The RESTful API of the short speech recognition service allows you to use the POST method to upload an audio file whose duration is up to 1 minute. The server returns the recognition result in JSON format in a response. You must make sure that the connection is not interrupted before the recognition result is returned.
Background information
Supports pulse-code modulation (PCM) encoded 16-bit mono audio files.
Supports the audio sampling rates of 8,000 Hz and 16,000 Hz.
Allows you to specify whether to add punctuation marks during post-processing and whether to convert Chinese numbers to Arabic numbers.
Allows you to configure hotwords and customize linguistic models in the Intelligent Speech Interaction console.
Supports multiple languages. You can specify the language to be recognized by selecting a model when you modify a project in the Intelligent Speech Interaction console. For more information, see Manage projects.
Prerequisites
A project is created in the Intelligent Speech Interaction console and the appkey of the project is obtained. For more information, see Create a project.
An access token that is obtained. For more information, see Obtain an access token.
Interaction process
The client sends an HTTP RESTful POST request with audio data to the server. Then, the server returns an HTTP response with the recognition result.
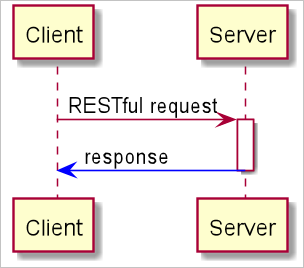
The server adds the task_id field to the response if the server encounters an error. The task_id field indicates the ID of the recognition task. You can record the task ID and submit a ticket to report the task ID and error message.
Service addresses
Type | Description | URL | Host |
Access from external networks | You can use the URL to access the short speech recognition service from all clients over the Internet. | http://nls-gateway-ap-southeast-1.aliyuncs.com/stream/v1/asr | nls-gateway-ap-southeast-1.aliyuncs.com |
The following section describes how to access the short speech recognition service over the Internet.
Upload an audio file
The following example shows an HTTP request that is used to call the short speech recognition RESTful API:
POST /stream/v1/asr?appkey=23f5****&format=pcm&sample_rate=16000&enable_punctuation_prediction=true&enable_inverse_text_normalization=true HTTP/1.1
X-NLS-Token: 450372e4279bcc2b3c793****
Content-type: application/octet-stream
Content-Length: 94616
Host: nls-gateway-ap-southeast-1.aliyuncs.com
[audio data]A complete request to call the short speech recognition RESTful API must contain the following elements: an HTTP request line, an HTTP request header, and an HTTP request body.
HTTP request line
The HTTP request line contains a URL and request parameters, as shown in the following example:
http://nls-gateway-ap-southeast-1.aliyuncs.com/stream/v1/asr?appkey=Yu1******uncS&format=pcm&sample_rate=16000&vocabulary_id=a17******d6b&customization_id=abd******ed8&enable_punctuation_prediction=true&enable_inverse_text_normalization=true&enable_voice_detection=trueURL
Protocol
URL
Method
HTTP/1.1
nls-gateway-ap-southeast-1.aliyuncs.com/stream/v1/asr
POST
Request parameters
Parameter
Type
Required
Description
appkey
String
Yes
The appkey of your project.
format
String
No
The audio encoding format. Valid values: pcm and opus. Default value: pcm.
sample_rate
Integer
No
The audio sampling rate. Valid values: 16,000 and 8,000. Default value: 16,000.
vocabulary_id
String
No
The ID of your hotword list. This parameter is not specified by default.
customization_id
String
No
The ID of your custom linguistic model. This parameter is not specified by default.
enable_punctuation_prediction
Boolean
No
Specifies whether to add punctuation marks during post-processing. Valid values: true and false. Default value: false.
enable_inverse_text_normalization
Boolean
No
Specifies whether to enable inverse text normalization (ITN) during post-processing. Valid values: true and false. Default value: false.
enable_voice_detection
Boolean
No
Specifies whether to enable voice detection. Valid values: true and false. Default value: false.
HTTP request header
The HTTP request header consists of key-value pairs. Each key-value pair is a field that occupies a line. The key and the value in each pair are separated by a colon (:). The following table describes the fields of the HTTP request header.
Field
Type
Required
Description
X-NLS-Token
String
Yes
The token that is used for service authentication.
