Information Schema is the metadata service of MaxCompute. This topic describes the basic concepts, features, and limits of Information Schema.
MaxCompute Information Schema provides information such as project metadata and historical usage data. Fields and views that are specific to MaxCompute are added to ANSI SQL-92 Information Schema. MaxCompute provides a public project named Information Schema. You can query the metadata and historical usage data of your project by accessing the read-only views provided by this public project.
Limits
Information Schema provides metadata views of the current project. You are not authorized to access cross-project metadata. If you want to query and analyze the metadata of multiple projects, you must obtain the metadata of each project and integrate the metadata.
Quasi-real-time views are provided for metadata system tables. For applications that require high metadata timeliness, we recommend that you use an SDK or CLI to obtain the metadata of a specified object.
Metadata and historical data of jobs are stored in the Information Schema project. To create a snapshot of the historical data or obtain historical job data of more than 14 days, you can back up Information Schema data to a specified project on a regular basis.
Obtain the Information Schema service
From March 1, 2024, MaxCompute no longer automatically provides the project-level Information Schema service for new projects. By default, no package of project-level Information Schema is provided for the projects that are created on March 1, 2024 and onwards. If you want to query metadata, you can use tenant-level Information Schema to obtain more comprehensive information. For more information about how to use tenant-level Information Schema, see Tenant-level Information Schema.
Before you use Information Schema in an existing project, you must obtain the permissions to access the project metadata. To obtain the permissions, install the Information Schema permission package as the project owner or a RAM user that is assigned the Super_Administrator role. For more information, see Assign a role to a user. You can use one of the following methods to install the permission package:
Log on to the MaxCompute client and run the following command:
install package Information_Schema.systables;Log on to the DataWorks console and go to the SQL Query page. For more information about ad hoc queries, see Use the ad-hoc query feature to execute SQL statements (optional). Run the following command:
install package Information_Schema.systables;
After the package is installed, you can use Information Schema to query the metadata of the current project. Data is stored in the Information Schema project. You do not need to pay for metadata storage.
You can run the following command to query the views provided by the Information Schema project:
odps@myproject1> describe package Information_Schema.systables;The following figure shows the query result.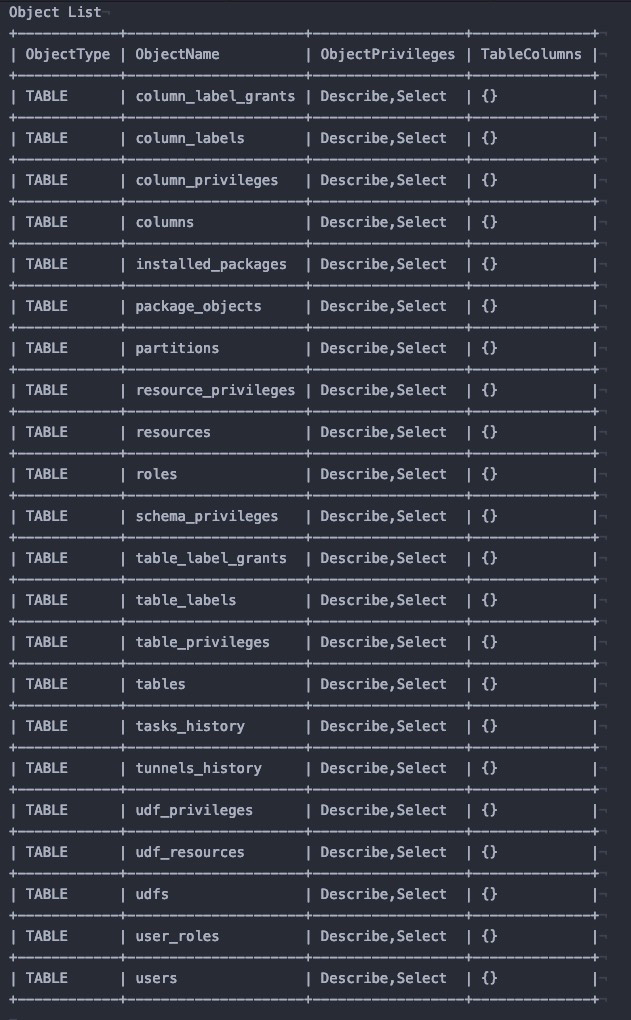
Query a metadata view
If you want to query a metadata view, you must prefix the project name Information Schema to the view name. The format is Information Schema.view_name.
