This topic describes the billing rules, features, limits, and terms of Connector Ecosystem Integration.
Background Information
In the process of digital transformation, enterprises face various pain points, such as the lack of a centralized method to integrate information, inefficient data transfer and integration caused by various data formats and types, the lack of a service to share data and backend services, and the lack of a secure channel to connect cloud-based and on-premises resources. To resolve the pain points, Alibaba Cloud provides a full-stack message and data integration module called Connector Ecosystem Integration. The module helps you simplify the integration process with other products and supports cloud-based and on-premises integration across regions.
Connector Ecosystem Integration provides low-code and full-stack event stream processing for messaging services. Focusing on scenarios such as message integration, data connection, data processing, and service integration, Connector Ecosystem Integration provides a visualized user interface that allows you to easily create and orchestrate integration tasks. Connector Ecosystem integration also allows you to connect devices across regions, instances, and applications. This helps reduce costs for message integration and development.
Prerequisites
The connector feature is implemented based on EventBridge and Function Compute. Before you use a connector, make sure that the following operations are performed:
Activate the destination service. For example, if you want to create a connector task whose sink is Tablestore, activate Tablestore.
NoteIf the destination service is Simple Log Service, you do not need to activate Function Compute.
Billing rules
For information about the billing rules of EventBridge, see Billing.
For information about the billing rules of Function Compute, see Billing overview.
Permission policies
If you use an Alibaba Cloud account to create a connector task in the ApsaraMQ for Kafka console, follow the on-screen instructions to configure the permission policy.
If you use a RAM user to create a connector task in the ApsaraMQ for Kafka console, make sure that the following permission policies are attached to the RAM user:
AliyunKafkaFullAccess: used to manage resources in ApsaraMQ for Kafka.
AliyunFCFullAccess: used to manage resources in Function Compute.
AliyunEventBridgeFullAccess: used to manage resources in EventBridge.
The permission policy that is used to manage the destination service.
If you want to use extended capabilities, you must also obtain other required permissions. Examples:
If you want to access the destination service in a virtual private cloud (VPC), the AliyunVPCFullAccess permission policy must be attached to the RAM user to manage VPC resources.
If you want to view running logs of Function Compute, the AliyunLogFullAccess permission policy must be attached to the RAM user to manage Simple Log Service.
Features
Various data sources
Connector Ecosystem Integration aims to connect data that is stored in and across clouds. Connector Ecosystem Integration allows you to import data from the logs and self-managed applications of various services in the cloud to a destination service. Data import across clouds is also supported. You can use Connector Ecosystem Integration to synchronize data from logs, databases, and message-oriented middleware.
Data cleansing and data outflow
Connector Ecosystem Integration provides powerful, UI-based extract-transform-load (ETL) capability. You can use the capability to cleanse and format data that is received by message queues and convert the format of the data. Connector Ecosystem Integration also allows you to dump data that is extracted, transformed, and loaded to downstream systems.
Serverless custom processing
By leveraging the custom coding capability provided by Function Compute, a serverless computing service provided by Alibaba Cloud, Connector Ecosystem Integration allows you to write custom business logic and complete custom data processing and distribution.
Limits
The following table describes the limits of Connector Ecosystem Integration.
Item | Description |
Number of tasks | Up to 20 connector tasks can be created in a region, including source connector tasks and sink connector tasks. If you want to increase the quota, submit a ticket. |
Task name | The name can contain letters, digits, and hyphens (-) and must start with a letter or a digit. The name can be up to 127 characters in length. If the name that you specify is more than 127 characters in length, the system truncates the value. |
Event pattern | In the stringExpression pattern, each field can contain up to five expressions in the map data structure. |
Event transformation |
|
Data loss in extreme cases | For more information, see Retry policies and dead-letter queues. |
Message Inflow (Source)
Message Inflow, or Source, is a component of Connector Ecosystem Integration. Message Inflow allows you to integrate data, including messages, logs, relational data, and non-relational data, between multiple data sources in a flexible, rapid, and non-intrusive manner. Message Inflow can help implement data integration solutions across data centers and clouds, and provides features to help you operate, manage, and monitor the integrated data. The major capabilities of Message Inflow are to synchronize data of various types to ApsaraMQ for Kafka, and manage and filter data from different sources.
