This topic describes some basic information about Realtime Compute for Apache Flink.
What is Realtime Compute for Apache Flink?
The business value of data is at its highest at the time the data is generated. Hence, being able to process data as soon as it is generated is a valuable trait for enterprises. Realtime Compute for Apache Flink is developed to meet the strict requirements on timeliness and speed in scenarios such as these. As the demands for high data timeliness and operability increase, software systems must be able to process more data in shorter periods of time. In traditional big data processing applications, online transaction processing (OLTP) and offline data analysis are performed at different times based on a schedule. Combined with the large amounts of data that need to be processed, this method often results in computing cycles that last for hours or days. It is evident that this method is no longer suitable for businesses of today, where streaming data needs to be processed in real time. Delays in data processing may affect the accuracy and performance of time-sensitive workloads, such as real-time big data analytics, risk control and alerting, real-time prediction, and financial transactions.
- Real-time and unbounded data streams
Today's data is generated continuously and needs to be consumed in chronological order to gain actionable insights. For example, when a visitor visits a website, logs are generated. These logs are continuously streamed to Realtime Compute for Apache Flink, and stop only when the visitor closes the website. Realtime Compute for Apache Flink ingests and processes the log data in real time to deliver insights.
- Continuous and efficient computing
Realtime Compute for Apache Flink is an event-driven system in which unbounded event or data streams continuously trigger real-time computations. Every time new data is ingested, it triggers a new task. Coupled with continuous data streams, this forms a continuous computing pipeline.
- Real-time integration of streaming data
Processed data is written to the data store of your choice in real time. For example, Realtime Compute for Apache Flink can directly write the results to an ApsaraDB RDS instance and used to generate and visualize reports. This capability also makes Realtime Compute for Apache Flink a viable data source for downstream processes and data stores.
What is streaming data?
- Log files generated by mobile and web applications
- Online shopping data
- In-game player activities
- Data from social networking sites
- Telemetry data from connected devices in trading floors or geospatial data centers
- Geospatial service information
- Telemetry data from devices and instruments
What are the differences between real-time computing and batch processing?
- Batch processing Batch processing deployments are initiated by users or systems on-demand or at scheduled intervals. This results in a significant delay between data collection and when results are produced. Most traditional data computing and analysis services are developed based on the batch processing model. Extract, transform, and load (ETL) systems or OLTP systems are used to load data into data stores and the data is subsequently queried by downstream services. The following figure shows the traditional batch processing model.
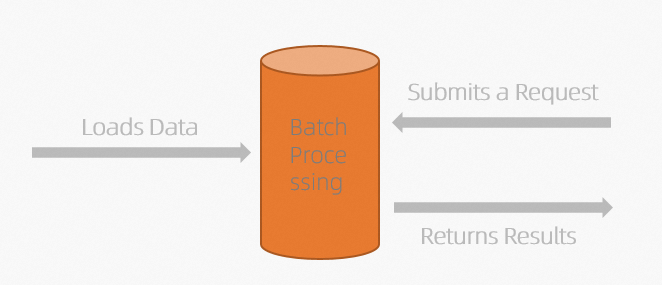 The traditional batch processing procedure consists of the following steps:
The traditional batch processing procedure consists of the following steps:- Load data.
To perform batch processing, the computing system must load data in advance. You can use an ETL or OLTP system as your computing system. The system performs a series of query optimization, analysis, and computations on the loaded data based on the storage and computation methods.
- Submit a request.A system initiates a computing deployment, such as a MaxCompute SQL deployment or a Hive SQL deployment, and submits requests to the computing system. Then, the computing system schedules computing nodes to handle these requests. The entire process may take several minutes or even hours. This results in a long delay before users can obtain insights, and is not suitable for time-sensitive applications.Note For batch processing, you can adjust SQL statements at any time based on your business requirements. You can also perform ad hoc queries to instantly modify and query data.
- Return the result data.