Content-Type
String
Yes
The content type. The value is application/octet-stream, which indicates that the data in the HTTP request body is a binary stream.
Content-Length
long
Yes
The length of the data in the HTTP request body. The length of the data is the same as the length of the audio file.
Host
String
Yes
The domain name of the server to which the HTTP request is sent. The value is nls-gateway-ap-southeast-1.aliyuncs.com.
The HTTP request body.
The HTTP request body contains binary audio data. Therefore, you must set the
Content-Typeparameter in the HTTP request header toapplication/octet-stream.
Sample responses
After the client sends an HTTP request with audio data, the server returns a response with the recognition result in JSON format.
Success response
{ "task_id": "cf7b0c5339244ee29cd4e43fb97f****", "result": "Weather in Beijing", "status":20000000, "message":"SUCCESS" }Error response
The following example indicates an authentication token error:
{ "task_id": "8bae3613dfc54ebfa811a17d8a7a****", "result": "", "status": 40000001, "message": "Gateway:ACCESS_DENIED:The token 'c0c1e860f3*******de8091c68a' is invalid!" }Response parameters
Parameter
Type
Description
task_id
String
The task ID that must be 32 characters in length. You can record the task ID for troubleshooting.
result
String
The speech recognition result.
status
Integer
The status code.
message
String
The description of the status code.
Status codes
Status code | Description | Solution |
20000000 | The request is successful. | None. |
40000000 | A client error occurred. This is the default status code for client errors. | Troubleshoot the error based on the error message or submit a ticket. |
40000001 | The client fails to pass the authentication. | Check whether the token that is used by the client is valid or expired. |
40000002 | The request is invalid. | Check whether the request that is sent by the client meets the requirements. |
40000003 | One or more parameters are invalid. | Check whether the parameter values are valid. |
40000004 | The client timed out. | Check whether the client did not send data to the server for a long period of time. |
40000005 | The number of requests exceeds the upper limit. | Check whether the number of concurrent connections or queries per second (QPS) value exceeds the upper limit. |
41010101 | The sampling rate of the uploaded audio file is not supported. | Check whether the sampling rate (8,000 or 16,000) that is specified in the code matches the sampling rate (8k or 16k) of the model to which the appkey is bound in the Intelligent Speech Interaction console. |
50000000 | A server error occurred. This is the default status code for server errors. | If the status code is returned a few times, ignore it. If the status code is returned multiple times, submit a ticket. |
50000001 | An internal gRPC call error occurred. | If the status code is returned a few times, ignore it. If the status code is returned multiple times, submit a ticket. |
Quick test
This demo uses a .wav audio file and a generic model. To use another audio file for the test, specify the audio coding format and sampling rate as required and select an appropriate model in the Intelligent Speech Interaction console.
You can run the following cURL command to test the short speech recognition RESTful API:
curl -X POST -H "X-NLS-Token: ${token}" http://nls-gateway-ap-southeast-1.aliyuncs.com/stream/v1/asr?appkey=${appkey} --data-binary @${audio_file}Example:
curl -X POST -H "X-NLS-Token: 4a036531cfdd****" http://nls-gateway-ap-southeast-1.aliyuncs.com/stream/v1/asr?appkey=tt43P2u**** --data-binary @./nls-sample-16k.wav
Demo for Java
Dependencies:
<dependency>
<groupId>com.squareup.okhttp3</groupId>
<artifactId>okhttp</artifactId>
<version>3.9.1</version>
</dependency>
<!-- http://mvnrepository.com/artifact/com.alibaba/fastjson -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.83</version>
</dependency>
Request and response:
import com.alibaba.fastjson.JSONPath;
import com.alibaba.nls.client.example.utils.HttpUtil;
import java.util.HashMap;
public class SpeechRecognizerRESTfulDemo {
private String accessToken;
private String appkey;
public SpeechRecognizerRESTfulDemo(String appkey, String token) {
this.appkey = appkey;
this.accessToken = token;
}
public void process(String fileName, String format, int sampleRate,
boolean enablePunctuationPrediction,
boolean enableInverseTextNormalization,
boolean enableVoiceDetection) {
/**
* Configure an HTTP RESTful POST request:
* 1. Specify the HTTP protocol.
