When you configure scheduling dependencies, ancestor and descendant nodes are associated by output names. This topic describes how to manage the input and output on which a node depends for scheduling.
Configure the node input
- Use the automatic parsing feature to parse node dependencies from the code.
- Enter the output name of the parent node to manually configure node dependencies.
If you use the automatic parsing feature to configure the node input, the dependencies that are automatically parsed may be invalid. To determine whether a parsed dependency is valid, find the parsed parent node and check whether a value is displayed in the Parent Node ID column.
A dependency is a logical relationship between two nodes. You can configure valid dependencies only for nodes that actually exist.
Invalid dependencies
- The parent node does not exist.
- The output name of the parent node does not exist.
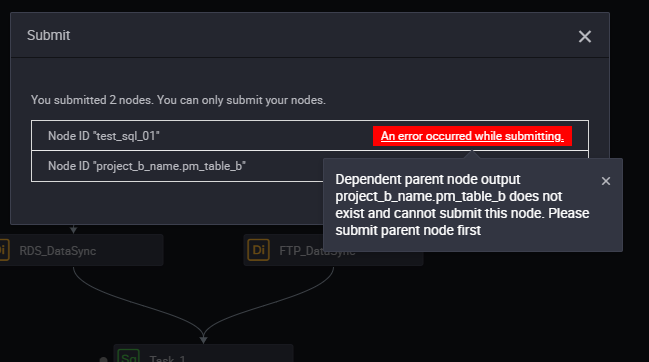
Usually, the dependency is invalid because the output name of the parsed parent node does not exist. Assume that the project_b_name.pm_table_b table has no output, or the output of the table is incorrectly configured. The dependency is invalid.
- Check whether the table has an output.
- If the table has an output, add the output to the Parent Nodes section for the node that depends on the output.
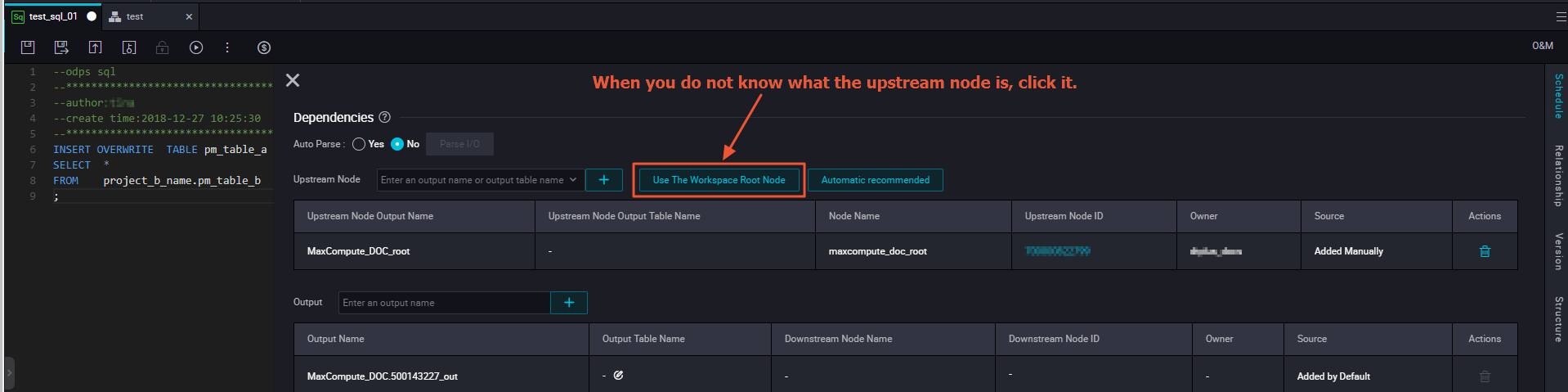
Assume that the output name of Node A is A1, and Node B depends on Node A. In this case, enter A1 in the search box, and then click the plus sign (+) next to the search box.
Configure a parent node
Configure the node output
You can use the same name for the name, the output name, and the output table name of a node to efficiently configure the node output.
- You can know a specific table on which the node performs operations.
- You can know the impact that is caused when the node fails to be run.
- Assume that you use the automatic parsing feature to configure the node output. If the name, output name, and output table name of the node are the same, you can improve the precision of automatic parsing.
Automatic parsing
Auto Parse: Node dependencies are automatically parsed from the code.
The principle of auto parsing: Only table names can be obtained from the code. The automatic parsing feature is used to parse output nodes based on the table names.
INSERT OVERWRITE TABLE pm_table_a SELECT * FROM project_b_name.pm_table_b ;pm_table_b table in the project_b_name workspace. The output of the current node is the pm_table_a table. The output name of the parent node is project_b_name.pm_table_b. The output name of the current node is project_name.pm_table_a. In this example, Workspace test_pm_01 is used.
- If you do not want to parse node dependencies from the code, set the Auto Parse parameter to No.
- The code may contain many temporary tables whose names start with t_. Temporary tables are not involved in the parsing of a scheduling dependency. You can specify the prefix of temporary table names on the Workspace Settings tab.
- If a table in the code of a node is both an output table and a referenced table on which another table depends, the table is parsed only as an output table.
- If a table in the code of a node is used as an output table or a referenced table multiple times, only one scheduling dependency is parsed.
Delete table input and output
Static tables are often used for data analytics. If you import data from local files to static tables, these tables do not have outputs.
When you configure a dependency, you must prevent the static table from being parsed as the input of a node. If the name of a static table does not start with t_, it is not recognized as a temporary table. In this case, delete the table input.
Right-click the table name in the code and select Delete Input.
If you upgrade the DataWorks service from V1.0 to V2.0, the default output name of
the migrated node is in the format of Workspace name. Node name.
Usage notes
After you configure dependencies and commit the node, a dialog box appears. If the dependencies you specified are different from those obtained based on lineage analysis, the dialog box contains a check box that asks you to confirm whether to commit the node.
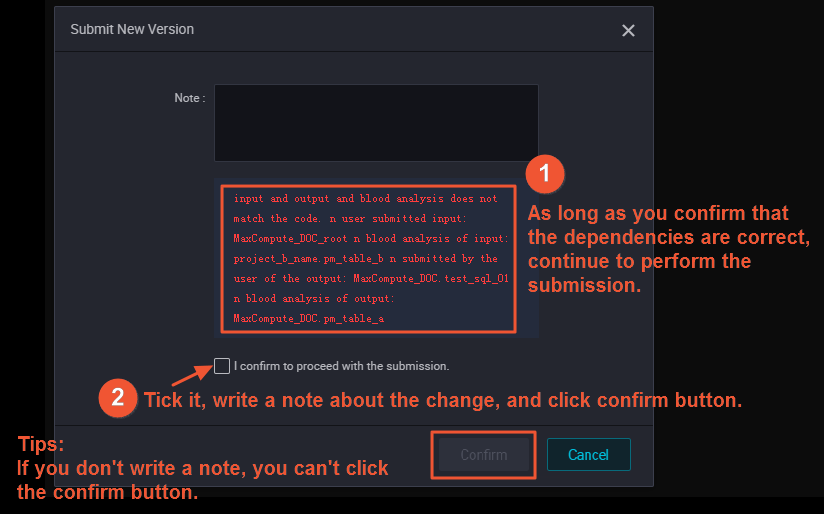
If you are sure that the dependencies are correct, select I confirm to proceed with the commission and click OK.