If the project that you access is myproject1, you can run the following command to query the metadata of all tables in myproject1:
odps@myproject1>select * from Information_Schema.tables;The Information Schema project also contains the job history view. This view allows you to query the job history of the current project. You can run the following command to query historical jobs by date:
odps@myproject1>select * from Information_Schema.tasks_history where ds='yyyymmdd' limit 100;Access authorization
The views provided by Information Schema contain all the user data at the project level. By default, the owner of a project can view the user data of this project. Other users or roles in the project must be granted the required permissions to view the data. For more information, see Cross-project resource access based on packages.
Syntax of the statements that are used to grant permissions to users or roles:
grant <actions> on package Information_Schema.systables to user <user_name>;
grant <actions> on package Information_Schema.systables to role <role_name>;actions: the permissions that you want to grant. Set the value to Read.
user_name: an Alibaba Cloud account or RAM user that is added to the project.
You can run the list users; command on the MaxCompute client to obtain user accounts.
role_name: a role that is added to the project.
You can run the
list roles;command on the MaxCompute client to query the name of the role.
Example:
grant read on package Information_Schema.systables to user RAM$Bob@aliyun.com:user01;Metadata views
The metadata views of the Information Schema service allow you to browse and retrieve metadata.
The usage information views of the Information Schema service allow you to optimize jobs and plan resources. For example, you can analyze the metrics of a job, such as the resource consumption, running duration, and amount of processed data.
Different views have different validity periods or default retention periods. Data that exceeds the retention period is inaccessible. You can manually export data from Information Schema to a MaxCompute table to back up the data at a specified interval. This backup applies to historical data that requires a longer storage period.
The fees for Information Schema vary based on the following scenarios:
For projects that use pay-as-you-go computing resources, you are charged based on the SQL statements that you execute to query a view of Information Schema.
Range-clustered tablesare used in the views of Information Schema to reduce the amount of input query data and improve query performance. If you query the TASKS_HISTORY and TUNNELS_HISTORY views, query the data of the previous day after 6:00:00 every day to avoid querying the data of the current day. This minimizes the amount of input query data and reduces query costs.For projects that use subscription computing resources, the compute units (CUs) that you purchased are consumed when you query views of Information Schema.
You do not need to pay storage fees for the views of Information Schema.
When you export data, we recommend that you explicitly specify the field names of the view. If you do not explicitly specify the field names of the view, you may fail to back up data by running insert into select * from information_schema.*** after some fields are inserted into a MaxCompute table.
The following table describes the metadata views.
Type | View | Timeliness and retention period | Delay |
Metadata information | Quasi-real-time view | Online data is displayed in metadata views with a delay of about 3 hours. | |
Quasi-real-time view | |||
Quasi-real-time view | |||
Quasi-real-time view | |||
Quasi-real-time view | |||
Quasi-real-time view | |||
Quasi-real-time view | |||
Quasi-real-time view | |||
Quasi-real-time view | |||
Quasi-real-time view | |||
Quasi-real-time view | |||
Quasi-real-time view | |||
Quasi-real-time view | |||
Quasi-real-time view | |||
Quasi-real-time view | |||
Quasi-real-time view | |||
Quasi-real-time view | |||
Quasi-real-time view | |||
Quasi-real-time view | |||
Quasi-real-time view | |||
Usage information | Real-time snapshots of running jobs | Online data is displayed in metadata views with a delay of a few seconds. This view is in public preview without SLA guarantee and will be available in the future. | |
Quasi-real-time view. Historical data is stored in a partitioned table, and data from the last 14 days is retained. | Online data is displayed in metadata views with a delay of approximately 3 hours. | ||
Quasi-real-time view. Historical data is stored in a partitioned table, and data from the last 14 days is retained. |
TABLES
Displays the information about a table in a project.
