Tablestore is commonly used in three distinct architectures: the Internet application architecture, the data lake architecture, and the Internet of Things (IoT) architecture. The Internet application architecture can be further categorized into the tiered database architecture and the distributed architecture for structured data. This topic describes the application scenarios of Tablestore in these architectures.
Internet application architecture
In today's world, the Internet is an integral part of our lives. We shop, socialize, and entertain ourselves on the Internet. This is made possible by a variety of Internet applications which are in turn powered by services including order histories, instant messaging (IM), and feed streams. These services can be easily built with Tablestore through the Internet application architecture.
Order history
The order system is a very common system that is used in various industries nowadays. For example, it is used by e-commerce platforms to store orders, by banks to store transaction records, and by telecom operators to store bills. As data becomes more and more important, more and more data about orders need to be stored permanently. Relational databases are suitable for online workloads that are characterized by transactions requiring strong data consistency. However, when the volumes of orders grow, these databases become inefficient and storing the relationships between orders and their data becomes challenging. This can be solved through a tiered storage architecture.
Order history applications have the following key requirements:
Online data synchronization: Real-time data and historical data must be stored in different tiers, and online synchronization of real-time data must be supported.
Storage of historical data: Large volumes of historical data needs to be stored in a cost-efficient manner. The storage solution also needs to support low-latency queries on this data.
Data analysis: Historical data is often used for statistical analysis. The storage solution should also provide or be compatible with computing capabilities.
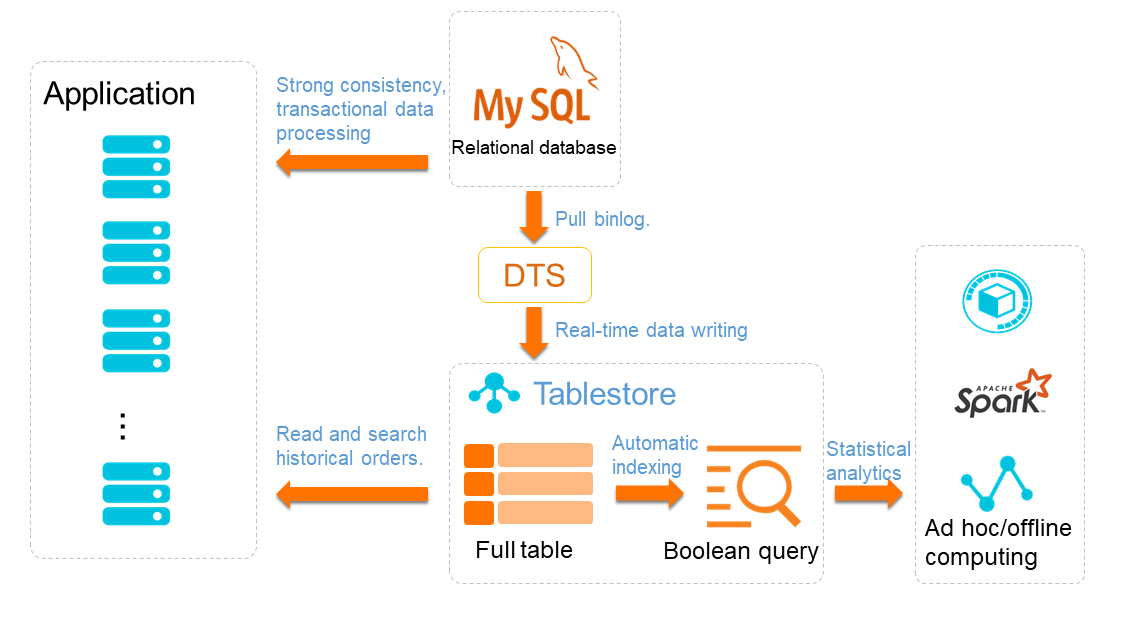
The tiered database architecture of Tablestore can be used to store order data, as shown in the following figure.
As a supplement to relational databases, Tablestore is used as persistent storage for order data. This data can be synchronized to Tablestore in real time through DTS. Tablestore also supports Boolean queries, and can be used together with stream and batch computing engines to perform statistical analysis.
