Ketika menggunakan model bahasa besar (LLM) untuk menyebarkan layanan inferensi elastis dalam lingkungan komputasi awan hibrid, distribusi lalu lintas yang tidak seimbang dapat menyebabkan masalah alokasi GPU di pusat data. Untuk mengatasi hal ini, kluster ACK Edge menawarkan solusi untuk menyebarkan LLM sebagai layanan inferensi elastis dalam lingkungan komputasi awan hibrid. Solusi ini membantu Anda mengelola sumber daya GPU di awan dan pusat data secara terpusat. Anda dapat mengonfigurasi bisnis agar lebih memprioritaskan penggunaan sumber daya di pusat data selama jam non-puncak dan meluncurkan sumber daya di awan selama jam puncak. Dengan demikian, biaya operasional layanan inferensi berbasis LLM dapat diminimalkan, serta pasokan sumber daya disesuaikan secara dinamis dan fleksibel, memastikan stabilitas layanan dan mencegah idle resources.
Ikhtisar Solusi
Arsitektur
Solusi ini dibangun berdasarkan kemampuan kolaborasi awan-tepi dari kluster ACK Edge. Anda dapat mengelola sumber daya komputasi di awan dan pusat data secara terpusat serta mengalokasikan sumber daya secara dinamis ke tugas komputasi. Setelah menyebarkan LLM sebagai layanan inferensi di kluster Anda, Anda dapat menggunakan KServe untuk mengonfigurasi kebijakan penskalaan layanan inferensi.
Selama jam non-puncak, buat ResourcePolicy di kluster Anda untuk mengaktifkan penjadwalan sumber daya berbasis prioritas bagi layanan inferensi. Berikan prioritas lebih tinggi pada sumber daya komputasi di pusat data dibandingkan dengan sumber daya di awan, sehingga layanan inferensi lebih memilih menggunakan sumber daya lokal.
Selama jam puncak, KServe memanfaatkan kemampuan pemantauan kluster ACK Edge untuk memantau pemanfaatan GPU dan status beban kerja secara real-time. Ketika kondisi penskalaan terpenuhi, KServe secara dinamis menambah jumlah pod tempat layanan inferensi diterapkan. Jika sumber daya GPU lokal tidak mencukupi, sistem mengalokasikan sumber daya GPU dari kelompok node elastis yang telah dikonfigurasi di awan kepada layanan inferensi, memastikan stabilitas dan kontinuitas layanan.
Permintaan Inferensi: Sejumlah besar permintaan inferensi.
Penjadwalan Sumber Daya: Sistem lebih memilih menjadwalkan layanan inferensi ke kolam sumber daya di pusat data.
Penskalaan Keluar dengan Sumber Daya Awan: Ketika sumber daya di pusat data tidak mencukupi, sistem mengalokasikan sumber daya dari kelompok node elastis yang telah dikonfigurasi di awan kepada layanan inferensi.
Komponen Utama
Solusi ini mencakup komponen utama berikut: kluster ACK Edge, KServe, kelompok node elastis (penyesuaian otomatis node), dan ResourcePolicy (penjadwalan sumber daya berbasis prioritas).
Contoh
Siapkan Lingkungan.
Setelah menyelesaikan langkah-langkah di atas, klasifikasikan sumber daya dalam kluster menjadi tiga jenis dan tambahkan sumber daya ke kolam node berikut.
Jenis
Jenis kolam node
Deskripsi
Contoh
Kolam sumber daya kontrol di awan
Di awan
Kolam node di awan yang digunakan untuk menyebarkan kluster ACK Edge dan komponen kontrol seperti KServe.
default-nodepool
Kolam sumber daya lokal
Tepi/dedicated
Sumber daya komputasi di pusat data yang digunakan untuk menampung layanan inferensi yang diterapkan menggunakan LLM.
GPU-V100-Edge
Kolam sumber daya elastis di awan
Di awan
Kolam sumber daya yang dapat diskalakan dapat menyesuaikan secara dinamis untuk memenuhi persyaratan sumber daya GPU kluster dan menampung layanan inferensi yang diterapkan menggunakan LLM selama jam puncak.
GPU-V100-Elastic
Siapkan Model AI.
