Kluster ACK Edge memungkinkan pengelolaan terpusat sumber daya komputasi yang tersebar di berbagai wilayah. Solusi ini mendukung manajemen siklus penuh dan penjadwalan efisien untuk aplikasi cloud-native. Topik ini menjelaskan cara menggunakan kluster ACK Edge untuk mengelola secara terpusat sumber daya ECS di beberapa wilayah.
Skenario
Berikut adalah skenario di mana Anda dapat menggunakan kluster ACK Edge untuk mengelola secara terpusat sumber daya ECS di beberapa wilayah:
Instance ECS tersebar di beberapa virtual private cloud (VPC).
Instance ECS tersebar di beberapa wilayah.
Instance ECS dibuat oleh beberapa pengguna Resource Access Management (RAM).
Kelola aplikasi yang tersebar di beberapa wilayah
Untuk mengelola secara terpusat atau menerapkan bisnis yang sama pada sejumlah besar instance ECS yang tersebar di beberapa wilayah, Anda dapat membuat kluster ACK Edge dan menambahkan instance ECS ke dalamnya. Untuk detail lebih lanjut, lihat Contoh 1: Gunakan kluster ACK Edge untuk mengelola aplikasi yang tersebar di beberapa wilayah.
Perlindungan keamanan
Dalam lingkungan komputasi terdistribusi, penting untuk melindungi bisnis dari serangan jahat dan kebocoran data. Salah satu solusi umum adalah menerapkan agen keamanan jaringan pada sumber daya terdistribusi. Dalam hal ini, Anda dapat menggunakan kluster ACK Edge untuk menerapkan dan memelihara agen secara terpusat.
Pengujian stres terdistribusi dan pemantauan sintetis
Saat melakukan uji stres pada bisnis berskala besar, Anda perlu menggunakan alat uji stres untuk memulai tugas di beberapa wilayah secara bersamaan. Anda dapat menambahkan sumber daya komputasi terdistribusi ke kluster ACK Edge dan menerapkan alat uji stres secara terpusat.
Akselerasi cache
Untuk sistem akselerasi cache terdistribusi, Anda perlu menerapkan layanan cache di setiap wilayah guna mempercepat pengiriman konten melalui jaringan. Dalam hal ini, Anda dapat menggunakan kluster ACK Edge untuk menerapkan dan memelihara sistem akselerasi cache terdistribusi secara terpusat.
Atasi masalah kekurangan sumber daya GPU di suatu wilayah
Jika sumber daya GPU tidak mencukupi di suatu wilayah, Anda dapat membeli instance ECS yang dipercepat GPU di wilayah lain dan menambahkannya ke kluster ACK Edge. Kluster ini akan menjadwalkan tugas ke instance yang dipercepat GPU tersebut. Untuk informasi lebih lanjut, lihat Contoh 2: Beli instance ECS baru yang dipercepat GPU di wilayah lain untuk meningkatkan sumber daya GPU ketika sumber daya GPU tidak mencukupi di suatu wilayah.
Manfaat
Efisiensi biaya: Solusi ini menyediakan integrasi standar dengan teknologi cloud-native untuk mengoptimalkan O&M aplikasi terdistribusi dan mengurangi biaya operasional.
Nol O&M: Bidang kontrol kluster ACK Edge dikelola sepenuhnya oleh Alibaba Cloud tanpa memerlukan O&M manual. Selain itu, Alibaba Cloud menyediakan jaminan Service Level Agreement (SLA) untuk bidang kontrol.
Tingkat ketersediaan tinggi: Solusi ini terintegrasi dengan layanan Alibaba Cloud lainnya untuk menyediakan kemampuan seperti elastisitas, jaringan, penyimpanan, dan observabilitas. Ini memastikan stabilitas aplikasi serta mendukung otonomi edge, saluran O&M cloud-edge, dan manajemen berbasis sel.
Kompatibilitas tinggi: Solusi ini mendukung integrasi puluhan jenis sumber daya komputasi heterogen dengan sistem operasi berbeda.