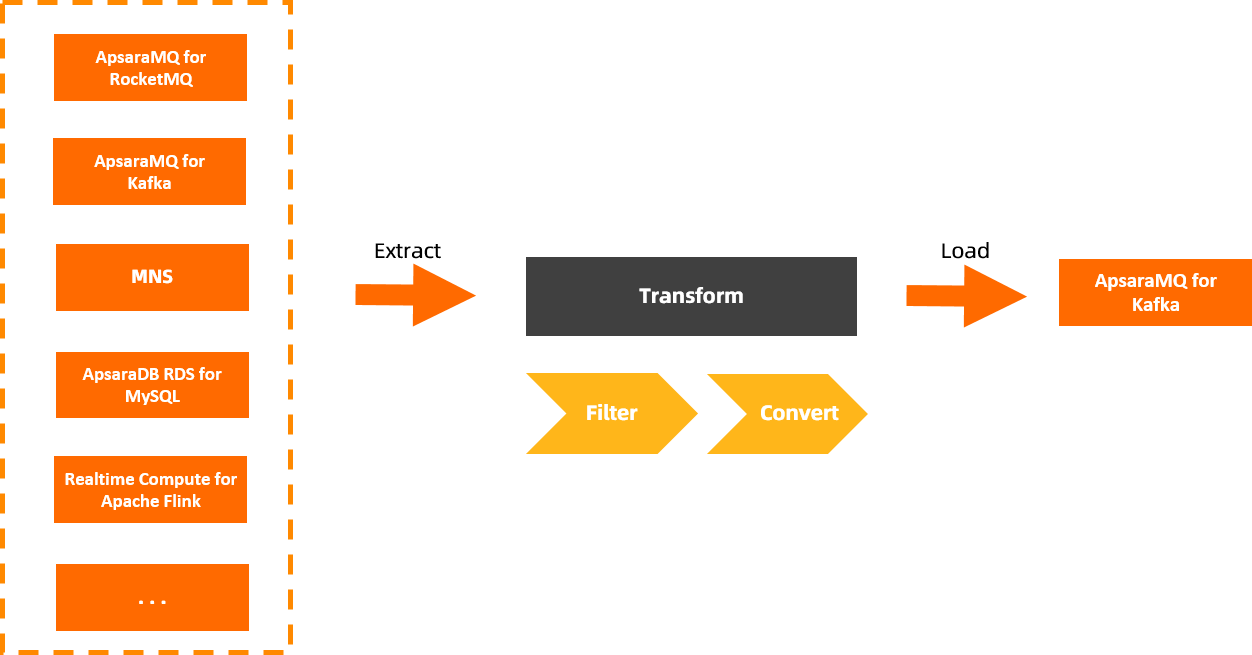
Message Outflow (Sink)
The major capability of Message Outflow, or Sink, is to export data from ApsaraMQ for Kafka to various destination services. Connector Ecosystem Integration reliably distributes messages from ApsaraMQ for Kafka and cleanses and filters message data during distribution.
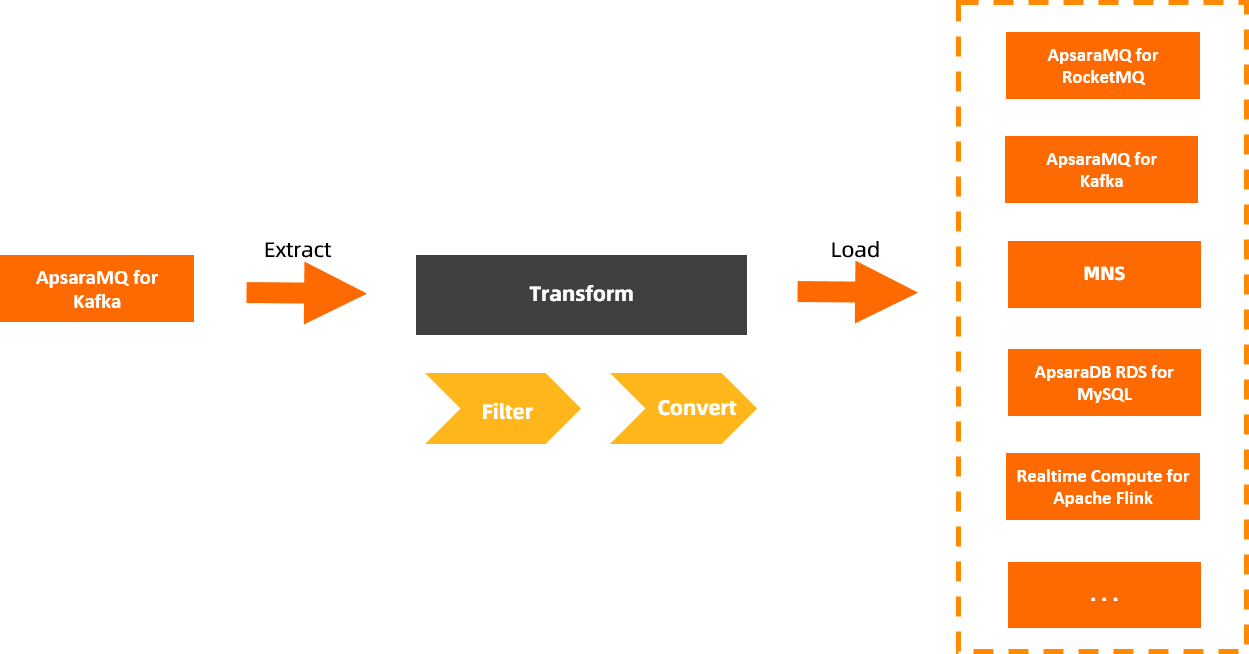
ETL (Transformation)
ETL, or Transformation, is an important component of Connector Ecosystem Integration. This capability is optional when you create a source or sink connector task. Connector Ecosystem Integration provides seven matching modes and five transformers based on the data processing capability provided by EventBridge and the custom definition capability provided by Function Compute to efficiently transform, process, and analyze messages. The matching modes are fixed-value matching, prefix matching, suffix matching, exclusion-based matching, numeric-value matching, array matching, and combined-condition matching. The transformers are complete event, partial event, constant, template, and Function Compute template.
Task
A task is a resource entity that runs Connector Ecosystem Integration. A task is also the method that is used to implement Connector Ecosystem Integration. In most cases, a task consists of a source, a sink, a filtering rule, and a transformation rule. The underlying resources of a task are the event streams of EventBridge.
When you create a task, you must specify the resources and the method that is used to process data. The configurations of resources are important parts of a task and include the configurations of the source and sink. For information about ETL, see ETL (Transformation).
After you create a task, you cannot change the resource type of the task.
Version description
Two versions of connectors are provided by ApsaraMQ for Kafka. If you did not create an old version connector by using your Alibaba Cloud account, the ApsaraMQ for Kafka console displays only the entry for creating new version connectors. If you created an old version connector by using your Alibaba Cloud account, the ApsaraMQ for Kafka console displays entries for creating old version and new version connectors. We recommend that you create a new version connector.
