentikan karena event kehabisan memori (OOM), menyebabkan kontainer keluar secara tak terduga. Untuk informasi lebih lanjut tentang event OOM, lihat Menetapkan Sumber Daya Memori untuk Kontainer dan Pod.
-
Jika proses yang dihentikan adalah proses utama kontainer, kontainer mungkin restart secara tak terduga.
-
Saat event OOM terjadi, muncul di tab Events halaman detail pod di konsol, seperti
pod was OOM killed. node:XXX pod:XXX namespace:XXX. -
Jika Anda mengonfigurasi alert untuk pengecualian replika kontainer untuk kluster, Anda akan menerima notifikasi saat event OOM terjadi. Untuk informasi lebih lanjut, lihat Aturan set alert pengecualian replika kontainer.
|
Tingkat OOM |
Deskripsi |
Solusi yang direkomendasikan |
|
Tingkat OS |
Periksa log kernel di |
|
|
Tingkat cgroup |
Periksa log kernel di |
|
Untuk informasi lebih lanjut tentang penyebab dan solusi event OOM, lihat Penyebab dan solusi untuk OOM Killer.
Terminating
|
Kemungkinan penyebab |
Deskripsi |
Solusi yang direkomendasikan |
|
Node berada dalam status NotReady. |
Pod secara otomatis dihapus setelah node pulih dari status NotReady. |
|
|
Pod dikonfigurasi dengan finalizer. |
Jika pod dikonfigurasi dengan finalizer, Kubernetes melakukan operasi pembersihan yang ditentukan oleh finalizer sebelum menghapus pod. Jika operasi pembersihan gagal merespons, pod tetap dalam status Terminating. |
Jalankan perintah |
|
Hook preStop pod tidak valid atau macet. |
Jika hook preStop dikonfigurasi untuk pod, Kubernetes mengeksekusi hook tersebut sebelum menghentikan kontainer. Pod tetap dalam status Terminating selama hook berjalan. |
Jalankan perintah |
|
Periode shutdown yang mulus dikonfigurasi untuk pod. |
Jika Pod dikonfigurasi dengan periode shutdown yang mulus ( |
Kubernetes secara otomatis menghapus pod setelah kontainer menyelesaikan shutdown yang mulus. |
|
Kontainer tidak merespons. |
Saat Anda meminta untuk menghentikan atau menghapus pod, Kubernetes mengirim sinyal |
|
Evicted
|
Kemungkinan penyebab |
Deskripsi |
Solusi yang direkomendasikan |
|
Node mengalami tekanan sumber daya dari faktor seperti penggunaan memori atau disk. |
Node mungkin mengalami tekanan memori, tekanan disk, atau tekanan PID.
|
|
|
Eviksi tidak terduga terjadi. |
Taint NoExecute yang ditambahkan secara manual pada node pod menyebabkan eviksi tidak terduga. |
Jalankan perintah |
|
Eviksi tidak berjalan seperti yang diharapkan. |
|
Di kluster kecil (50 node atau kurang), jika lebih dari 55% node gagal, eviksi pod berhenti. Untuk informasi lebih lanjut, lihat Batas laju eviksi. |
|
Di kluster besar (lebih dari 50 node), jika fraksi node tidak sehat melebihi |
||
|
Pod sering dijadwalkan ulang ke node asalnya setelah dieviksi. |
Kubelet mengeviksi pod berdasarkan penggunaan sumber daya aktual, sedangkan penjadwal menempatkan pod berdasarkan permintaan sumber daya. Karena eviksi membebaskan sumber daya, penjadwal mungkin menjadwalkan ulang pod ke node yang sama jika permintaannya masih sesuai. |
Pastikan permintaan sumber daya pod sesuai untuk sumber daya yang dapat dialokasikan node, dan sesuaikan jika perlu. Untuk informasi lebih lanjut, lihat Menetapkan sumber daya CPU dan memori untuk kontainer. Anda juga dapat mengaktifkan profil sumber daya untuk mendapatkan rekomendasi konfigurasi request dan limit untuk kontainer Anda. |
Completed
Saat pod berada dalam status Completed, semua kontainernya telah menyelesaikan perintahnya dan keluar dengan sukses. Status ini umum untuk workload seperti job dan init container.