Gunakan Object Storage Service (OSS) atau File Storage NAS (NAS) untuk menyiapkan data model. Untuk informasi lebih lanjut, lihat Siapkan Data Model dan Unggah Data Model ke Bucket OSS.
Tentukan Prioritas Sumber Daya.
Buat ResourcePolicy untuk menentukan prioritas sumber daya. Dalam contoh ini, parameter labelSelector ResourcePolicy diatur ke
app: isvc.qwen-predictoruntuk memilih aplikasi yang akan diterapkan ResourcePolicy. ResourcePolicy berikut menentukan bahwa pod yang cocok dijadwalkan ke kolam sumber daya lokal terlebih dahulu. Ketika sumber daya lokal tidak mencukupi, sistem menjadwalkan pod yang cocok ke kolam sumber daya elastis di awan. Untuk informasi lebih lanjut tentang cara mengonfigurasi ResourcePolicy, lihat Konfigurasikan Penjadwalan Sumber Daya Berbasis Prioritas.PentingSaat membuat pod aplikasi selanjutnya, tambahkan label yang sesuai dengan
labelSelectorberikut untuk mengaitkannya dengan kebijakan penjadwalan yang didefinisikan di sini.apiVersion: scheduling.alibabacloud.com/v1alpha1 kind: ResourcePolicy metadata: name: qwen-chat namespace: default spec: selector: app: isvc.qwen-predictor # Anda harus menentukan label pod yang ingin Anda terapkan ResourcePolicy. strategy: prefer units: - resource: ecs nodeSelector: alibabacloud.com/nodepool-id: npxxxxxx # Ganti nilai dengan ID kolam sumber daya lokal. - resource: elastic nodeSelector: alibabacloud.com/nodepool-id: npxxxxxy # Ganti nilai dengan ID kolam sumber daya di awan.Sebarkan LLM sebagai Layanan Inferensi.
Jalankan perintah berikut pada klien Arena untuk menggunakan KServe menyebarkan layanan inferensi berbasis LLM.
arena serve kserve \ --name=qwen-chat \ --image=kube-ai-registry.cn-shanghai.cr.aliyuncs.com/kube-ai/vllm:0.4.1 \ --scale-metric=DCGM_CUSTOM_PROCESS_SM_UTIL \ --scale-target=50 \ --min-replicas=1 \ --max-replicas=3 \ --gpus=1 \ --cpu=4 \ --memory=12Gi \ --data="llm-model:/mnt/models/Qwen" \ "python3 -m vllm.entrypoints.openai.api_server --port 8080 --trust-remote-code --served-model-name qwen --model /mnt/models/Qwen --gpu-memory-utilization 0.95 --quantization gptq --max-model-len=6144"Parameter
Diperlukan
Deskripsi
Contoh
--nameYa
Nama layanan inferensi, yang bersifat unik secara global.
qwen-chat
--imageYa
Alamat gambar layanan inferensi. Dalam contoh ini, kerangka kerja inferensi virtual large language model (vLLM) digunakan.
kube-ai-registry.cn-shanghai.cr.aliyuncs.com/kube-ai/vllm:0.4.1
--scale-metricTidak
Metrik penskalaan. Dalam contoh ini, metrik pemanfaatan GPU
DCGM_CUSTOM_PROCESS_SM_UTILdigunakan sebagai metrik penskalaan. Untuk informasi lebih lanjut, lihat Konfigurasikan HPA.DCGM_CUSTOM_PROCESS_SM_UTIL
--scale-targetTidak
Ambang penskalaan. Dalam contoh ini, ambang penskalaan adalah 50%. Ketika pemanfaatan GPU melebihi 50%, sistem menambah replika pod.
50
--min-replicasTidak
Jumlah minimum replika pod.
1
--max-replicasTidak
Jumlah maksimum replika pod.
3
--gpusTidak
Jumlah GPU yang diminta oleh layanan inferensi. Nilai default: 0.
1
--cpuTidak
Jumlah vCore yang diminta oleh layanan inferensi.
4
--memoryTidak
Ukuran memori yang diminta oleh layanan inferensi.
12Gi
--dataTidak
Alamat model layanan inferensi. Dalam contoh ini, volume model adalah llm-model, yang dipasang ke direktori /mnt/models/ container.