* 2. Set the domain name of the short speech recognition service to nls-gateway-ap-southeast-1.aliyuncs.com.
* 3. Set the request path to /stream/v1/asr for short speech recognition API requests.
* 4. Configure the following required request parameters: appkey, format, and sample_rate.
* 5. Configure the following optional request parameters: enable_punctuation_prediction, enable_inverse_text_normalization, and enable_voice_detection.
*/
String url = "http://nls-gateway-ap-southeast-1.aliyuncs.com/stream/v1/asr";
String request = url;
request = request + "?appkey=" + appkey;
request = request + "&format=" + format;
request = request + "&sample_rate=" + sampleRate;
if (enablePunctuationPrediction) {
request = request + "&enable_punctuation_prediction=" + true;
}
if (enableInverseTextNormalization) {
request = request + "&enable_inverse_text_normalization=" + true;
}
if (enableVoiceDetection) {
request = request + "&enable_voice_detection=" + true;
}
System.out.println("Request: " + request);
/**
* Configure the HTTP request header:
* 1. Configure authentication parameters.
* 2. Set the Content-Type parameter to application/octet-stream.
*/
HashMap<String, String> headers = new HashMap<String, String>();
headers.put("X-NLS-Token", this.accessToken);
headers.put("Content-Type", "application/octet-stream");
/**
* Send the HTTP POST request and process the response that is returned by the server.
*/
String response = HttpUtil.sendPostFile(request, headers, fileName);
if (response != null) {
System.out.println("Response: " + response);
String result = JSONPath.read(response, "result").toString();
System.out.println("Recognition result:" + result);
}
else {
System.err.println("Recognition failed.");
}
}
public static void main(String[] args) {
if (args.length < 2) {
System.err.println("SpeechRecognizerRESTfulDemo need params: <token> <app-key>");
System.exit(-1);
}
String token = args[0];
String appkey = args[1];
SpeechRecognizerRESTfulDemo demo = new SpeechRecognizerRESTfulDemo(appkey, token);
String fileName = SpeechRecognizerRESTfulDemo.class.getClassLoader().getResource("./nls-sample-16k.wav").getPath();
String format = "pcm";
int sampleRate = 16000;
boolean enablePunctuationPrediction = true;
boolean enableInverseTextNormalization = true;
boolean enableVoiceDetection = false;
demo.process(fileName, format, sampleRate, enablePunctuationPrediction, enableInverseTextNormalization, enableVoiceDetection);
}
}
HttpUtils class:
import okhttp3.*;
import java.io.File;
import java.io.IOException;
import java.net.SocketTimeoutException;
import java.util.HashMap;
import java.util.Map;
import java.util.concurrent.TimeUnit;
public class HttpUtil {
private static String getResponseWithTimeout(Request q) {
String ret = null;
OkHttpClient.Builder httpBuilder = new OkHttpClient.Builder();
OkHttpClient client = httpBuilder.connectTimeout(10, TimeUnit.SECONDS)
.readTimeout(60, TimeUnit.SECONDS)
.writeTimeout(60, TimeUnit.SECONDS)
.build();
try {
Response s = client.newCall(q).execute();
ret = s.body().string();
s.close();
} catch (SocketTimeoutException e) {
ret = null;
System.err.println("get result timeout");
} catch (IOException e) {
System.err.println("get result error " + e.getMessage());
}
return ret;
}
public static String sendPostFile(String url, HashMap<String, String> headers, String fileName) {
RequestBody body;
File file = new File(fileName);
if (!file.isFile()) {
System.err.println("The filePath is not a file: " + fileName);
return null;
} else {
body = RequestBody.create(MediaType.parse("application/octet-stream"), file);
}
Headers.Builder hb = new Headers.Builder();
if (headers != null && !headers.isEmpty()) {
for (Map.Entry<String, String> entry : headers.entrySet()) {
hb.add(entry.getKey(), entry.getValue());
}
}
Request request = new Request.Builder()
.url(url)
.headers(hb.build())
.post(body)
.build();
return getResponseWithTimeout(request);
}
public static String sendPostData(String url, HashMap<String, String> headers, byte[] data) {
RequestBody body;
if (data.length == 0) {
System.err.println("The send data is empty.");
return null;
} else {
body = RequestBody.create(MediaType.parse("application/octet-stream"), data);
}
Headers.Builder hb = new Headers.Builder();
if (headers != null && !headers.isEmpty()) {
for (Map.Entry<String, String> entry : headers.entrySet()) {
hb.add(entry.getKey(), entry.getValue());
}
}
Request request = new Request.Builder()
.url(url)
.headers(hb.build())
.post(body)
.build();
return getResponseWithTimeout(request);
}
}Demo for C++
The demo for C++ uses the third-party library cURL to process HTTP requests and responses. Download the cURL library and demo.