FAQ
Pod berjalan tetapi tidak berfungsi
Kesalahan dalam file YAML aplikasi Anda dapat menyebabkan pod memasuki status Running tetapi gagal berfungsi dengan benar.
-
Verifikasi pengaturan kontainer dalam konfigurasi pod.
-
Gunakan metode berikut untuk memeriksa konfigurasi YAML Anda terhadap kesalahan ejaan.
Saat Anda membuat Pod, jika kunci dalam file YAML salah eja (misalnya, mengeja
commandsebagaicommnd), kluster mengabaikan error tersebut dan berhasil membuat resource. Namun, sistem tidak dapat mengeksekusi perintah yang ditentukan dalam file YAML saat kontainer berjalan.Contoh berikut, di mana
commandsalah eja sebagaicommnd, menjelaskan cara memecahkan masalah kesalahan ejaan.-
Tambahkan flag
--validateke perintahkubectl apply -f, lalu jalankan perintahkubectl apply --validate -f XXX.yaml.Jika Anda salah mengeja kata, error dilaporkan:
XXX] unknown field: commnd XXX] this may be a false alarm, see https://gXXXb.XXX/6842pods/test. -
Jalankan perintah berikut dan bandingkan file
pod.yamloutput dengan file YAML asli yang digunakan untuk membuat pod.Catatan[$Pod]adalah nama Pod tidak normal, yang dapat Anda peroleh dengan menjalankan perintahkubectl get pods.kubectl get pods [$Pod] -o yaml > pod.yaml-
Jika file
pod.yamlmemiliki lebih banyak baris daripada file aslinya, berarti pod dibuat seperti yang diharapkan, dan kluster menambahkan nilai default. -
Jika baris dari file YAML asli Anda hilang dari
pod.yaml, ini menunjukkan kesalahan ejaan dalam file asli Anda.
-
-
-
Periksa log pod untuk memecahkan masalah.
-
Akses kontainer melalui terminal dan verifikasi bahwa file lokal dalam kontainer sesuai harapan.
Memeriksa penggunaan sumber daya node dengan kubectl
-
Periksa penggunaan CPU dan memori semua node di kluster.
kubectl describe nodes | awk '/^Name:/{print "\n"$2} /Resource +Requests +Limits/{print $0} /^[ \t]+cpu.*%/{print $0} /^[ \t]+memory.*%/{print $0}'Output yang diharapkan:
cn-hangzhou.192.168.0.xxx Resource Requests Limits cpu 1725m (44%) 10320m (263%) memory 1750Mi (11%) 16044Mi (109%) cn-hangzhou.192.168.16.xxx Resource Requests Limits cpu 1885m (48%) 16820m (429%) memory 2536Mi (17%) 25760Mi (179%)Node dengan pemanfaatan request tinggi mungkin tidak dapat memenuhi
requestsPod baru, mencegah Pod dijadwalkan. -
Ganti
YOUR_NODE_NAMEdengan nama node aktual untuk melihat penggunaan sumber daya semua Pod di node tersebut.kubectl describe node YOUR_NODE_NAME | awk '/Pod yang belum dihentikan/,/Sumber daya yang dialokasikan/{ if ($0 !~ /Sumber daya yang dialokasikan/) print }'Output yang diharapkan:
