A dataset is a set of data that has similar attributes or is used by the same targets. You can update data and delete data of different sources from datasets. This topic describes how to manage datasets in AI Dashboard.
Prerequisites
The cloud-native AI component set is installed. For more information, see Deploy the cloud-native AI suite.
The credentials of the administrator of AI Dashboard are obtained.
Create an accelerated dataset based on an existing PVC
Log on to AI Dashboard. For more information, see Access AI Dashboard.
In the left-side navigation pane of AI Dashboard, choose .
Select the dataset that you want to accelerate and click Accelerate in the Operator column.
NoteIf no other types of data exist, the Dataset List page displays all persistent volume claims (PVCs) in the current cluster.
In the Edit Dataset dialog box, set the following parameters:
Specify a name for the dataset that you want to accelerate and select the namespace to which the dataset belongs.
Select PVC for Source Type, select Data Source, and then enter Sub Dir.
Set Runtime Config. The name field must be set to the name of the dataset.
The following template of Runtime Config is provided as an example:
apiVersion: data.fluid.io/v1alpha1 kind: JindoRuntime metadata: name: fluid-imagenet spec: replicas: 4 data: replicas: 1 tieredstore: levels: - mediumtype: SSD path: /var/lib/docker/alluxio quota: 150Gi high: "0.99" low: "0.8"
Click Save. The state of the dataset displays NotReady. Wait a few seconds. Then, the state of the dataset changes to Ready.
Create an accelerated dataset based on OSS
Step 1: Create a Secret
The Object Storage Service (OSS) configuration contains sensitive information and must be encrypted before you pass the information to AI Dashboard. You must create a Secret. The following YAML template is an example:
apiVersion: v1
kind: Secret
metadata:
name: imagenet-oss-xxx
namespace: default
type: kubernetes.io/basic-auth
stringData:
username: <ACCESS_ID>
password: <ACCESS_KEY>Run the following command to create a Secret:
kubectl create -f oss_access_secret.yamlStep 2: Create an accelerated dataset based on OSS
Log on to AI Dashboard. For more information, see Access AI Dashboard.
In the left-side navigation pane of AI Dashboard, choose .
Click Add.
In the Create Dataset dialog box, set the following parameters:
Specify a name for the dataset that you want to create and select the namespace to which the dataset belongs.
Select OSS for Source Type. The following table describes the parameters.
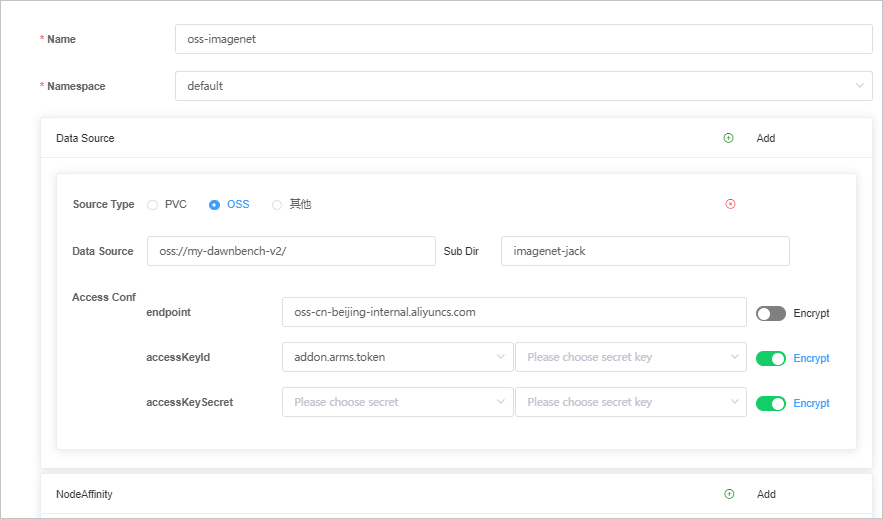
Parameter
Example
Description
Name
oss-imagenet
You can enter a custom name.
Namespace
default
Set the value to the
namespacethat is specified in the configurations of the Secret that you created. For more information, see Step 1: Create a Secret.Data Source
oss://my-dawnbench-v2/
N/A
Sub Dir
mydawnbench-v2
You can enter a custom subdirectory.
endpoint
oss-xxx.aliyuncs.com
N/A
accessKeyId
secret: imagenet-oss-xxx
secretKey: username
Set secret to the
nameof the Secret that you created. For more information, see Step 1: Create a Secret.Set secretkey to the
usernamethat is specified in the configurations of the Secret that you created. For more information, see Step 1: Create a Secret.
accessKeySecret
secret: imagenet-oss-xxx
secretKey: password
Set secret to the
nameof the Secret that you created. For more information, see Step 1: Create a Secret.Set secretkey to the
passwordthat is specified in the configurations of the Secret that you created. For more information, see Step 1: Create a Secret.
To make sure that the dataset is created on the node that you want to access, run the following command to add a node affinity:
aliyun.accelerator/nvidia_name in Tesla-V100-SXM2-16GB;Tesla-V100-SXM2-32GBSet Runtime Config. The name field must be set to the name of the dataset.
The following template of Runtime Config is provided as an example:
apiVersion: data.fluid.io/v1alpha1 kind: JindoRuntime metadata: name: oss-imagenet spec: replicas: 2 data: replicas: 1 tieredstore: levels: - mediumtype: SSD path: /var/lib/docker/alluxio quota: 150Gi high: '0.99' low: '0.8'
Click Save. The state of the dataset displays NotReady. Wait a few seconds. Then, the state of the dataset changes to Ready.
Create an accelerated dataset based on other storage services
Log on to AI Dashboard. For more information, see Access AI Dashboard.
In the left-side navigation pane of AI Dashboard, choose .
Click Add.
In the Create Dataset dialog box, set the following parameters:
Specify a name for the dataset that you want to create and select the namespace to which the dataset belongs.
Select Others for Source Type, set Data Source, and then set Sub Dir.
Set Runtime Config. The name field must be set to the name of the dataset.
The following template of Runtime Config is an example:
apiVersion: data.fluid.io/v1alpha1 kind: JindoRuntime metadata: name: fluid-imagenet spec: replicas: 4 data: replicas: 1 tieredstore: levels: - mediumtype: SSD path: /var/lib/docker/alluxio quota: 150Gi high: "0.99" low: "0.8"
Click Save. The state of the dataset displays NotReady. Wait a few seconds. Then, the state of the dataset changes to Ready.
Delete a dataset
Regular users cannot delete datasets that are not accelerated. Only the administrator with the relevant Alibaba Cloud account can delete datasets in the ACK console.
Log on to AI Dashboard as an administrator.
Find the dataset that you want to delete and click Delete in the Operator column.