IM
IM has become a fundamental component for all Internet businesses, and is widely used in applications such as socialization, gaming, and live streaming. IM is characterized by large, rapid growing data volumes and real-time data storage. These characteristics require the storage system to support the storage, synchronization, and retrieval of large amounts of data.
IM applications have the following key requirements:
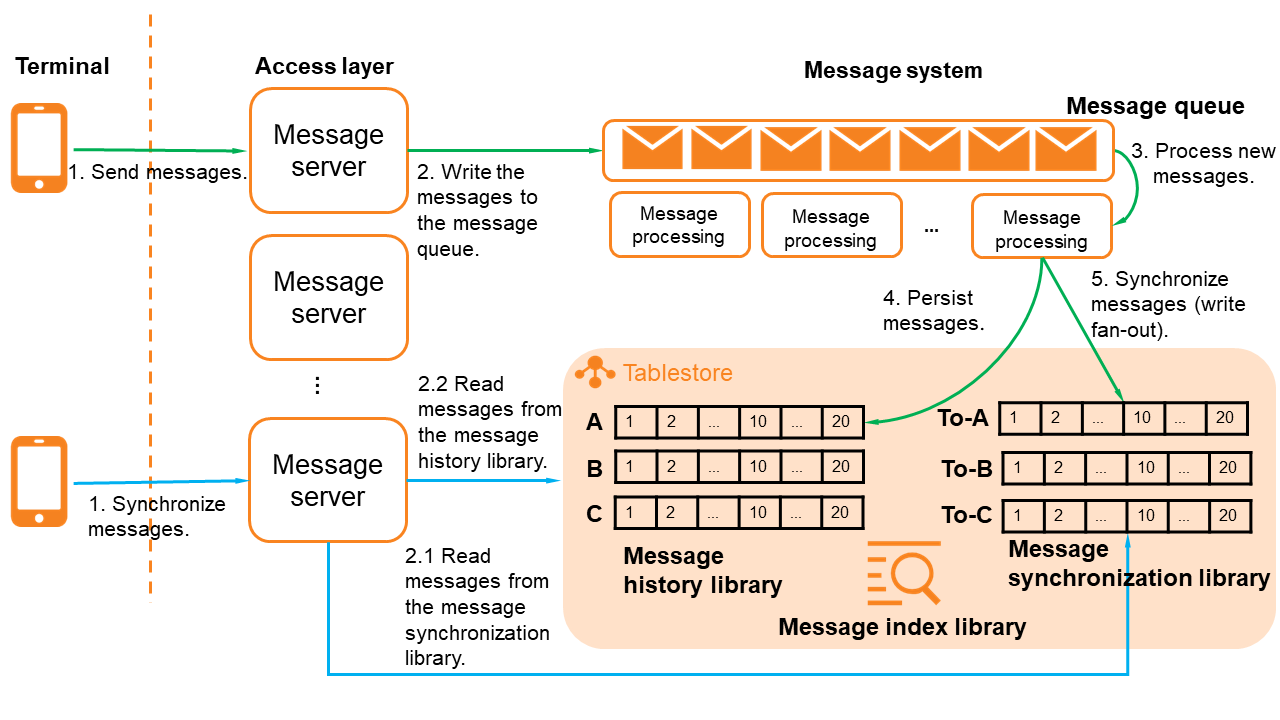
Message history library: stores conversation history. Due to the velocity of data growth, the storage solution should be able to scale quickly and easily.
Message synchronization library: stores synchronized messages by receiver. The storage system needs to support high-concurrency writes and real-time pulling (write fan-out).
Message indexing: facilitates data retrieval and requires support for data update and synchronization.
The distributed storage architecture for structured data of Tablestore can be used to store messages for IM applications, as shown in the following figure.
Tablestore provides a lightweight message model, the Timeline model, for IM applications and feed streams. Tablestore is able to store message synchronization tables that are hundreds of TBs in size and data tables that are PBs in size. Tablestore also supports the fan-out of millions of messages per second and synchronous database pulling with millisecond-grade performance.
Feed streams
Feed streams have become the standard method of content delivery in social media applications such as WeChat Moments, Weibo, and TopBuzz. The typical read/write ratio of feed streams is 100:1, and the push mode is often used. Therefore, the storage system is required to support high-concurrency message writes based on auto-increment primary key columns.
