This topic is intended for Container Service for Kubernetes (ACK) dedicated clusters that have cGPU Basic Edition installed. This topic describes how to troubleshoot GPU sharing and scheduling errors after you upgrade cGPU Basic Edition in an ACK dedicated cluster to cGPU Professional Edition.
Issue
After you upgrade cGPU Basic Edition in an ACK dedicated cluster to cGPU Professional Edition, the extender configuration related to ack-cgpu in kube-scheduler is lost. As a result, you cannot share or schedule GPU resources in the cluster.
Cause
When the system upgrades cGPU Basic Edition to cGPU Professional Edition, the current kube-scheduler configuration is overwritten by the default configuration. This causes the loss of the extender configuration.
Solution
To troubleshoot this issue, perform the following steps:
Step 1: Check the extender configuration
Remotely log on to each control plane.
Check whether
scheduler-extender-config.jsonexists in the/etc/kubernetes/manifests/kube-scheduler.yamlfile of each control plane, as shown in the following figure.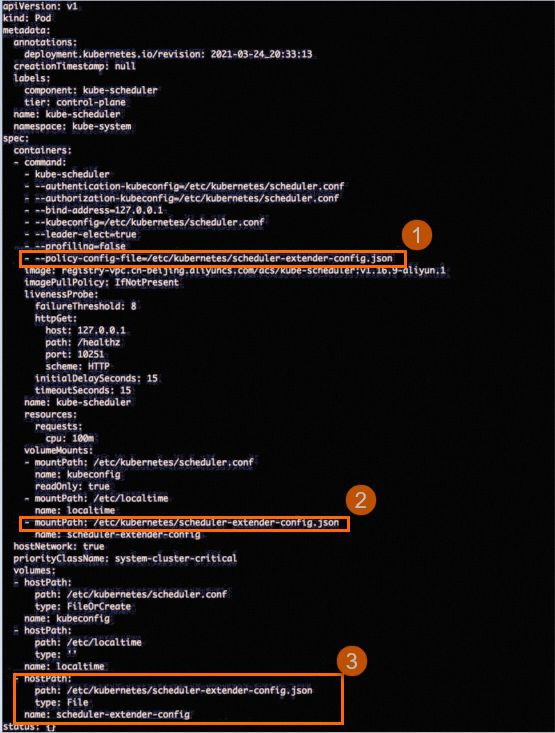
If scheduler-extender-config.json does not exist, proceed to Step 2. If scheduler-extender-config.json exists, the extender configuration is not lost and no repair is needed. In this case, join DingTalk group 30421250 to request technical support.
Step 2: Run the repair program
Remotely log on to a control plane.
Run the following command to download the repair tool:
sudo wget http://aliacs-k8s-cn-beijing.oss-cn-beijing.aliyuncs.com/gpushare/extender-config-update-linux -O /usr/local/bin/extender-config-updateRun the following command to make the repair tool executable:
sudo chmod +x /usr/local/bin/extender-config-updateRun the following command to launch the repair tool:
sudo extender-config-updateRun the following command to query the status of kube-scheduler. Check whether kube-scheduler is restarted and running.
kubectl get po -n kube-system -l component=kube-schedulerIn the following output, 14s is displayed in the AGE column. This indicates that kube-scheduler is restarted and repaired.
NAME READY STATUS RESTARTS AGE kube-scheduler-cn-beijing.192.168.8.37 1/1 Running 0 14s kube-scheduler-cn-beijing.192.168.8.38 1/1 Running 0 14s kube-scheduler-cn-beijing.192.168.8.39 1/1 Running 0 14sRefer to Step 1: Check the extender configuration to verify that the extender configuration in the
kube-scheduler.yamlfile is restored. Then, proceed to Step 3.
Step 3: Verify the result
Remotely log on to a control plane.
Create a file named /tmp/cgpu-test.yaml for verification.
Add the following content to the
/tmp/cgpu-test.yamlfile:apiVersion: batch/v1 kind: Job metadata: name: tensorflow-mnist spec: parallelism: 1 template: metadata: labels: app: tensorflow-mnist spec: containers: - name: tensorflow-mnist image: registry.cn-beijing.aliyuncs.com/ai-samples/gpushare-sample:tensorflow-1.5 command: - python - tensorflow-sample-code/tfjob/docker/mnist/main.py - --max_steps=100000 - --data_dir=tensorflow-sample-code/data resources: limits: aliyun.com/gpu-mem: 3 # Request 3 GiB of GPU memory. workingDir: /root restartPolicy: NeverRun the following command to create a job:
kubectl create -f /tmp/cgpu-test.yamlRun the following command to check whether the pod is running:
kubectl get po -l app=tensorflow-mnistExpected output:
NAME READY STATUS RESTARTS AGE tensorflow-mnist-5htxh 1/1 Running 0 4m32sRun the following command to check whether the actual amount of GPU memory allocated to the pod is the same as the configuration in the /tmp/cgpu-test.yaml file.
kubectl logs tensorflow-mnist-5htxh | grep "totalMemory"Expected output:
totalMemory: 3.15GiB freeMemory: 2.85GiBRun the following command to check whether the actual amount of GPU memory allocated to the pod is the same as the configuration in the /tmp/cgpu-test.yaml file.
kubectl exec -ti tensorflow-mnist-5htxh -- nvidia-smiThe following output shows that the actual amount of GPU memory allocated to the pod is 3,226 MiB. The amount is the same as the configuration in the /tmp/cgpu-test.yaml file. If GPU resources cannot be shared or scheduled, the actual amount of GPU memory allocated to the pod is equal to the total GPU memory provided by the host.
Mon Apr 13 11:52:25 2020 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 418.87.01 Driver Version: 418.87.01 CUDA Version: 10.1 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | |===============================+======================+======================| | 0 Tesla V100-SXM2... On | 00000000:00:07.0 Off | 0 | | N/A 33C P0 56W / 300W | 629MiB / 3226MiB | 1% Default | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: GPU Memory | | GPU PID Type Process name Usage | |=============================================================================| +-----------------------------------------------------------------------------+