The Binning component is used for feature discretization. Feature discretization is a process of converting continuous data into multiple discrete intervals. The Binning component supports equal frequency binning, equal width binning, and automated binning.
Component configurations
You can use one of the following methods to configure the Binning component.
Method 1: Configure the component on the pipeline page
| Tab | Parameter | Description |
|---|---|---|
| Fields Setting | Feature Columns | Columns of the STRING, BIGINT, and DOUBLE types are supported. |
| Label Column | This parameter is required only for binary classification. | |
| Positive Value | This parameter is valid only if the Label Column parameter is specified. | |
| Binning Parameter Source | Valid values: Parameters in Parameter Settings and Manual Binning or Custom JSON. | |
| Reserve Unselected Feature Columns | This parameter is valid only if you set the Binning Parameter Source parameter to Manual Binning or Custom JSON. If you set the Reserve Unselected Feature Columns parameter to Yes, the columns that are not specified for the Feature Columns parameter remain unchanged in the output. Otherwise, the columns that are not specified for the Feature Columns parameter are removed from the output. | |
| Upload Binning and Constraint JSON Code | This parameter is valid only if you set the Binning Parameter Source parameter to Manual Binning or Custom JSON. | |
| Parameters Setting | Bins | If you set this parameter to 10, continuous features are converted into 10 discrete intervals. |
| Custom Bins | You can specify the numbers of bins for specific columns. The setting of this parameter takes precedence over the setting of the Bins parameter. If a specific column is not included in the selected columns, this column is also used in binning. For example, columns col0 and col1 are selected for data binning. The number of bins customized for the col0 column is 3, and that customized for the col2 column is 5. If the Bins parameter is set to 10, binning is performed based on col0:3,col1:10,col2:5. Specify this parameter in the format of Column name 1:Number of bins,Column name 2:Number of bins. | |
| Custom Discrete Value Count Threshold | Specify this parameter in the col0:3 format. | |
| Interval Type | Valid values: Left-open, Right-closed and Left-closed, Right-open. | |
| Binning Mode | Valid values: Equal Frequency, Equal Width, and Automatic Binning. | |
| Discrete Value Count Threshold | If a value is less than this threshold, the value is distributed to the else bin. | |
| Tuning | Cores | The number of cores. By default, the system determines the value. |
| Memory Size per Core | The memory size of each core. By default, the system determines the value. |
Method 2: Use PAI commands
PAI -name binning
-project algo_public
-DinputTableName=input
-DoutputTableName=output| Parameter | Description | Required | Default value |
|---|---|---|---|
| inputTableName | The name of the input table. | Yes | None |
| outputTableName | The name of the output table. | Yes | None |
| selectedColNames | The columns that are selected from the input table for binning. | No | All columns except the label column (If no label column exists, all columns are selected.) |
| labelColName | The label column. | No | None |
| validTableName | The name of the validation table. This parameter is required if the binningMethod parameter is set to auto. | No | Null |
| validTablePartitions | The partitions that are selected from the validation table. | No | Full table |
| inputTablePartitions | The partitions that are selected from the input table. | No | Full table |
| inputBinTableName | The input binning table. | No | None |
| selectedBinColNames | The columns that are selected from the input binning table. | No | Null |
| positiveLabel | Specifies whether the samples are positive samples. | No | 1 |
| nDivide | The number of bins. The value of this parameter must be a positive integer. | No | 10 |
| colsNDivide | The numbers of bins for specific columns. Specify this parameter in the format of Column name 1:Number of bins,Column name 2:Number of bins. Example: col0:3,col2:5. If the columns that are specified for the colsNDivide parameter are not included in those specified for the selectedColNames parameter, the columns are also used in binning. For example, the selectedColNames parameter is set to col0,col1, the colsNDivide parameter is set to col0:3,col2:5, and the nDivide parameter is set to 10. In this case, binning is performed based on col0:3,col1:10,col2:5. | No | Null |
| isLeftOpen | The interval type. Valid values:
| No | true |
| stringThreshold | The threshold for discrete values in the else bin. | No | None |
| colsStringThreshold | The threshold for specific columns. Specify this parameter in the same format as the colsNDivide parameter. | No | Null |
| binningMethod | The binning mode. Valid values:
| No | quantile |
| lifecycle | The lifecycle of the output table. The value of this parameter must be a positive integer. | No | None |
| coreNum | The number of cores. The value of this parameter must be a positive integer. | No | Determined by the system |
| memSizePerCore | The memory size of each core. The value of this parameter must be a positive integer. | No | Determined by the system |
- Ascending order: Weights must be added to the dummy variables of a feature based on index values in ascending order. This indicates that a dummy variable with a greater index value has a higher weight.