The following table describes the content in the downloaded ZIP file.
File name or folder name | Description |
CMakeLists.txt | The CMakeList file of the demo project. |
demo | The restfulAsrDemo.cpp file is the demo of the short speech recognition RESTful API. |
include | The curl folder is the header file directory of the cURL library. |
lib | The lib folder contains the dynamic library curl-7.60. You can select one of the following versions based on the operating system:
|
readme.txt | The description file. |
release.log | The release notes. |
version | The version number. |
build.sh | The demo compilation script. |
Compile and run the demo:
Assume that the demo is decompressed to the path/to directory. Run the following commands on the Linux terminal to compile and run the demo.
If the operating system supports CMake, run the following commands in sequence:
Make sure that CMake 2.4 or later is installed in the Linux terminal.
cd path/to/sdk/libtar -zxvpf linux.tar.gzcd path/to/sdk./build.shcd path/to/sdk/demo./restfulAsrDemo <your-token> <your-appkey>
If the operating system does not support CMake, run the following commands in sequence:
cd path/to/sdk/libtar -zxvpf linux.tar.gzcd path/to/sdk/demog++ -o restfulAsrDemo restfulAsrDemo.cpp -I path/to/sdk/include -L path/to/sdk/lib/linux -lssl -lcrypto -lcurl -D_GLIBCXX_USE_CXX11_ABI=0export LD_LIBRARY_PATH=path/to/sdk/lib/linux/./restfulAsrDemo <your-token> <your-appkey>
#include <iostream>
#include <string>
#include <fstream>
#include <sstream>
#include "curl/curl.h"
using namespace std;
#ifdef _WIN32
string UTF8ToGBK(const string& strUTF8) {
int len = MultiByteToWideChar(CP_UTF8, 0, strUTF8.c_str(), -1, NULL, 0);
unsigned short * wszGBK = new unsigned short[len + 1];
memset(wszGBK, 0, len * 2 + 2);
MultiByteToWideChar(CP_UTF8, 0, (char*)strUTF8.c_str(), -1, (wchar_t*)wszGBK, len);
len = WideCharToMultiByte(CP_ACP, 0, (wchar_t*)wszGBK, -1, NULL, 0, NULL, NULL);
char *szGBK = new char[len + 1];
memset(szGBK, 0, len + 1);
WideCharToMultiByte(CP_ACP, 0, (wchar_t*)wszGBK, -1, szGBK, len, NULL, NULL);
string strTemp(szGBK);
delete[] szGBK;
delete[] wszGBK;
return strTemp;
}
#endif
/**
* Configure the response callback function for HTTP requests that are sent to call the short speech recognition RESTful API.
* The recognition result is a JSON string.
*/
size_t responseCallback(void* ptr, size_t size, size_t nmemb, void* userData) {
string* srResult = (string*)userData;
size_t len = size * nmemb;
char *pBuf = (char*)ptr;
string response = string(pBuf, pBuf + len);
#ifdef _WIN32
response = UTF8ToGBK(response);
#endif
cout << "current result: " << response << endl;
*srResult += response;
cout << "total result: " << *srResult << endl;
return len;
}
int sendAsrRequest(const char* request, const char* token, const char* fileName, string* srResult) {
CURL* curl = NULL;
CURLcode res;
/**
* Read the audio file.
*/
ifstream fs;
fs.open(fileName, ios::out ios::binary);
if (!fs.is_open()) {
cerr << "The audio file is not exist!" << endl;
return -1;
}
stringstream buffer;
buffer << fs.rdbuf();
string audioData(buffer.str());
curl = curl_easy_init();
if (curl == NULL) {
return -1;
}
/**
* Configure the HTTP request line.
