Lindorm Tunnel Service (LTS) provides a data synchronization feature that allows you to synchronize full data and incremental data. This topic describes the scenarios, features, benefits, and limits of this feature. This topic also describes the related operations such as creating data synchronization tasks.
Scenarios
Major version upgrades. For example, upgrade the major version of your ApsaraDB for HBase cluster from V1.x to V2.x.
Data migration across regions. For example, migrate data from a data center in the China (Qingdao) region to a data center in the China (Beijing) region.
Cross-account migration. For example, migrate data across different accounts.
Cluster specification upgrades. For example, upgrade the cluster specifications from 4 cores and 8 GB memory to 8 cores and 16 GB memory.
Workload decoupling. For example, migrate some workloads to a new cluster.
Features
This feature allows you to migrate data without service downtime between two of the following versions: HBase 094, HBase 098, HBase V1.x, HBase V2.x, and Lindorm.
This feature allows you to migrate table schemas, synchronize data in real time, and migrate full data.
This feature allows you to migrate data based on databases, namespaces, and tables.
This feature allows you to rename a table when you migrate the data in the table.
This feature allows you to specify the time range, the row key range, and the columns when you migrate data.
An API is provided. You can call API operations to create migration tasks.
Benefits
When data is being migrated, no service downtime is caused. In one task, LTS can migrate historical data and synchronize incremental data in real time.
When data is being migrated, LTS does not interact with the source HBase cluster. LTS reads data only from the Hadoop Distributed File System (HDFS) of the source cluster. This minimizes the impact on the online business that runs on the source cluster.
In most cases, compared with data migration at the API layer, data replication at the file layer helps you reduce more than 50% of the data usage and improves efficiency.
Each node can migrate data at a rate of up to 150 MB/s to meet stability requirements for data migration. You can add nodes for horizontal scaling to migrate terabytes or petabytes of data.
LTS implements a robust retry mechanism to respond to errors. LTS monitors the task speed and the task progress in real time, and generates alerts when tasks fail.
LTS automatically synchronizes schemas to ensure consistent partitions.
Limits
ApsaraDB for HBase clusters that have Kerberos enabled are not supported.
Single-node ApsaraDB for HBase clusters are not supported.
ApsaraDB for HBase clusters that are deployed in the classic network are not supported due to network issues.
An asynchronous mode is used to synchronize incremental data based on write-ahead logging (WAL). Data that is imported through BulkLoad and data that is not written to WAL are not synchronized.
Log management in incremental synchronization
If log data is not consumed after you enable the incremental synchronization feature, the log data is retained for 48 hours by default. After the period expires, the subscription is automatically canceled and the retained data is automatically deleted.
Log data may fail to be consumed in the following scenarios: Your LTS cluster is released while the task is still running, the synchronization task is suspended, and the task is abnormally blocked.
Precautions
Before you migrate data, make sure that the HDFS capacity of the destination cluster is sufficient. This helps you prevent the capacity from being exhausted during migration.
Before you submit an incremental synchronization task, we recommend that you modify the log retention period for the source cluster. You must reserve time for LTS to handle incremental synchronization errors. For example, you can change the hbase.master.logcleaner.ttl setting of hbase-site.xml to a value greater than 12 hours and restart the HBase Master.
You do not need to manually create tables in the destination cluster. LTS automatically creates tables in the same way as those in the source cluster. The automatically created tables in the destination cluster are partitioned in the same way as the tables in the source cluster. The partitioning scheme of a manually created table may be different from that of the source table. As a result, the manually created table may be frequently split or compacted after the migration process is complete. If the table stores a large amount of data, the entire process can take a long time.
If the source table has a coprocessor, ensure that the destination cluster contains the corresponding JAR package of the coprocessor when you create a destination table.
Before you begin
Check the network connectivity among the source cluster, the destination cluster, and LTS.
Add HBase and Lindorm data sources.
Log on to the LTS web UI.
Create a task
In the left-side navigation pane, choose Migration > Quick Migration.
Configure the parameters and click create to create a task.
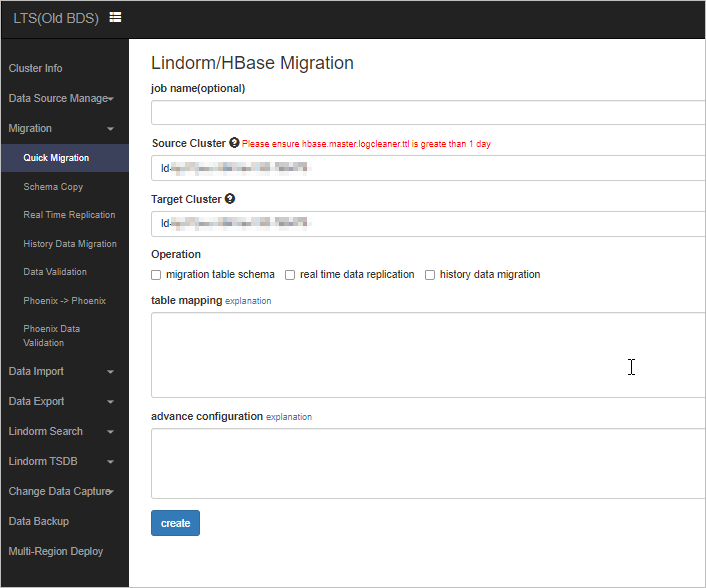
In the job name field, enter a task name. The task name can contain only letters and digits. This field can be left empty. By default, the task ID is used as the task name.
Configure the Source Cluster and Target Cluster parameters based on the on-screen instructions.
Select operations based on your requirements.
migration table schema: creates tables in the destination cluster. These tables have the same schema and partition information as the source tables. If a table already exists in the destination cluster, the data in this table is not migrated.
real time data replication: synchronizes real-time incremental data from the source cluster.
history data migration: physically migrates all the files at a file level.
In the table mapping field, enter table names. Each table name occupies a line.
The advance configuration field can be left empty.
View a task
In the left-side navigation pane, choose Migration > Quick Migration to view the task that you created.
View the details of the task
In the left-side navigation pane, choose Migration > Quick Migration.
On the page that appears, click the name of the task that you want to view. View the execution status of the task.
Perform a switchover
Wait until the full migration task is complete and the latency of incremental synchronization becomes as low as several seconds or hundreds of milliseconds.
Enable LTS data sampling and verification. When you sample and verify large tables, make sure that the sampling ratio is appropriate to prevent the online business from being affected.
Verify your business.
Perform a switchover on your business.