Configure data sharding for collections in a sharded cluster instance to fully utilize the storage space and computing performance of shard nodes.
Background information
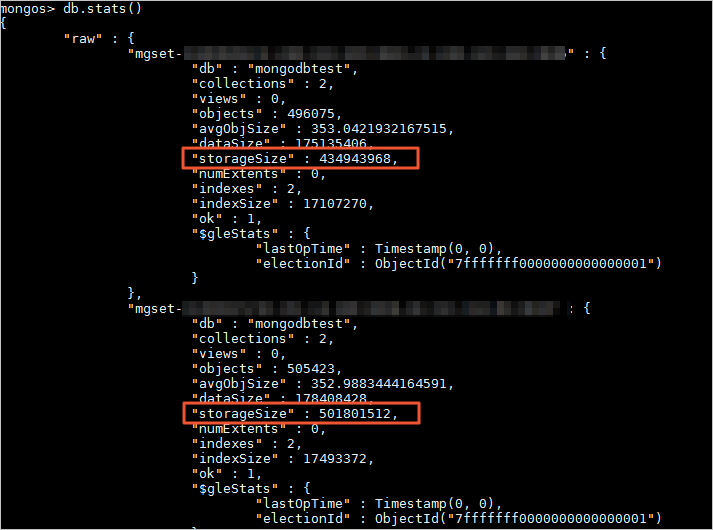
If a collection is not sharded, all its data is stored on a single shard node. This prevents other shard nodes from being fully utilized for storage and computing.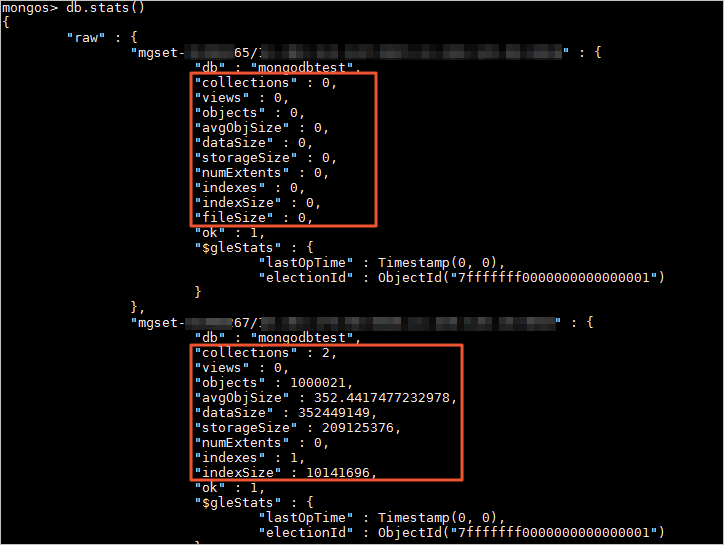
Prerequisites
The instance is a sharded cluster instance.
Usage notes
MongoDB's ability to modify a shard key has improved across different versions:
Before version 4.4: After a shard key is set, it cannot be modified or deleted.
Starting from version 4.4: You can use the refineCollectionShardKey command to refine the shard key by adding a suffix field.
Starting from version 5.0: The reshardCollection command was introduced. This command lets you completely change the shard key of a collection.
After you configure data sharding, the balancer splits data that meets the criteria. Because this operation consumes instance resources, you should perform it during off-peak hours.
NoteBefore you configure data sharding, you can set an active window for the balancer to ensure that the balancer runs during off-peak hours. For more information, see Set an active window for the balancer.
The choice of a shard key affects the performance of a sharded cluster instance. For more information about how to select a shard key, see How to select a shard key and Shard Keys.