*/
curl_easy_setopt(curl, CURLOPT_CUSTOMREQUEST, "POST");
curl_easy_setopt(curl, CURLOPT_URL, request);
/**
* Configure the HTTP request header.
*/
struct curl_slist* headers = NULL;
// token
string X_NLS_Token = "X-NLS-Token:";
X_NLS_Token += token;
headers = curl_slist_append(headers, X_NLS_Token.c_str());
// Content-Type
headers = curl_slist_append(headers, "Content-Type:application/octet-stream");
// Content-Length
string content_Length = "Content-Length:";
ostringstream oss;
oss << content_Length << audioData.length();
content_Length = oss.str();
headers = curl_slist_append(headers, content_Length.c_str());
curl_easy_setopt(curl, CURLOPT_HTTPHEADER, headers);
/**
* Configure the HTTP request body.
*/
curl_easy_setopt(curl, CURLOPT_POSTFIELDS, audioData.c_str());
curl_easy_setopt(curl, CURLOPT_POSTFIELDSIZE, audioData.length());
/**
* Configure the response callback function for HTTP requests.
*/
curl_easy_setopt(curl, CURLOPT_WRITEFUNCTION, responseCallback);
curl_easy_setopt(curl, CURLOPT_WRITEDATA, srResult);
/**
* Send the HTTP request.
*/
res = curl_easy_perform(curl);
// Release resources.
curl_slist_free_all(headers);
curl_easy_cleanup(curl);
if (res != CURLE_OK) {
cerr << "curl_easy_perform failed: " << curl_easy_strerror(res) << endl;
return -1;
}
return 0;
}
int process(const char* request, const char* token, const char* fileName) {
// The demo is initialized only once.
curl_global_init(CURL_GLOBAL_ALL);
string srResult = "";
int ret = sendAsrRequest(request, token, fileName, &srResult);
curl_global_cleanup();
return ret;
}
int main(int argc, char* argv[]) {
if (argc < 3) {
cerr << "params is not valid. Usage: ./demo your_token your_appkey" << endl;
return -1;
}
string token = argv[1];
string appKey = argv[2];
string url = "http://nls-gateway-ap-southeast-1.aliyuncs.com/stream/v1/asr";
string format = "pcm";
int sampleRate = 16000;
bool enablePunctuationPrediction = true;
bool enableInverseTextNormalization = true;
bool enableVoiceDetection = false;
string fileName = "sample.pcm";
/**
* Configure the RESTful request parameters.
*/
ostringstream oss;
oss << url;
oss << "?appkey=" << appKey;
oss << "&format=" << format;
oss << "&sample_rate=" << sampleRate;
if (enablePunctuationPrediction) {
oss << "&enable_punctuation_prediction=" << "true";
}
if (enableInverseTextNormalization) {
oss << "&enable_inverse_text_normalization=" << "true";
}
if (enableVoiceDetection) {
oss << "&enable_voice_detection=" << "true";
}
string request = oss.str();
cout << "request: " << request << endl;
process(request.c_str(), token.c_str(), fileName.c_str());
return 0;
}
Demo for Python
Use the httplib module for Python 2.x, and use the http.client module for Python 3.x.
# -*- coding: UTF-8 -*-
# Import the httplib module for Python 2.x.
# import httplib
# Import the http.client module for Python 3.x.
import http.client
import json
def process(request, token, audioFile) :
# Read the audio file.
with open(audioFile, mode = 'rb') as f:
audioContent = f.read()
host = 'nls-gateway-ap-southeast-1.aliyuncs.com'
* Configure the HTTP request header.
httpHeaders = {
'X-NLS-Token': token,
'Content-type': 'application/octet-stream',
'Content-Length': len(audioContent)
}
# Use the httplib module for Python 2.x.
# conn = httplib.HTTPConnection(host)
# Use the http.client module for Python 3.x.
conn = http.client.HTTPConnection(host)
conn.request(method='POST', url=request, body=audioContent, headers=httpHeaders)
response = conn.getresponse()
print('Response status and response reason:')
print(response.status ,response.reason)
body = response.read()
try:
print('Recognize response is:')
body = json.loads(body)
print(body)
status = body['status']
if status == 20000000 :
result = body['result']
print('Recognize result: ' + result)
else :
print('Recognizer failed!')