Feed stream applications have the following key requirements:
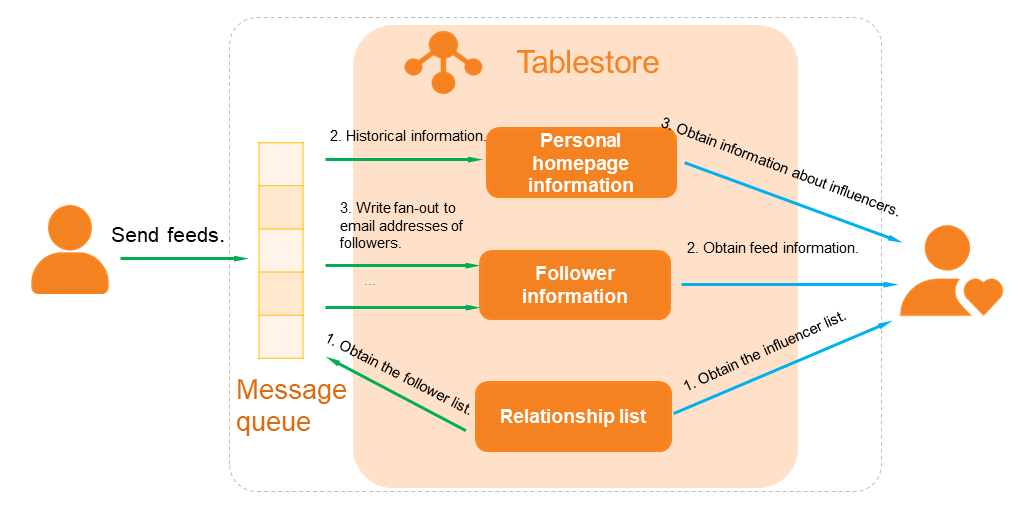
Storage of publishers' homepage information: Historical messages must be stored and sorted based on the publisher, and the storage system must support the storage and query of massive amounts of data.
Storage of followers' information: Messages must also be stored based on the follower. The storage system must support high-concurrency writes and real-time pulling (write fan-out).
Storage of relation lists: Publisher-follower relations must be stored because they are used every time a user views or publishes contents. Rapid update and query of relations must also be supported.
The distributed architecture for structured data of Tablestore can be used to store data in feed streams, as shown in the following figure.
Tablestore provides a lightweight message model, the Timeline model, for IM applications and feed streams. Tablestore is able to store message synchronization tables that are hundreds of TBs in size and data tables that are PBs in size. Tablestore also supports the fan-out of millions of messages per second and synchronous database pulling with millisecond-grade performance.
Big data
Big data applications aggregate and analyze large volumes of heterogeneous data that are generated at a tremendous velocity. Storing and mining the ever-growing volume of data for value in a cost-efficient manner has become the key focus of every big data application. The data lake architecture of Tablestore can solve these problems. Typical application scenarios of Tablestore in big data include recommendation, public opinion analysis, and risk control.
Recommendation system
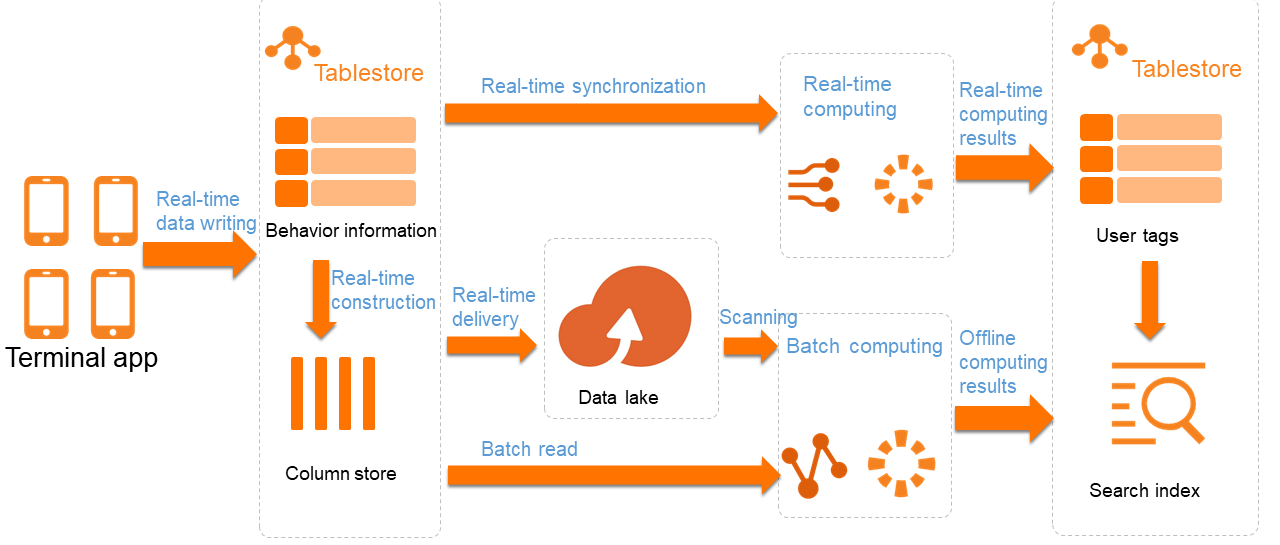