- Descending order: Weights must be added to the dummy variables of a feature based on index values in descending order. This indicates that a dummy variable with a greater index value has a lower weight.
- Same weight: The weights of two dummy variables of a feature must be the same.
- Zero weight: The weight of a dummy variable must be 0.
- Specific weight: The weight of a dummy variable must be a specific floating-point value.
- WOE order: Weights must be added to the dummy variables of a feature based on the weight of evidence (WOE) values in ascending order. This indicates that a dummy variable with a greater WOE value has a higher weight.
Result presentation
- After the workflow that contains the Binning component finishes running, right-click the Binning component on the canvas and select Binning.
- On the variable list page, you can check the Bins, Type, and IV information for each variable. The following figure shows an example of variable information.

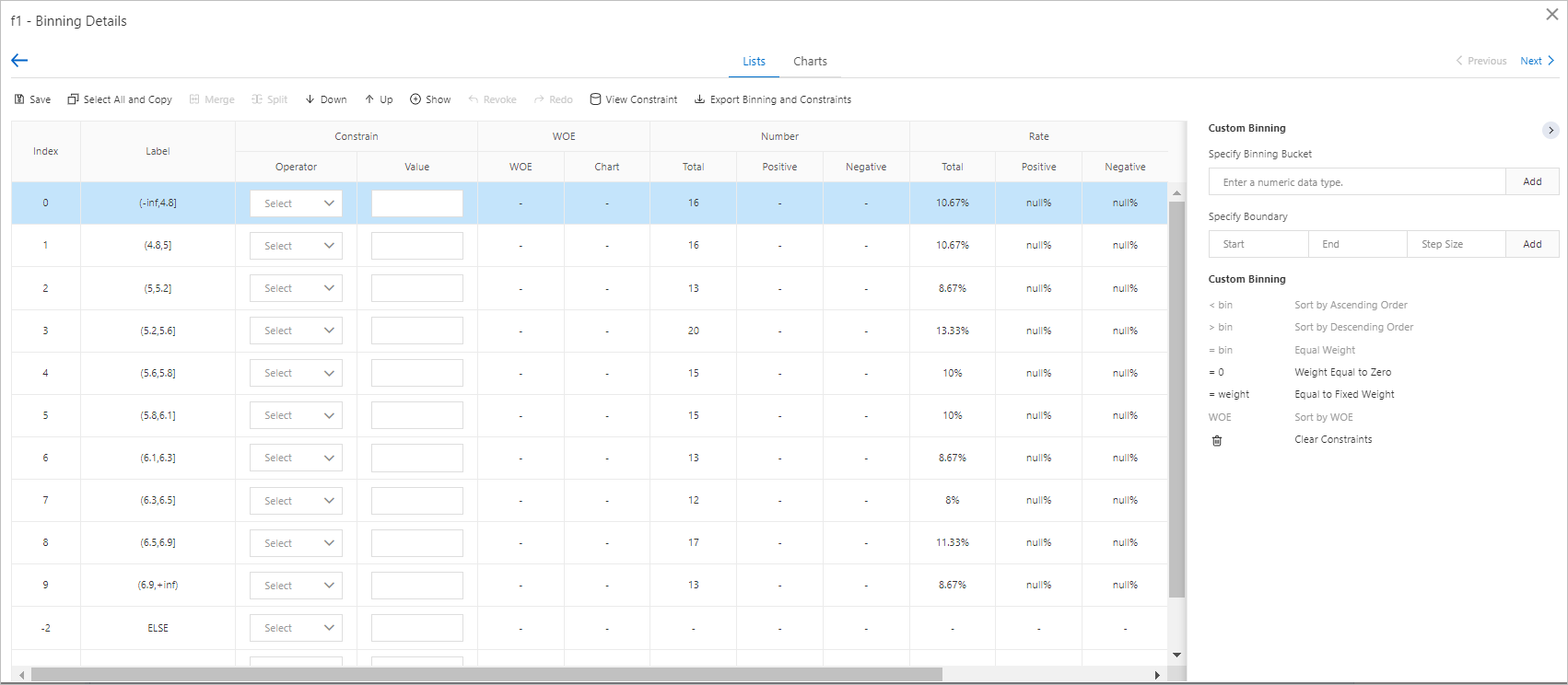
- Click the name of a variable such as f1 to go to the binning details page of the variable. The following figure shows the binning details page of f1. You can click Merge or Split to merge or split binning data. You can also specify constraints for bins.Note The specified constraints take effect only on the subsequent Scorecard Training component. If you use the Binning component without the Scorecard Training component, these constraints can be ignored.