Non-terminated Pods: (11 in total) Namespace Name CPU Requests CPU Limits Memory Requests Memory Limits Age --------- ---- ------------ ---------- --------------- ------------- --- arms-prom node-exporter-gp95p 20m (0%) 1020m (26%) 160Mi (1%) 1152Mi (7%) 6d21h csdr csdr-velero-77c8bbc9c7-w46lq 500m (12%) 1 (25%) 128Mi (0%) 2Gi (13%) 6d19h kube-system ack-cost-exporter-5b647ffc65-zdrsl 100m (2%) 1 (25%) 200Mi (1%) 1Gi (6%) 6d21h kube-system ack-node-local-dns-admission-controller-5dfd74f5f4-9rl6n 100m (2%) 1 (25%) 100Mi (0%) 1Gi (6%) 6d21h kube-system ack-node-problem-detector-daemonset-6wql2 200m (5%) 1200m (30%) 300Mi (2%) 1324Mi (9%) 6d21h kube-system coredns-7784559f6-dr9sn 100m (2%) 0 (0%) 100Mi (0%) 2Gi (13%) 6d21h kube-system csi-plugin-knz7j 130m (3%) 2 (51%) 176Mi (1%) 4Gi (27%) 6d21h kube-system kube-proxy-worker-rkbzv 100m (2%) 0 (0%) 100Mi (0%) 0 (0%) 6d21h kube-system loongcollector-ds-kw7cj 100m (2%) 2 (51%) 256Mi (1%) 2Gi (13%) 6d21h kube-system node-local-dns-pgzcn 25m (0%) 0 (0%) 30Mi (0%) 1Gi (6%) 6d21h kube-system terway-eniip-lnn8n 350m (8%) 1100m (28%) 200Mi (1%) 256Mi (1%) 6d21hAnda dapat menyesuaikan konfigurasi
requestsberdasarkan konsumsi sumber daya aktual.
Putus jaringan intermiten dari pod ke database
Jika pod di kluster ACK Anda terputus secara intermiten dari database, ikuti langkah-langkah berikut untuk memecahkan masalah.
1. Periksa pod
-
Periksa event pod untuk tanda-tanda ketidakstabilan koneksi, seperti masalah jaringan, restart, atau sumber daya tidak mencukupi.
-
Periksa log pod untuk pesan error apa pun yang terkait dengan koneksi database, seperti timeout, kegagalan autentikasi, atau pemicu koneksi ulang.
-
Monitor penggunaan CPU dan memori pod untuk memastikan kehabisan sumber daya tidak menyebabkan aplikasi atau driver database crash.
-
Tinjau
requestsdanlimitssumber daya pod untuk memastikan memiliki CPU dan memori yang cukup.
2. Periksa node
-
Periksa penggunaan sumber daya node untuk kekurangan memori, ruang disk, atau sumber daya lainnya. Untuk informasi lebih lanjut, lihat Memantau node.
-
Uji gangguan jaringan intermiten antara node dan database target.
3. Periksa database
-
Periksa status dan metrik kinerja database untuk restart atau bottleneck kinerja apa pun.
-
Tinjau jumlah koneksi tidak normal dan pengaturan timeout koneksi, lalu sesuaikan berdasarkan kebutuhan aplikasi Anda.
-
Periksa log database untuk catatan apa pun yang terkait dengan pemutusan koneksi.
4. Periksa status komponen kluster
Komponen kluster yang rusak dapat mengganggu komunikasi jaringan pod.
kubectl get pod -n kube-system # Periksa status pod komponen.Juga, periksa komponen jaringan berikut:
-
CoreDNS: Periksa status dan log komponen untuk memastikan pod dapat menyelesaikan alamat layanan database dengan benar.
-
Flannel: Periksa status dan log komponen kube-flannel.
-
Terway: Periksa status dan log komponen terway-eniip.
5. Analisis trafik jaringan
Anda dapat menggunakan tcpdump untuk mengambil paket dan menganalisis trafik jaringan guna membantu mengidentifikasi penyebab masalah.
-
Dapatkan informasi Pod dan node:
Jalankan perintah berikut untuk mendapatkan informasi tentang pod di namespace tertentu dan node tempatnya berjalan:
kubectl get pod -n [namespace] -o wide -
Login ke node target dan jalankan perintah berikut untuk menemukan PID kontainer.