After the computing deployment is complete, the results are returned as a result set, which is generally quite large. This data then needs to be written to storage or downstream services. This process may take several minutes or even hours to complete.
- Load data.
- Real-time computing Real-time computing deployments are continuously triggered by events. Results are usually obtained with minimal delay. The real-time computing model is simple. Therefore, real-time computing is considered a value-added service of batch processing in most big data processing scenarios. Real-time computing provides computations on data streams that have short delays. The following figure shows the real-time computing model.
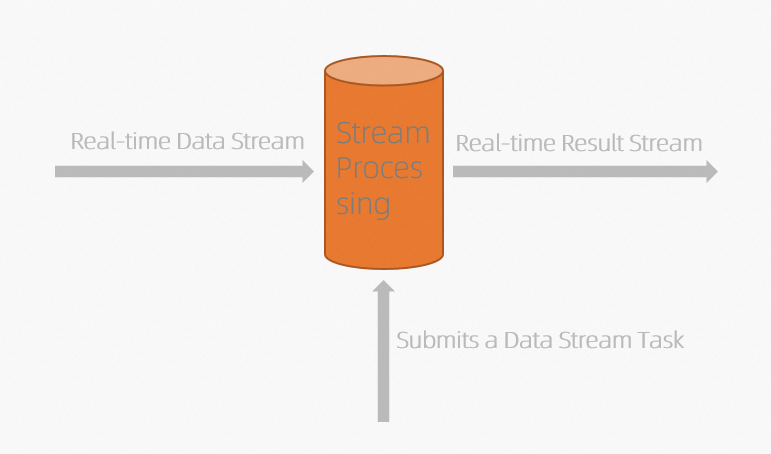
- Send real-time data streams.
Data integration tools are used to send streaming data to streaming data stores, such as Message Queue and DataHub, in real time. Streaming data is sent in micro batches in real time to minimize the delay in data integration.
Streaming data is continuously written to data stores without the need to preload the data. Realtime Compute for Apache Flink does not store data that has been processed. Streaming data is immediately discarded after the data is processed.
- Publish a streaming draft. In batch processing, you can start a computing deployment only after data integration is complete. A real-time computing deployment is a resident computing service. When you start a Realtime Compute for Apache Flink deployment, Realtime Compute for Apache Flink immediately computes streaming data and generates results after a small batch of data enters a streaming data store. It also splits up large batches of data into smaller batches and processes them incrementally. This effectively shortens the processing delay. For a streaming deployment, you must predefine the computational logic for the deployment and publish the draft for the deployment to Realtime Compute for Apache Flink.Note When a streaming deployment is running during real-time computing, you can modify the logic of the deployment but the modification cannot take effect in real time. To make the modification take effect, you must restart the deployment. Data that has been calculated cannot be recalculated.
- Generate result data streams in real time.
In batch processing, result data can be written to an online system at the same time only after all accumulated data is processed. A streaming deployment delivers result data to an online system or a batch system immediately after each micro batch of data records is processed.
Real-time computing is performed in the following sequence:- A user publishes a real-time computing draft.
- Streaming data triggers the real-time computing deployment.
- The result data of the real-time computing deployment is continuously written to the destination system.
- Send real-time data streams.
| Item | Batch processing | Real-time computing |
|---|---|---|
| Data integration | The data processing system must load data in advance. | Realtime Compute for Apache Flink loads data in real time. |
| Computational logic | The computational logic can be changed, and data can be reprocessed. | If the computational logic is changed, data cannot be reprocessed because streaming data is processed in real time. |
| Data scope | You can query and process all or most data in a dataset. | You can query and process the latest data record or the data within a rolling window. |
| Data amount | A large amount of data is processed. | Individual records or micro batches of data that consist of a few records are processed. |
| Performance | Data processing takes several minutes or hours. | Data processing takes several milliseconds or seconds. |
| Analysis | The analysis is complex. | The analysis is based on simple response functions, aggregates, and rolling metrics. |