Kinerja tinggi: Solusi ini mengoptimalkan komunikasi cloud-edge dan mengurangi biaya komunikasi. Setiap kluster ACK Edge dapat menampung ribuan node.
Contoh
Contoh 1: Gunakan kluster ACK Edge untuk mengelola aplikasi yang tersebar di beberapa wilayah
Persiapan lingkungan
Pilih wilayah sebagai pusat dan buat kluster ACK Edge di wilayah tersebut. Untuk detail lebih lanjut, lihat Buat kluster ACK Edge.
Instal OpenKruise. Untuk informasi lebih lanjut, lihat Manajemen komponen.
Buat pool node edge di setiap wilayah tempat instance ECS berada dan tambahkan instance ECS ke pool tersebut. Untuk detail lebih lanjut, lihat Buat pool node edge.
Prosedur
Anda dapat menggunakan Kubernetes DaemonSet atau OpenKruise DaemonSet untuk menerapkan dan mengelola bisnis Anda.
Gunakan Kubernetes DaemonSet
Contoh
Masuk ke Konsol ACK. Di panel navigasi kiri, klik Clusters.
Di halaman Clusters, temukan kluster yang diinginkan dan klik namanya. Di panel kiri, pilih .
Di halaman DaemonSets, pilih namespace dan metode penyebaran, masukkan nama aplikasi, atur Type ke DaemonSet, lalu ikuti petunjuk di layar untuk menyelesaikan pembuatan.
Untuk informasi lebih lanjut tentang cara membuat DaemonSet, lihat Buat DaemonSet.
Peningkatan bisnis
Di halaman DaemonSets, temukan DaemonSet yang dibuat dan klik Edit di kolom Actions. Di halaman Edit, modifikasi template DaemonSet untuk melakukan peningkatan versi atau pembaruan konfigurasi.
Gunakan OpenKruise DaemonSet
Contoh
Masuk ke Konsol ACK. Di panel navigasi kiri, klik Clusters.
Di halaman Clusters, temukan kluster yang diinginkan dan klik namanya. Di panel kiri, pilih .
Di halaman Pods, klik Create from YAML, pilih Custom dari daftar drop-down Sample Template, salin template YAML DaemonSet ke editor kode, dan klik Create.
Peningkatan bisnis
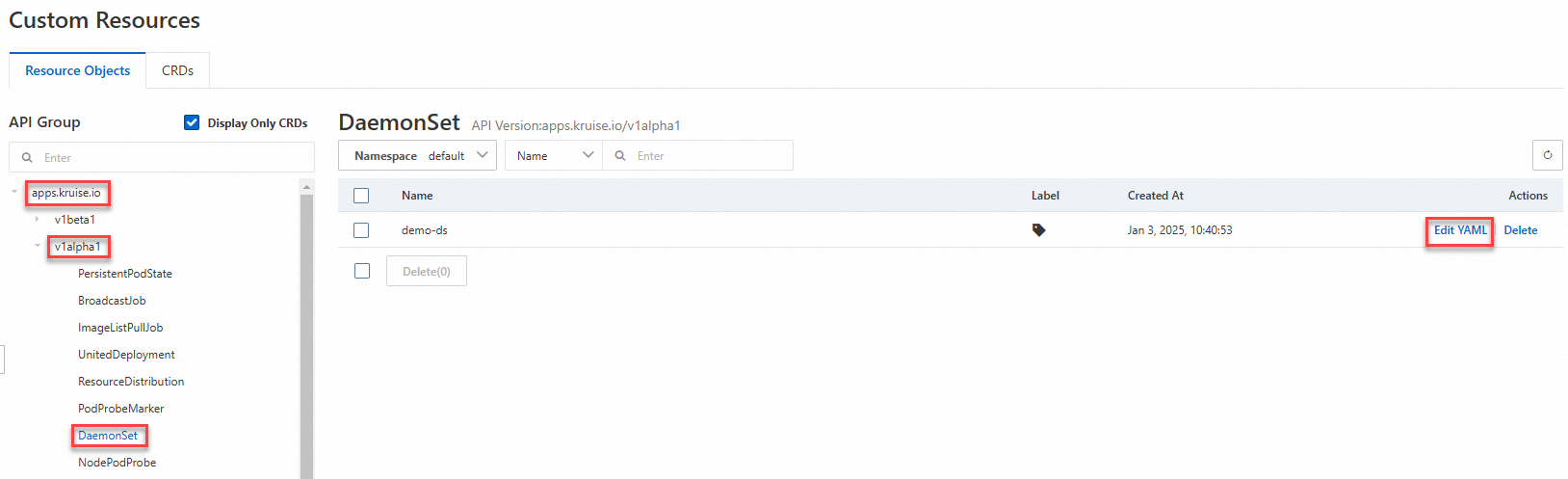
Di halaman Clusters, klik nama kluster yang ingin dikelola dan pilih di panel navigasi kiri.