Recommendation systems help customers refine their business in scenarios such as e-commerce, short video streaming, and media. Recommendation systems handle large amounts of data generated in real time to deliver personalized recommendations, and therefore require storage solutions that support the storage of large amounts of message data and real-time as well as offline processing capabilities.
Recommendation systems have the following key requirements:
Storage of behavior logs: Data written by clients must be stored in real time. The storage system must support high-concurrency writes and real-time analysis by working with stream computing systems.
Storage of historical data: Cold data is synchronized to the data lake in Object Storage Service (OSS). This requires data to be delivered to OSS for tiered storage.
Storage of user tags: Analytical tags and recommendation information must be stored. Therefore, attribute column scale-out and efficient retrieval must be supported.
The data lake architecture of Tablestore can be used to store data for recommendation systems, as shown in the following figure.
Public opinion analysis and risk control (data crawling)
By analyzing data about public opinions, for example, comments, news pieces, and surveys, customers can effectively gain insight into the market. However, this requires the storage system to support highly concurrent writes of diverse data and rapid data transfer for efficient computing and analysis.
The public opinion analysis and risk control scenario has the following key requirements:
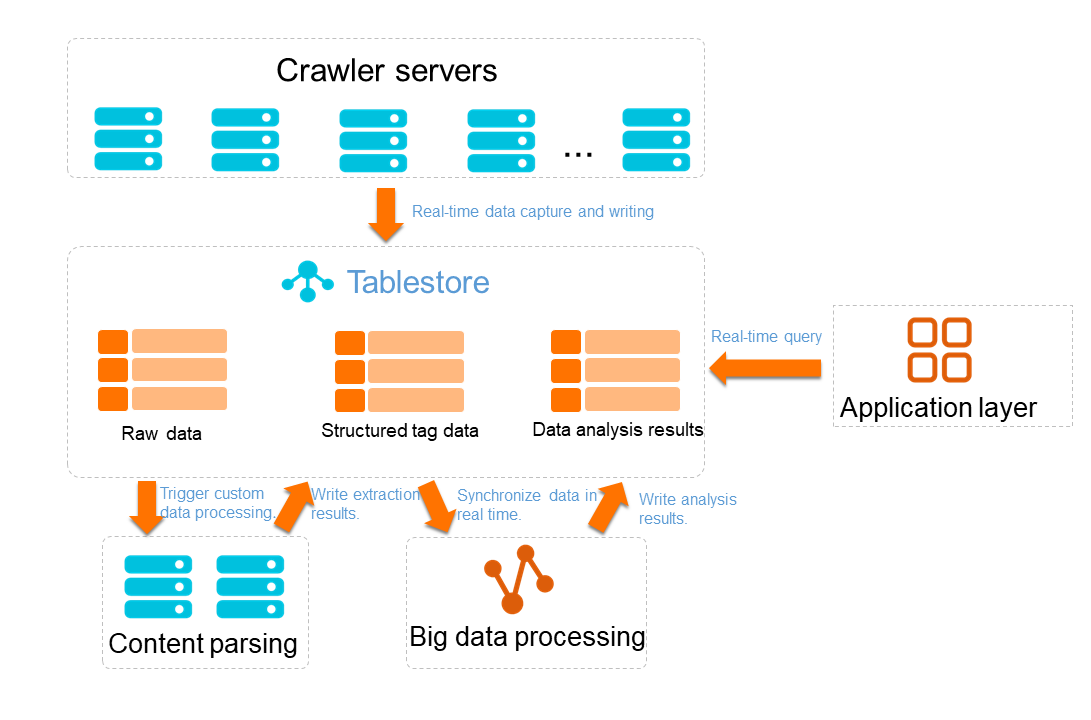
Storage of raw data: Data is written by a large number of data crawlers. Therefore, high-concurrency data writing and PB-level capacity must be supported.