Field | Data type | Description |
table_catalog | STRING | The value is fixed to |
table_schema | STRING | The name of the project. |
table_name | STRING | The name of the table. |
table_type | STRING | The type of the table. Valid values:
|
is_partitioned | BOOLEAN | Specifies whether the table is a partitioned table. |
owner_id | STRING | The ID of the table owner. |
owner_name | STRING | Optional. The Alibaba Cloud account of the table owner. |
create_time | DATETIME | The time when the data table was created. |
last_modified_time | DATETIME | The time when the table data was last modified. |
data_length | BIGINT | If the table is a non-partitioned table, the value of this parameter is the size of the table data. If the table is a partitioned table, the system does not calculate the size of the table data. In this case, the value of this parameter is NULL. The PARTITIONS view includes the data size of each partition in a partitioned table. Unit: bytes. |
table_comment | STRING | The comments on the table. |
life_cycle | BIGINT | Optional. The lifecycle of the table. |
is_archived | BOOLEAN | A reserved field. |
table_exstore_type | STRING | A reserved field. |
cluster_type | STRING | The clustering type of the MaxCompute table. Valid values: HASH and RANGE. |
number_buckets | BIGINT | Optional. The number of buckets in the clustered table. The value 0 indicates that the number of buckets dynamically changes during job execution. |
view_original_text | STRING | The view text in the table of the VIRTUAL_VIEW type. |
PARTITIONS
Displays information about a table partition in a project.
Field | Data type | Description |
table_catalog | STRING | The value is fixed to |
table_schema | STRING | The name of the project. |
table_name | STRING | The name of the table. |
partition_name | STRING | The name of the partition. Example: |
create_time | DATETIME | The time when the partition was created. |
last_modified_time | DATETIME | The time when the table was last modified. |
data_length | BIGINT | The size of the data in the partition. Unit: bytes. |
is_archived | BOOLEAN | A reserved field. |
is_exstore | BOOLEAN | A reserved field. |
cluster_type | STRING | Optional. The clustering type of the MaxCompute table. Valid values: HASH and RANGE. |
number_buckets | BIGINT | Optional. The number of buckets in the clustered table. The value 0 indicates that the number of buckets dynamically changes during job execution. |
COLUMNS
Displays information about a table column in a project.
Field | Data type | Description |
table_catalog | STRING | The value is fixed to |
table_schema | STRING | The name of the project. |
table_name | STRING | The name of the table. |
column_name | STRING | The name of the column. |
ordinal_position | BIGINT | The serial number of the column. |
column_default | STRING | The default value of the column. |
is_nullable | BOOLEAN | Optional. The value is fixed to YES. |
data_type | STRING | The data type of the column. |
column_comment | STRING | The comments on the column. |
is_partition_key | BOOLEAN | Specifies whether the column is a partition key. |
UDFS
Displays information about a user-defined function (UDF) in a project.
Field | Data type | Description |
udf_catalog | STRING | The value is fixed to |
udf_schema | STRING | The name of the project. |
udf_name | STRING | The name of the UDF. |
owner_id | STRING | The ID of the UDF owner. |
owner_name | STRING | Optional. The Alibaba Cloud account of the UDF owner. |
create_time | DATETIME | The time when the UDF was created. |
last_modified_time | DATETIME | The last time when the UDF was modified. |
RESOURCES
Displays information about a resource in a project.
Field | Data type | Description |
resource_catalog | STRING | The value is fixed to |
resource_schema | STRING | The name of the project. |
resource_name | STRING | The name of the resource. |
resource_type | STRING | The type of the resource. Valid values: Py and Jar. |
owner_id | STRING | The ID of the resource owner. |
owner_name | STRING | Optional. The Alibaba Cloud account of the resource owner. |
create_time | DATETIME | The time when the resource was created. |
last_modified_time | DATETIME | The time when the resource was last modified. |
size | BIGINT | The storage space used by the resource. |
comment | STRING | The comments on the resource. |
is_temp_resource | BOOLEAN | Specifies whether the resource is a temporary resource. |
UDF_RESOURCES
Displays information about the dependent resource of a UDF in a project.
Field | Data type | Description |
udf_catalog | STRING | The value is fixed to |
udf_schema | STRING | The name of the project. |
udf_name | STRING | The name of the UDF. |
resource_schema | STRING | The name of the project to which the resource belongs. |
resource_name | STRING | The name of the resource. |
USERS
Displays the list of users in a project.
Field | Data type | Description |
user_catalog | STRING | Valid values: ALIYUN and RAM. |
user_schema | STRING | The name of the project. |
user_name | STRING | Optional. The name of the user. |
user_id | STRING | The ID of the Alibaba Cloud user. |
user_label | STRING | The label of the user. |
ROLES
Displays the list of roles in a project.
