This topic describes how to archive incremental data of HBase clusters to MaxCompute.
Usage notes
This feature is no longer available for Lindorm Tunnel Service (LTS) instances that are purchased after June 16, 2023. If your LTS instance is purchased before June 16, 2023, you can still use this feature.
Prerequisites
LTS is activated.
An HBase data source is added.
A MaxCompute data source is added.
Supported versions
Self-managed HBase V1.x and HBase V2.x
Elastic MapReduce (EMR) HBase
ApsaraDB for HBase Standard Edition, ApsaraDB for HBase Performance-enhanced Edition that runs in cluster mode, and Lindorm
Limits
Real-time data is archived based on HBase logs. Therefore, data that is imported by using bulk loading cannot be exported.
Lifecycle of log data
If log data is not consumed after you enable the archiving feature, the log data is retained for 48 hours by default. After the period expires, the subscription is automatically canceled and the retained data is automatically deleted.
If you release an LTS instance without stopping the synchronization tasks that are created on the LTS instance, the synchronization tasks are suspended and data is not consumed.
Submit an archiving task
Log on to the LTS web UI. In the left-side navigation pane, choose Data Export > Incremental Archive to MaxCompute.
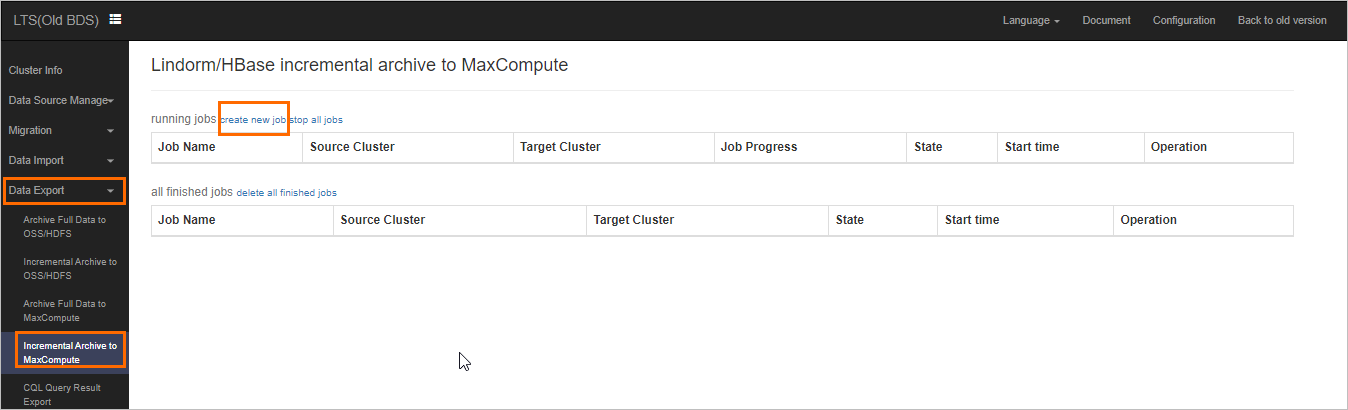
Click create new job. On the page that appears, select a source HBase cluster and a destination MaxCompute cluster, and specify the HBase table that you want to export.
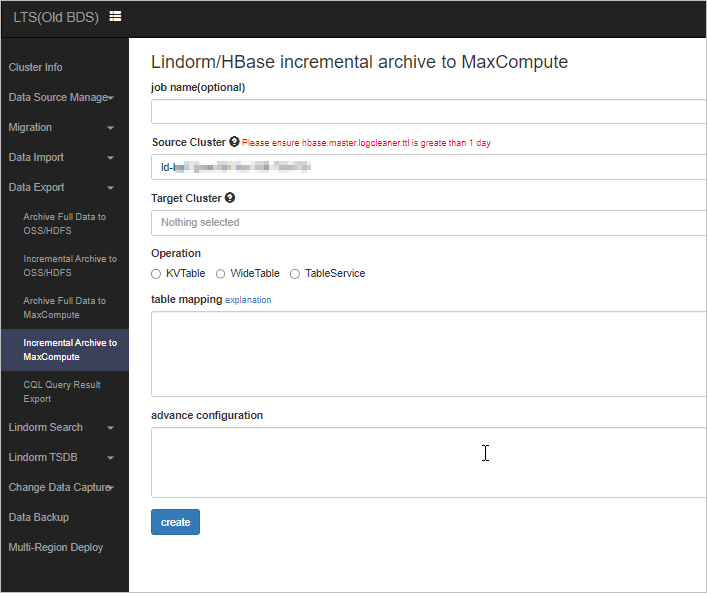 The preceding figure provides an example on how to archive real-time data from the HBase table wal-test to MaxCompute.
The preceding figure provides an example on how to archive real-time data from the HBase table wal-test to MaxCompute.The columns to be archived are cf1:a, cf1:b, cf1:c, and cf1:d.
The mergeInterval parameter specifies the archiving interval in milliseconds. The default value is 86400000.
Specify the mergeStartAt parameter in the format of yyyyMMddHHmmss. The value in this example specifies 00:00, September 30, 2019 as the start time. You can specify a time in the past.
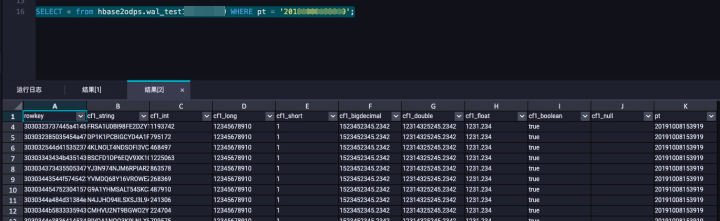
View the archiving progress of the table. The Real-time Synchronization Channel section shows the latency and start offset of the log synchronization tasks. The Table Merge section shows table merging tasks. After the tables are merged, you can query the new partitioned tables in MaxCompute.
Log on to the MaxCompute console to query the data.
Parameters
The following code provides an example of the format for exported tables:
hbaseTable/odpsTable {"cols": ["cf1:a|string", "cf1:b|int", "cf1:c|long", "cf1:d|short","cf1:e|decimal", "cf1:f|double","cf1:g|float","cf1:h|boolean","cf1:i"], "mergeInterval": 86400000, "mergeStartAt": "20191008100547"}
hbaseTable/odpsTable {"cols": ["cf1:a", "cf1:b", "cf1:c"], "mergeStartAt": "20191008000000"}
hbaseTable {"mergeEnabled": false} // No merge operation is performed on the tables.An exported table contains three parts: hbaseTable, odpsTable, and tbConf.
hbaseTable: the source HBase table.
odpsTable: the name of the destination MaxCompute table. This parameter is optional. By default, the name of the MaxCompute table is the same as the name of the source HBase table. The MaxCompute table name cannot contain periods (.) or hyphens (-). If you use periods (.) or hyphens (-), they are converted into underscores (_).
tbConf: the archiving actions of the table. The following table lists the supported parameters.
Parameter | Description | Example |
cols | Specifies the columns that you want to export and the data types of the columns. By default, data is converted into the HexString format. | "cols": ["cf1:a", "cf1:b", "cf1:c"] |
mergeEnabled | Specifies whether to convert key-value (KV) tables into wide tables. Default value: true. | "mergeEnabled": false |
mergeStartAt | The start time for table merging. You can specify a time in the past in the yyyyMMddHHmmss format. | "mergeStartAt": "20191008000000" |
mergeInterval | The interval at which table merging tasks are performed. Unit: milliseconds. The default value is 86400000. If the default value is used, data is archived on a daily basis. | "mergeInterval": 86400000 |