"llm-model:/mnt/models/Qwen" \
"python3 -m vllm.entrypoints.openai.api_server --port 8080 --trust-remote-code --served-model-name qwen --model /mnt/models/Qwen --gpu-memory-utilization 0.95 --quantization gptq --max-model-len=6144"
Periksa Apakah Layanan Inferensi Elastis Diterapkan.
curl -H "Host: qwen-chat-default.example.com" \ # Dapatkan alamat dari detail Ingress yang dibuat otomatis oleh KServe. -H "Content-Type: application/json" \ http://xx.xx.xx.xx:80/v1/chat/completions \ -X POST \ -d '{"model": "qwen", "messages": [{"role": "user", "content": "Hello"}], "max_tokens": 512, "temperature": 0.7, "top_p": 0.9, "seed": 10, "stop":["<|endoftext|>", "<|im_end|>", "<|im_start|>"]}Gunakan alat uji stres hey untuk mengirim sejumlah besar permintaan ke layanan inferensi, mensimulasikan lonjakan lalu lintas selama jam puncak dan menguji peluncuran sumber daya di awan.
hey -z 2m -c 5 \ -m POST -host qwen-chat-default.example.com \ -H "Content-Type: application/json" \ -d '{"model": "qwen", "messages": [{"role": "user", "content": "Test"}], "max_tokens": 10, "temperature": 0.7, "top_p": 0.9, "seed": 10}' \ http://xx.xx.xx.xx:80/v1/chat/completionsSetelah permintaan dikirim ke pod, pemanfaatan GPU layanan inferensi melebihi ambang penskalaan (50%). Dalam hal ini, HPA menambah pod berdasarkan aturan penskalaan yang telah ditentukan sebelumnya. Gambar berikut menunjukkan bahwa jumlah pod untuk layanan inferensi meningkat menjadi tiga.

Namun, pusat data dalam lingkungan pengujian hanya menyediakan satu GPU. Akibatnya, dua pod baru yang dibuat tidak dapat dijadwalkan dan tetap dalam status
pending. Dalam hal ini, cluster-autoscaler secara otomatis meluncurkan dua node GPU di awan untuk menampung dua podpending.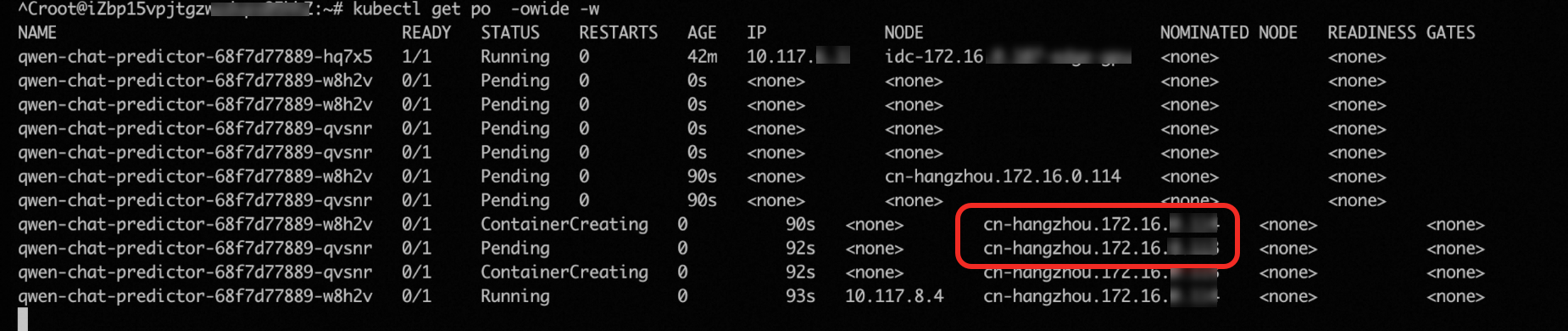
Referensi
Untuk informasi lebih lanjut tentang cara menyebarkan layanan inferensi, lihat Sebarkan Layanan Inferensi AI di Kubernetes.
Untuk informasi lebih lanjut tentang kemampuan elastisitas di awan kluster ACK Edge, lihat Elastisitas Awan.
Untuk informasi lebih lanjut tentang cara mempercepat akses ke Bucket OSS dari node tepi, lihat Gunakan Fluid untuk Mempercepat Akses ke Bucket OSS dari Node Tepi.