New version source connectors provide the same features as old version source connectors. The following table describes the feature differences between new version sink connectors and old version sink connectors.
Item | New version sink connector (recommended) | Old version sink connector |
Underlying dependency | Depend on EventBridge and Function Compute. Note The Simple Log Service sink connector depends only on EventBridge. | Different types of sink connectors depend on different services to implement capabilities. The following types of dependencies are supported:
To view the service on which a type of sink connector depends, see the documents of the corresponding connector. |
Message filtering | Multiple message filtering modes are supported. This helps filter messages that you do not need and improves processing efficiency. For more information, see Event patterns. | Not supported. |
Dead-letter queue | Queues in Simple Message Queue (formerly MNS) and ApsaraMQ for RocketMQ can be used as dead-letter queues. | Queues in ApsaraMQ for Kafka can be used as dead-letter queues. |
Retry policy | Supported by all types of sink connectors. | Only supported by specific types of sink connectors. |
Dependence on ApsaraMQ for Kafka resources | No. | Yes. Topics that are used to store offsets, configurations, status, dead-letter messages, and error data can be automatically or manually created. |
Cross-account transmission | Not supported. If you want to transmit data across accounts, submit a ticket. | Supported. |
Number of concurrent consumption threads | You can specify a custom value that is less than or equal to 32. | You can specify only one of the following values: 1, 2, 3, 6, and 12. |
Consumer group | You can create consumer groups or use existing consumer groups. | You must create new consumer groups. |