except ValueError:
print('The response is not json format string')
conn.close()
appKey = 'Your appkey'
token = 'Your token'
# Specify the service request address.
url = 'http://nls-gateway-ap-southeast-1.aliyuncs.com/stream/v1/asr'
# Specify the audio file.
audioFile = '/path/to/nls-sample-16k.wav'
format = 'pcm'
sampleRate = 16000
enablePunctuationPrediction = True
enableInverseTextNormalization = True
enableVoiceDetection = False
# Configure the RESTful request parameters.
request = url + '?appkey=' + appKey
request = request + '&format=' + format
request = request + '&sample_rate=' + str(sampleRate)
if enablePunctuationPrediction :
request = request + '&enable_punctuation_prediction=' + 'true'
if enableInverseTextNormalization :
request = request + '&enable_inverse_text_normalization=' + 'true'
if enableVoiceDetection :
request = request + '&enable_voice_detection=' + 'true'
print('Request: ' + request)
process(request, token, audioFile)
Demo for PHP
The PHP demo uses cURL functions. Make sure that you have installed a PHP version later than 4.0.2 and cURL extensions.
<?php
function process($token, $request, $audioFile) {
/**
* Read the audio file.
*/
$audioContent = file_get_contents($audioFile);
if ($audioContent == FALSE) {
print "The audio file is not exist!\n";
return;
}
$curl = curl_init();
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($curl, CURLOPT_TIMEOUT, 120);
/**
* Configure the HTTP request line.
*/
curl_setopt($curl, CURLOPT_URL, $request);
curl_setopt($curl, CURLOPT_POST,TRUE);
/**
* Configure the HTTP request header.
*/
$contentType = "application/octet-stream";
$contentLength = strlen($audioContent);
$headers = array(
"X-NLS-Token:" . $token,
"Content-type:" . $contentType,
"Content-Length:" . strval($contentLength)
);
curl_setopt($curl, CURLOPT_HTTPHEADER, $headers);
/**
* Configure the HTTP request body.
*/
curl_setopt($curl, CURLOPT_POSTFIELDS, $audioContent);
curl_setopt($curl, CURLOPT_NOBODY, FALSE);
/**
* Send the HTTP request.
*/
$returnData = curl_exec($curl);
curl_close($curl);
if ($returnData == FALSE) {
print "curl_exec failed!\n";
return;
}
print $returnData . "\n";
$resultArr = json_decode($returnData, true);
$status = $resultArr["status"];
if ($status == 20000000) {
$result = $resultArr["result"];
print "The audio file recognized result: " . $result . "\n";
}
else {
print "The audio file recognized failed.\n";
}
}
$appkey = "Your appkey";
$token = 'Your token';
$url = "http://nls-gateway-ap-southeast-1.aliyuncs.com/stream/v1/asr";
$audioFile = "/path/to/nls-sample-16k.wav";
$format = "pcm";
$sampleRate = 16000;
$enablePunctuationPrediction = TRUE;
$enableInverseTextNormalization = TRUE;
$enableVoiceDetection = FALSE;
/**
* Configure the RESTful request parameters.
*/
$request = $url;
$request = $request . "?appkey=" . $appkey;
$request = $request . "&format=" . $format;
$request = $request . "&sample_rate=" . strval($sampleRate);
if ($enablePunctuationPrediction) {
$request = $request . "&enable_punctuation_prediction=" . "true";
}
if ($enableInverseTextNormalization) {
$request = $request . "&enable_inverse_text_normalization=" . "true";
}
if ($enableVoiceDetection) {
$request = $request . "&enable_voice_detection=" . "true";
}
print "Request: " . $request . "\n";
process($token, $request, $audioFile);
?>
Demo for Node.js
To install the request dependencies, run the npm install request --save command in the directory of the demo.
const request = require('request');
const fs = require('fs');
function callback(error, response, body) {
if (error != null) {
console.log(error);
}
else {
console.log('The audio file recognized result:');
console.log(body);
if (response.statusCode == 200) {
body = JSON.parse(body);
if (body.status == 20000000) {
console.log('result: ' + body.result);
console.log('The audio file recognized succeed!');
} else {
console.log('The audio file recognized failed!');
}
} else {
console.log('The audio file recognized failed, http code: ' + response.statusCode);
}
}
}
function process(requestUrl, token, audioFile) {
/**
* Read the audio file.