Di halaman Custom Resources, klik Resource Objects, temukan DaemonSet yang dibuat, dan klik Edit YAML di kolom Actions. Modifikasi template DaemonSet untuk melakukan peningkatan versi atau pembaruan konfigurasi.
Contoh 2: Beli instance ECS baru yang dipercepat GPU di wilayah lain untuk meningkatkan sumber daya GPU ketika sumber daya GPU tidak mencukupi di suatu wilayah
Persiapan lingkungan
Prosedur
Dalam contoh ini, layanan inferensi diterapkan di kluster ACK Edge yang berisi instance ECS tersebar di beberapa wilayah. Saat sumber daya GPU di satu wilayah tidak mencukupi, Anda dapat menambahkan instance yang dipercepat GPU di wilayah lain ke dalam kluster. Kemudian, Anda dapat menjadwalkan layanan inferensi ke instance yang baru ditambahkan.
Terapkan layanan inferensi dan periksa statusnya.
Buat file bernama tensorflow-mnist.yaml.
Terapkan layanan inferensi.
kubectl apply -f tensorflow-mnist.yamlPeriksa status layanan inferensi.
kubectl get podsOutput yang diharapkan:
NAME READY STATUS RESTARTS AGE tensorflow-mnist-664cf976d8-whrbc 0/1 pending 0 30sOutput menunjukkan bahwa layanan inferensi dalam keadaan
pending, yang menandakan bahwa sumber daya GPU tidak mencukupi.
Buat pool node edge. Untuk informasi lebih lanjut, lihat Buat pool node edge.
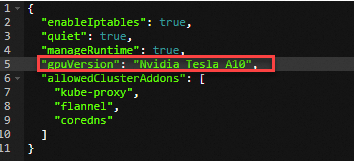
Tambahkan instance yang dipercepat GPU ke pool node edge sebagai node edge. Untuk informasi lebih lanjut, lihat Tambahkan node yang dipercepat GPU.
Lihat status node edge.
kubectl get nodesOutput yang diharapkan:
NAME STATUS ROLES AGE VERSION cn-hangzhou.192.168.XX.XX Ready <none> 9d v1.30.7-aliyun.1 iz2ze21g5pq9jbesubr**** Ready <none> 8d v1.30.7-aliyun.1 izf8z0dko1ivt5kwgl4**** Ready <none> 8d v1.30.7-aliyun.1 izuf65ze9db2kfcethw**** Ready <none> 8d v1.30.7-aliyun.1 # Informasi tentang node edge yang dipercepat GPU yang baru ditambahkan.Periksa status layanan inferensi.
kubectl get pods -owideOutput yang diharapkan:
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES tensorflow-mnist-664cf976d8-whrbc 1/1 running 0 23m 10.12.XX.XX izuf65ze9db2kfcethw**** <none> <none>Output menunjukkan bahwa layanan inferensi dijadwalkan ke salah satu node edge yang dipercepat GPU yang baru ditambahkan dan berhasil diterapkan.