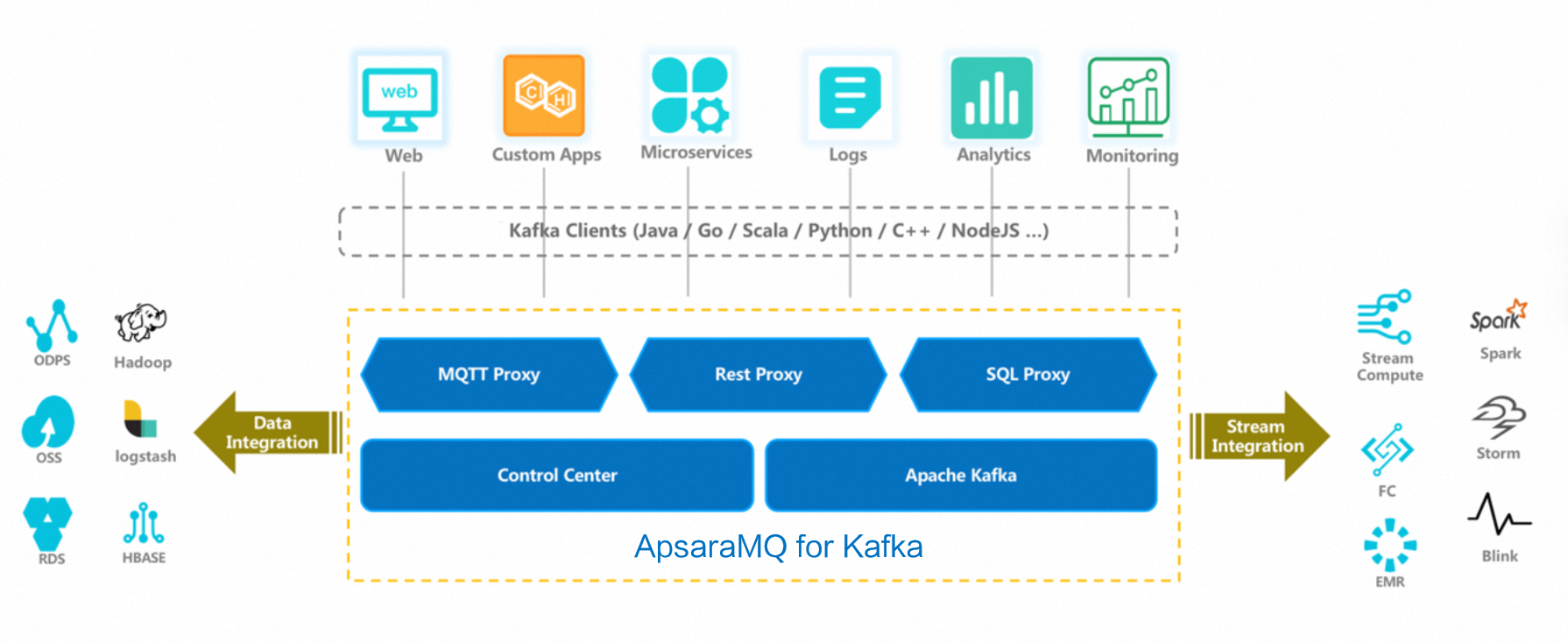
ApsaraMQ for Kafka is a fully managed, distributed messaging service built on Apache Kafka that delivers high throughput and elastic scalability for real-time data pipelines, without the operational overhead of self-managed clusters.
Common workloads include log collection, monitoring data aggregation, streaming data processing, and large-scale online and offline analytics.
%E8%8B%B1%E6%96%87%E7%89%88Kafka-%E4%BF%AE%E6%94%B9%E7%AC%AC%E4%B8%89%E7%89%88.mp4
Why use a managed Kafka service
Running Apache Kafka in production requires significant operational investment. ApsaraMQ for Kafka handles these tasks so you can focus on your applications:
-
Cluster provisioning and configuration -- Deploy ready-to-use Kafka clusters without manual setup.
-
Patching and version upgrades -- Apply security patches and Kafka version updates with minimal disruption.
-
Monitoring and alerting -- Track cluster health and throughput through integrated tools.
-
Elastic scaling -- Scale broker capacity and storage to match changing workloads.
Compared to self-managed Apache Kafka, ApsaraMQ for Kafka reduces infrastructure costs, improves reliability, and scales with less effort.
Network access
ApsaraMQ for Kafka supports access over the internet or through a Virtual Private Cloud (VPC). You can fully manage your VPC: define CIDR blocks, configure route tables and gateways, and deploy other Alibaba Cloud resources -- such as Elastic Compute Service (ECS) instances, ApsaraDB RDS instances, and Server Load Balancer (SLB) instances -- alongside your Kafka clusters.
Use cases
ApsaraMQ for Kafka supports a range of big data and real-time processing scenarios.
-
User behavior analysis -- Analyze website user actions and clickstream data to understand usage patterns.
-
Log aggregation -- Collect logs from distributed applications and infrastructure into a central pipeline for search, alerting, and analysis.
-
Monitoring and observability -- Aggregate monitoring data from multiple sources and stream it to dashboards and alerting systems for real-time operational visibility.
-
Stream processing -- Build event-driven architectures that react to data in real time.
-
Offline data analysis -- Buffer high-volume event streams and load them into data warehouses for historical analysis and reporting.
Ecosystem integrations
ApsaraMQ for Kafka integrates with Alibaba Cloud services and open-source frameworks for data movement and processing.
Data integration
Move messages from Kafka topics into downstream storage and analytics systems:
| Target service | Use case |
|---|---|
| MaxCompute | Large-scale data warehousing and batch analytics |
| Object Storage Service (OSS) | Long-term storage and archiving |
| ApsaraDB RDS | Relational database synchronization |
| Hadoop / HBase | Distributed storage for big data workloads |
Stream processing engines
Connect Kafka to real-time compute engines for continuous data processing:
| Engine | Use case |
|---|---|
| Realtime Compute for Apache Flink | Managed stream processing |
| E-MapReduce (EMR) | Managed Hadoop and Spark clusters for batch and streaming |
| Spark | In-memory analytics and streaming |
| Storm | Low-latency, event-by-event stream processing |
Get started
Choose a starting point based on your goal:
-
Create your first instance -- Follow the quick start guide to provision a Kafka instance and produce your first message.
-
Understand core concepts -- Learn about topics, partitions, consumer groups, and how ApsaraMQ for Kafka organizes data.
-
Connect your applications -- Use the SDK to integrate Kafka producers and consumers into your applications.
-
Set up data pipelines -- Configure connectors to move data between Kafka and other Alibaba Cloud services.