*/
var audioContent = null;
try {
audioContent = fs.readFileSync(audioFile);
} catch(error) {
if (error.code == 'ENOENT') {
console.log('The audio file is not exist!');
}
return;
}
/**
* Configure the HTTP request header.
*/
var httpHeaders = {
'X-NLS-Token': token,
'Content-type': 'application/octet-stream',
'Content-Length': audioContent.length
};
var options = {
url: requestUrl,
method: 'POST',
headers: httpHeaders,
body: audioContent
};
request(options, callback);
}
var appkey = 'Your appkey';
var token = 'Your token';
var url = 'http://nls-gateway-ap-southeast-1.aliyuncs.com/stream/v1/asr';
var audioFile = '/path/to/nls-sample-16k.wav';
var format = 'pcm';
var sampleRate = '16000';
var enablePunctuationPrediction = true;
var enableInverseTextNormalization = true;
var enableVoiceDetection = false;
/**
* Configure the RESTful request parameters.
*/
var requestUrl = url;
requestUrl = requestUrl + '?appkey=' + appkey;
requestUrl = requestUrl + '&format=' + format;
requestUrl = requestUrl + '&sample_rate=' + sampleRate;
if (enablePunctuationPrediction) {
requestUrl = requestUrl + '&enable_punctuation_prediction=' + 'true';
}
if (enableInverseTextNormalization) {
requestUrl = requestUrl + '&enable_inverse_text_normalization=' + 'true';
}
if (enableVoiceDetection) {
requestUrl = requestUrl + '&enable_voice_detection=' + 'true';
}
process(requestUrl, token, audioFile);
Demo for .NET
The demo relies on System.Net.Http and Newtonsoft.Json.Linq.
using System;
using System.Net.Http;
using System.IO;
using Newtonsoft.Json.Linq;
namespace RESTfulAPI
{
class SpeechRecognizerRESTfulDemo
{
private string token;
private string appkey;
public SpeechRecognizerRESTfulDemo(string appkey, string token)
{
this.appkey = appkey;
this.token = token;
}
public void process(string fileName, string format, int sampleRate,
bool enablePunctuationPrediction,
bool enableInverseTextNormalization,
bool enableVoiceDetection)
{
/**
* Configure an HTTP REST POST request.
* 1. Specify the HTTP protocol.
* 2. Set the domain name of the short speech recognition service to nls-gateway-ap-southeast-1.aliyuncs.com.
* 3. Set the request path to /stream/v1/asr for short speech recognition API requests.
* 4. Configure the following required request parameters: appkey, format, and sample_rate.
* 5. Configure the following optional request parameters: enable_punctuation_prediction, enable_inverse_text_normalization, and enable_voice_detection.
*/
string url = "http://nls-gateway-ap-southeast-1.aliyuncs.com/stream/v1/asr";
url = url + "?appkey=" + appkey;
url = url + "&format=" + format;
url = url + "&sample_rate=" + sampleRate;
if (enablePunctuationPrediction)
{
url = url + "&enable_punctuation_prediction=" + true;
}
if (enableInverseTextNormalization)
{
url = url + "&enable_inverse_text_normalization=" + true;
}
if (enableVoiceDetection)
{
url = url + "&enable_voice_detection=" + true;
}
System.Console.WriteLine("URL: " + url);
HttpClient client = new HttpClient();
/**
* Configure the HTTP request header.
* Configure authentication parameters.
*/
client.DefaultRequestHeaders.Add("X-NLS-Token", token);
if (!File.Exists(fileName))
{
System.Console.WriteLine("The audio file dose not exist");
return;
}
byte[] audioData = File.ReadAllBytes(fileName);
/**
* Configure the HTTP request Body.
* The binary data of the audio file.
* Set the Content-Type parameter to application/octet-stream.
*/
ByteArrayContent content = new ByteArrayContent(audioData);
content.Headers.Add("Content-Type", "application/octet-stream");
/**
* Send the HTTP POST request and process the response that is returned by the server.