Storage of various types of data: A wide variety of data is crawled and tags generated. This requires schema-free writing.
Data analysis: Data is pre-processed to generate and store structuring tags. This requires the storage system to support real-time computing and offline computing systems.
The data lake architecture of Tablestore can be used to store data in this scenario, as shown in the following figure.
IoT
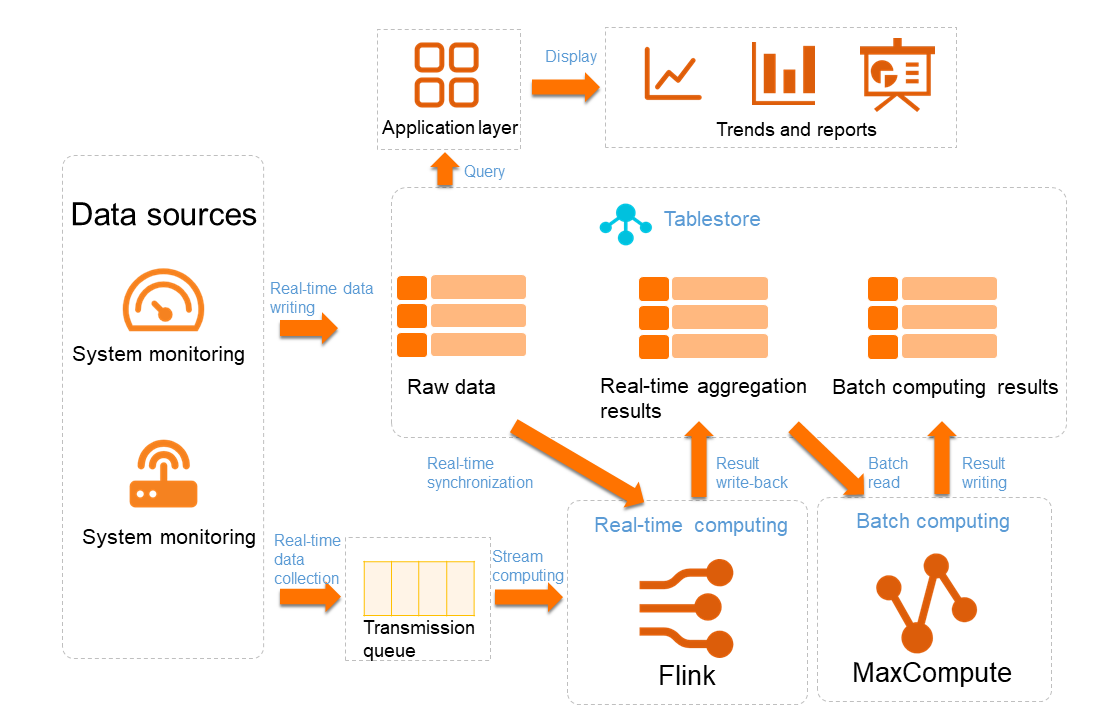
Keeping track of the environment and personnel in system O&M and IoT scenarios is conducive to helping businesses understand information and make informed decisions. This requires storage solutions that support highly concurrent writes from large numbers of different devices and efficient data analysis.
System O&M and IoT applications have the following key requirements:
High-concurrency data writes: The storage system must support real-time data writes from millions of sources, which include a variety of devices and systems.
Real-time data aggregation: Raw data is pre-aggregated and pre-processed. Data needs to be synchronized to stream computing systems in real time.
Data storage: Data is required to be stored for extended periods of time, which requires a storage solution that supports large-scale tables in a cost-efficient manner.
The IoT architecture of Tablestore can be used for system O&M and IoT scenarios, as shown in the following figure.