Sharding strategies
Sharding strategy | Description | Scenario |
Range sharding | MongoDB divides data into chunks based on the range of shard key values. Each chunk contains data within a specific range.
| The shard key value is not monotonically increasing or decreasing. The shard key has high cardinality and low frequency. Range queries are required. |
Hashed sharding | MongoDB computes the hash of a single field's value to use as the index value. It then divides data into chunks based on the range of hash values.
| The shard key value is monotonically increasing or decreasing. The shard key has high cardinality and low frequency. Data writes need to be randomly distributed. Data reads are highly random. |
In addition to these two sharding strategies, you can also configure a compound shard key. For example, you can use a key with low cardinality and a monotonically increasing key. For more information, see How to select a shard key.
Procedure
This topic uses the `mongodbtest` database and the `customer` collection as an example.
Enable sharding for the database where the collection resides.
ImportantIf your instance runs MongoDB 6.0 or later, you can skip this step. For more information, see sh.enableSharding().
sh.enableSharding("<database>")Parameter description:
<database>is the name of the database.Example:
sh.enableSharding("mongodbtest")NoteYou can run the
sh.status()command to view the sharding status.Create an index on the shard key field.
db.<collection>.createIndex(<keyPatterns>,<options>)Parameter descriptions:
<collection>: The name of the collection.<keyPatterns>: The field for indexing and the index type.Common index types are as follows:
1: Creates an ascending index.
-1: Creates a descending index.
"hashed": Creates a hashed index.
<options>: Optional parameters. For more information, see db.collection.createIndex(). This parameter is not used in this example.
The following example shows how to create an ascending index:
db.customer.createIndex({name:1})Create a hash index:
db.customer.createIndex({name:"hashed"})Configure data sharding for the collection.
sh.shardCollection("<database>.<collection>",{ "<key>":<value> } )Parameter descriptions:
<database>: The name of the database.<collection>: The name of the collection.<key>: The shard key. MongoDB shards data based on the values of this key.<value>1: Specifies range sharding. This strategy supports efficient range queries based on the shard key.
"hashed": Specifies hashed sharding. This strategy distributes writes evenly across shard nodes.
Example of configuring range sharding:
sh.shardCollection("mongodbtest.customer",{"name":1})Example of configuring hashed sharding:
sh.shardCollection("mongodbtest.customer",{"name":"hashed"})
What to do next
After the instance has been running and data has been written for a period of time, you can run the sh.status() command in the mongo shell to view the data distribution across shard nodes.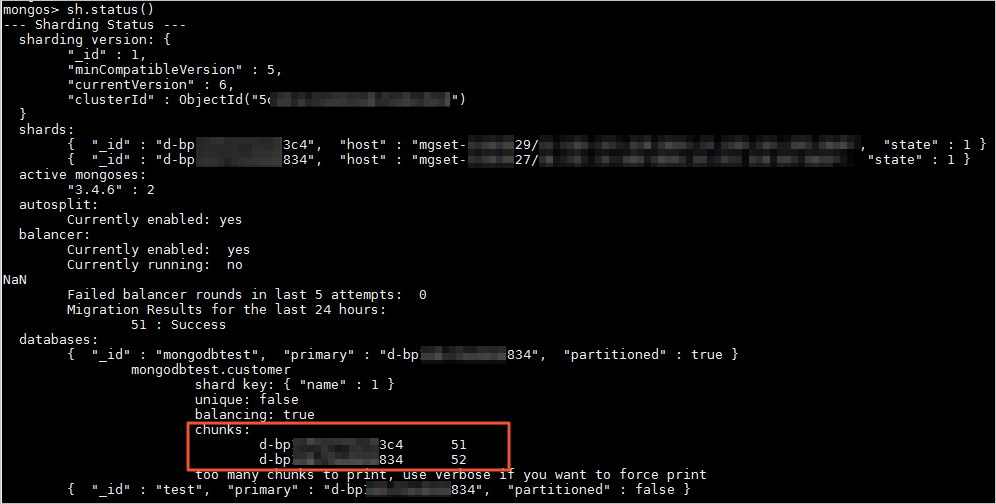
You can also run the db.stats() command to view the data storage of the database on each shard node.