*/
HttpResponseMessage response = client.PostAsync(url, content).Result;
string responseBodyAsText = response.Content.ReadAsStringAsync().Result;
System.Console.WriteLine("Response: " + responseBodyAsText);
if (response.IsSuccessStatusCode)
{
JObject obj = JObject.Parse(responseBodyAsText);
string result = obj["result"].ToString();
System.Console.WriteLine("Recognition result:" + result);
}
else
{
System.Console.WriteLine("Response status code and reason phrase: " +
response.StatusCode + " " + response.ReasonPhrase);
System.Console.WriteLine("Recognition failed.");
}
}
static void Main(string[] args)
{
if (args.Length < 2)
{
System.Console.WriteLine("SpeechRecognizerRESTfulDemo need params: <token> <app-key>");
return;
}
string token = args[0];
string appkey = args[1];
SpeechRecognizerRESTfulDemo demo = new SpeechRecognizerRESTfulDemo(appkey, token);
string fileName = "nls-sample-16k.wav";
string format = "pcm";
int sampleRate = 16000;
bool enablePunctuationPrediction = true;
bool enableInverseTextNormalization = true;
bool enableVoiceDetection = false;
demo.process(fileName, format, sampleRate,
enablePunctuationPrediction, enableInverseTextNormalization, enableVoiceDetection);
}
}
}Demo for Go
package main
import (
"fmt"
"encoding/json"
"net/http"
"io/ioutil"
"strconv"
"bytes"
)
func process(appkey string, token string, fileName string, format string, sampleRate int,
enablePunctuationPrediction bool, enableInverseTextNormalization bool, enableVoiceDetection bool) {
/**
* Configure an HTTP REST POST request:
* 1. Specify the HTTP protocol.
* 2. Set the domain name of the short speech recognition service to nls-gateway-ap-southeast-1.aliyuncs.com.
* 3. Set the request path to /stream/v1/asr for short speech recognition API requests.
* 4. Configure the following required request parameters: appkey, format, and sample_rate.
* 5. Configure the following optional request parameters: enable_punctuation_prediction, enable_inverse_text_normalization, and enable_voice_detection.
*/
var url string = "http://nls-gateway-ap-southeast-1.aliyuncs.com/stream/v1/asr"
url = url + "?appkey=" + appkey
url = url + "&format=" + format
url = url + "&sample_rate=" + strconv.Itoa(sampleRate)
if (enablePunctuationPrediction) {
url = url + "&enable_punctuation_prediction=" + "true"
}
if (enableInverseTextNormalization) {
url = url + "&enable_inverse_text_normalization=" + "true"
}
if (enableVoiceDetection) {
url = url + "&enable_voice_detection=" + "false"
}
fmt.Println(url)
/**
* Retrieve the audio data and add the audio data to the HTTP request body.
. */
audioData, err := ioutil.ReadFile(fileName)
if err != nil {
panic(err)
}
request, err := http.NewRequest("POST", url, bytes.NewBuffer(audioData))
if err != nil {
panic(err)
}
/**
* Configure the HTTP request header:
* 1. Configure authentication parameters.
* 2. Set the Content-Type parameter to application/octet-stream.
*/
request.Header.Add("X-NLS-Token", token)
request.Header.Add("Content-Type", "application/octet-stream")
/**
* Send the HTTP POST request and process the response that is returned by the server.
*/
client := &http.Client{}
response, err := client.Do(request)
if err != nil {
panic(err)
}
defer response.Body.Close()
body, _ := ioutil.ReadAll(response.Body)
fmt.Println(string(body))
statusCode := response.StatusCode
if (statusCode == 200) {
var resultMap map[string]interface{}
err = json.Unmarshal([]byte(body), &resultMap)
if err != nil {
panic(err)
}
var result string = resultMap["result"].(string)
fmt.Println("Recognition succeeded:" + result)
} else {
fmt.Println("Recognition failed. HTTP StatusCode: " + strconv.Itoa(statusCode))
}
}
func main() {
var appkey string = "Your appkey"
var token string = "Your token"
var fileName string = "nls-sample-16k.wav"
var format string = "pcm"
var sampleRate int = 16000
var enablePunctuationPrediction bool = true
var enableInverseTextNormalization bool = true
var enableVoiceDetection = false
process(appkey, token, fileName, format, sampleRate, enablePunctuationPrediction, enableInverseTextNormalization, enableVoiceDetection)
}