Containerd
-
Jalankan perintah berikut untuk melihat
CONTAINERkontainer.crictl ps |grep <Pod name keyword>Output yang diharapkan:
CONTAINER IMAGE CREATED STATE a1a214d2***** 35d28df4***** 2 days ago Running -
Jalankan perintah berikut dengan parameter
CONTAINER IDuntuk melihat PID kontainer.crictl inspect a1a214d2***** |grep -i PIDOutput yang diharapkan:
"pid": 2309838, # PID kontainer target. "pid": 1 "type": "pid"
Docker
-
Jalankan perintah berikut untuk melihat
CONTAINER IDkontainer.docker ps |grep <pod name keyword>Output yang diharapkan:
CONTAINER ID IMAGE COMMAND a1a214d2***** 35d28df4***** "/nginx -
Jalankan perintah berikut dengan parameter
CONTAINER IDuntuk melihat PID kontainer.docker inspect a1a214d2***** |grep -i PIDOutput yang diharapkan:
"Pid": 2309838, # PID kontainer target. "PidMode": "", "PidsLimit": null,
-
-
Jalankan perintah pengambilan paket.
Gunakan PID kontainer untuk menjalankan perintah berikut dan mengambil paket jaringan antara pod dan database target.
nsenter -t <container PID> tcpdump -i any -n -s 0 tcp and host <database IP address>Gunakan PID kontainer untuk menjalankan perintah berikut dan mengambil paket jaringan antara pod dan host.
nsenter -t <container PID> tcpdump -i any -n -s 0 tcp and host <node IP address>Jalankan perintah berikut untuk mengambil paket jaringan antara host dan database.
tcpdump -i any -n -s 0 tcp and host <database IP address>
6. Optimalkan aplikasi
-
Implementasikan mekanisme koneksi ulang otomatis di aplikasi Anda untuk memastikan dapat memulihkan koneksi secara otomatis selama alih bencana atau migrasi database.
-
Gunakan koneksi persisten alih-alih koneksi singkat untuk berkomunikasi dengan database. Koneksi persisten dapat secara signifikan mengurangi overhead kinerja dan konsumsi sumber daya, meningkatkan efisiensi sistem secara keseluruhan.
Pemecahan masalah konsol
Login ke Konsol ACK dan buka halaman detail kluster Anda untuk memecahkan masalah Pod.
|
Tindakan |
Konsol |
|
Periksa status Pod |
|
|
Periksa informasi dasar Pod |
|
|
Periksa konfigurasi Pod |
|
|
Periksa event Pod |
|
|
Lihat log Pod |
Catatan
Kluster ACK terintegrasi dengan Simple Log Service (SLS). Anda dapat mengaktifkan SLS di kluster Anda untuk mengumpulkan log kontainer dengan cepat. Untuk informasi lebih lanjut, lihat Mengumpulkan log kontainer dari kluster ACK. |
|
Periksa data pemantauan Pod |
Catatan
Kluster ACK terintegrasi dengan Managed Service for Prometheus. Anda dapat dengan cepat mengaktifkan Managed Service for Prometheus untuk kluster Anda guna memantau kesehatan kluster dan kontainer secara real-time serta melihat dasbor Grafana. Untuk informasi lebih lanjut, lihat Menghubungkan dan mengonfigurasi Managed Service for Prometheus. |
|
Gunakan terminal untuk mengakses kontainer dan melihat file lokal |
|
|
Jalankan diagnostik Pod |
Catatan
Container Intelligent Service menyediakan fitur diagnostik satu klik untuk membantu Anda mengidentifikasi masalah di kluster Anda. Untuk informasi lebih lanjut, lihat Menggunakan diagnostik kluster. |
Penghapusan Pod tidak terduga
Saat kluster berisi banyak Pod dengan status Completed, kube-controller-manager (KCM) melakukan pengumpulan sampah untuk mencegah degradasi kinerja pengontrolnya. Pembersihan ini terjadi ketika jumlah Pod selesai melebihi ambang batas default 12.500. Parameter --terminated-pod-gc-threshold mengonfigurasi ambang batas ini. Untuk informasi lebih lanjut, lihat dokumentasi parameter KCM komunitas.
Rekomendasi: Bersihkan secara berkala Pod dengan status Completed di kluster Anda untuk mencegahnya memengaruhi efisiensi pengontrol.