Field | Data type | Description |
role_catalog | STRING | The value is fixed to |
role_schema | STRING | The name of the project. |
role_name | STRING | The name of the role. |
role_label | STRING | The label of the role. |
comment | STRING | The comments on the role. |
USER_ROLES
Displays information about a role that a user assumes in a project.
Field | Data type | Description |
user_role_catalog | STRING | The value is fixed to |
user_role_schema | STRING | The name of the project. |
role_name | STRING | The name of the role. |
user_name | STRING | The name of the user. |
user_id | STRING | The ID of the user. |
PACKAGE_OBJECTS
Displays the object information of a package in a project.
Field | Data type | Description |
package_catalog | STRING | The value is fixed to |
package_schema | STRING | The name of the project. |
package_name | STRING | The name of the package. |
object_type | STRING | The type of the package object. |
object_name | STRING | The name of the package object. |
column_name | STRING | The name of the table column. |
allowed_privileges | VECTOR<STRING> | The shared permissions. |
allowed_label | STRING | The shared label. |
INSTALLED_PACKAGES
Displays information about an installed package in a project.
Field | Data type | Description |
installed_package_catalog | STRING | The value is fixed to |
installed_package_schema | STRING | The name of the project. |
package_project | STRING | The name of the project in which the package was created. |
package_name | STRING | The name of the package. |
installed_time | DATETIME | Reserved. The time when the package was installed. |
allowed_label | STRING | The shared label. |
SCHEMA_PRIVILEGES
Displays information about a schema permission in a project.
Field | Data type | Description |
user_catalog | STRING | The value is fixed to |
user_schema | STRING | The name of the project. |
grantee | STRING | The name of the user. |
user_id | STRING | The ID of the user. |
grantor | STRING | The account that grants the permission. The current value is NULL. |
privilege_type | STRING | The type of the permission. |
TABLE_PRIVILEGES
Displays information about a table permission in a project.
Field | Data type | Description |
table_catalog | STRING | The value is fixed to |
table_schema | STRING | The name of the project to which the table belongs. |
table_name | STRING | The name of the table. |
grantee | STRING | The name of the user. |
user_id | STRING | The ID of the user. |
grantor | STRING | The account that grants the permission. The current value is NULL. |
privilege_type | STRING | The type of the permission. |
user_schema | STRING | The name of the project to which the user belongs. |
COLUMN_PRIVILEGES
Displays information about a column permission in a project.
Field | Data type | Description |
table_catalog | STRING | The value is fixed to |
table_schema | STRING | The name of the project to which the table belongs. |
table_name | STRING | The name of the table. |
column_name | STRING | The name of the column. |
grantee | STRING | The name of the user. |
user_id | STRING | The ID of the user. |
grantor | STRING | Optional. The current value is NULL. |
privilege_type | STRING | The type of the permission. |
user_schema | STRING | The name of the project to which the user belongs. |
UDF_PRIVILEGES
Displays information about a UDF permission in a project.
Field | Data type | Description |
udf_catalog | STRING | The value is fixed to |
udf_schema | STRING | The name of the project. |
udf_name | STRING | The name of the UDF. |
user_schema | STRING | The name of the project to which the user belongs. |
grantee | STRING | The name of the user. |
user_id | STRING | The ID of the user. |
grantor | STRING | The account that grants the permission. The current value is NULL. |
privilege_type | STRING | The type of the permission. |
RESOURCE_PRIVILEGES
Displays information about a resource permission in a project.
Field | Data type | Description |
resource_catalog | STRING | The value is fixed to |
resource_schema | STRING | The name of the project. |
resource_name | STRING | The name of the resource. |
user_schema | STRING | The name of the project to which the user belongs. |
grantee | STRING | The name of the user. |
user_id | STRING | The ID of the user. |
grantor | STRING | The account that grants the permission. The current value is NULL. |
privilege_type | STRING | The type of the permission. |
TABLE_LABELS
Displays information about a table label in a project.
Field | Data type | Description |
table_catalog | STRING | The value is fixed to |
table_schema | STRING | The name of the project. |
table_name | STRING | The name of the table. |
label_type | STRING | The type of the label. The value is fixed to NULL. |
label_level | STRING | The level of the label. |
COLUMN_LABELS
Displays information about a table column label in a project.
Field | Data type | Description |
table_catalog | STRING | The value is fixed to |
table_schema | STRING | The name of the project. |
table_name | STRING | The name of the table. |
column_name | STRING | The name of the column. |
label_type | STRING | The type of the label. The value is fixed to NULL. |
label_level | STRING | The level of the label. |
TABLE_LABEL_GRANTS
Displays the authorization information of a table label in a project.
Field | Data type | Description |
table_label_grant_catalog | STRING | The value is fixed to |
table_label_grant_schema | STRING | The name of the project to which the user belongs. |
user | STRING | The name of the user. |
user_id | STRING | The ID of the user. |
table_schema | STRING | The name of the project to which the table belongs. |
table_name | STRING | The name of the table. |
grantor | STRING | The account that grants the permission. The current value is NULL. |
label_level | STRING | The granted level of the label. |
expired | DATETIME | The time when the authorization expires. |
COLUMN_LABEL_GRANTS
Displays the authorization information of a table column label in a project.
Field | Data type | Description |
column_label_grant_catalog | STRING | The value is fixed to |
column_label_grant_schema | STRING | The name of the project to which the user belongs. |
user | STRING | The name of the user. |
user_id | STRING | The ID of the user. |
table_schema | STRING | The name of the project to which the table belongs. |
table_name | STRING | The name of the table. |
column_name | STRING | The name of the column. |
grantor | STRING | The account that grants the permission. The current value is NULL. |
label_level | STRING | The granted level of the label. |
expired | DATETIME | The time when the authorization expires. |
TASKS
Displays the real-time snapshots of jobs. This view is used to monitor jobs in real time.
The TASKS view is in the internal testing process and its fields and field content may be changed. This view has no SLA guarantee. Use this view with caution. For more information about the subsequent changes of the release status, see Service notices.
Field | Data type | Description |
project_name | STRING | The name of the project. |
task_name | STRING | The name of the job. |
task_type | STRING | The type of the job. Valid values:
|
inst_id | STRING | The ID of the instance that is created for the job. |
status | STRING | The status of the job when data is collected. Valid values: Running and Waiting. |
owner_id | STRING | The ID of the Alibaba Cloud account that submits the job. |
owner_name | STRING | The name of the Alibaba Cloud account that submits the job. |
start_time | DATETIME | The time when the job starts. |
priority | BIGINT | The priority of the job. This parameter is applicable only to jobs that use subscription resources. |
signature | STRING | The job signature. |
queue_name | STRING | The name of the compute queue. |
cpu_usage | BIGINT | The current CPU utilization. The value of this field is calculated by using the following formula: Number of CPU cores × 100. |
mem_usage | BIGINT | The current memory usage. Unit: MB. |
gpu_usage | BIGINT | The current GPU usage. The value of this field is calculated by using the following formula: Number of GPUs × 100. |
total_cpu_usage | BIGINT | The accumulated CPU utilization. The value of this field is calculated by using the following formula: Number of CPU cores × 100 × Running duration of the job (seconds). |
total_mem_usage | BIGINT | The accumulated memory usage. The value of this field is calculated by using the following formula: Memory size (MB) × Running duration of the job (seconds). |
total_gpu_usage | BIGINT | The accumulated GPU usage. The value of this field is calculated by using the following formula: Number of GPUs × 100 × Running duration of the job (seconds). |
cpu_min_ratio | BIGINT | The ratio of the CPU utilization of the job to the total CPU utilization. This parameter is applicable only to jobs that use subscription resources. |
mem_min_ratio | BIGINT | The ratio of the memory consumed by the job to the total memory usage. This parameter is applicable only to jobs that use subscription resources. |
gpu_min_ratio | BIGINT | The ratio of the GPUs consumed by the job to the total GPU usage. This parameter is applicable only to jobs that use subscription resources. |
cpu_max_ratio | BIGINT | The ratio of the CPU utilization of the job to the maximum CPU utilization. This parameter is applicable only to jobs that use subscription resources. |
mem_max_ratio | BIGINT | The ratio of the memory consumed by the job to the maximum memory usage. This parameter is applicable only to jobs that use subscription resources. |
gpu_max_ratio | BIGINT | The ratio of the GPUs consumed by the job to the maximum GPU usage. This parameter is applicable only to jobs that use subscription resources. |
settings | STRING | The custom scheduling settings of an upper-layer application, such as DataWorks. |
additional_info | STRING | The additional information. This is a reserved field. |
TASKS_HISTORY
Displays the job execution history in a MaxCompute project. Data from the last 14 days is retained.
Field | Data type | Description |
task_catalog | STRING | The value is fixed to |
task_schema | STRING | The name of the project. |
task_name | STRING | The name of the job. |
task_type | STRING | The type of the job. Valid values:
|
inst_id | STRING | The ID of the instance. |
status | STRING | The status of the job when data is collected. This is not a real-time state. Valid values:
|
owner_id | STRING | The ID of the Alibaba Cloud account. |
owner_name | STRING | The name of the Alibaba Cloud account. |
result | STRING | The error information displayed if an error occurs in an SQL job. |
start_time | DATETIME | The time when the job starts. |
end_time | DATETIME | The end time of the job. If the job does not end on the current day, this value is NULL. |
input_records | BIGINT | The number of records read by the job. |
output_records | BIGINT | The number of records generated by the job. |
input_bytes | BIGINT | The amount of scanned data, which is the same as that displayed on LogView. |
output_bytes | BIGINT | The number of output bytes. |
input_tables | STRING | The job input tables in the [project.table1,project.table2] format. Some jobs, such as SQL COST jobs, do not have such information. |
output_tables | STRING | The job output tables in the [project.table1,project.table2] format. |
operation_text | STRING | The source XML file of the query statement. If the size of the source XML file exceeds 256 KB, set the value to NULL. |
signature | STRING | Optional. The job signature. |
complexity | DOUBLE | Optional. The job complexity. This parameter is available only for SQL jobs. |
cost_cpu | DOUBLE | The CPU utilization of the job. The value 100 indicates that 1 CPU core multiplies the job running duration in seconds. For example, if 10 CPU cores run for five seconds, cost_cpu is 5000, which is calculated by using the following formula: 10 × 100 × 5. |
cost_mem | DOUBLE | The memory consumed by the job. The value of this field is calculated by using the following formula: Memory size (MB) × Running duration of the job (seconds). |
settings | STRING | The information that is scheduled by the upper layer application or specified by users. The information is saved in the JSON format. The information includes the following fields: USERAGENT, BIZID, SKYNET_ID, and SKYNET_NODENAME. |
ds | STRING | The date when the data was collected. Example: 20190101. |
TUNNELS_HISTORY
Displays historical data that is uploaded and downloaded at the same time over a data tunnel. Data of the previous 14 days is retained.
Field | Data type | Description |
tunnel_catalog | STRING | The value is fixed to |
tunnel_schema | STRING | The name of the project. |
session_id | STRING | The session ID, which is saved in the format of |
operate_type | STRING | The type of the operation. Valid values:
|
tunnel_type | STRING | The type of the tunnel. Valid values: TUNNEL LOG and TUNNEL INSTANCE LOG. |
request_id | STRING | The ID of the request. |
object_type | STRING | The type of object on which the operation is performed. Valid values: TABLE and INSTANCE. |
object_name | STRING | The table name or instance ID. |
partition_spec | STRING | The partition information. Example: |
data_size | BIGINT | The size of data. Unit: bytes. |
block_id | BIGINT | The ID of the block uploaded by using the tunnel. This parameter is available only if operate_type is set to UPLOADLOG. Otherwise, this parameter is left empty. |
offset | BIGINT | The number of records to skip before data is downloaded. By default, the download starts from record 0. |
length | BIGINT | The number of records to download or upload in the current session. The number of downloaded records is equal to the value of this parameter. |
owner_id | STRING | The ID of the Alibaba Cloud account. |
owner_name | STRING | The name of the Alibaba Cloud account. |
start_time | DATETIME | The start time of the request. |
end_time | DATETIME | The end time of the request. |
client_ip | STRING | The IP address of the client that initiates the request. |
user_agent | STRING | The information about the user agent, which is the client that initiates the request. The information may be the Java version or the operating system. |
columns | STRING | The columns that are specified when the data is downloaded over a data tunnel. |
ds | STRING | The date when the data was collected. Example: 20190101. |