This section describes how to use the Java SDK to submit a job. The job aims to count the number of times INFO, WARN, ERROR, and DEBUG appear in a log file.
Procedure
Prepare a job.
Upload a data file to Object Storage Service (OSS).
Use the sample codes.
Compile and pack the codes.
Upload the package to OSS.
Use the SDK to create (submit) the job.
Check the result.
1. Prepare a job
The job aims to count the number of times INFO, WARN, ERROR, and DEBUG appear in a log file.
This job contains the following tasks:
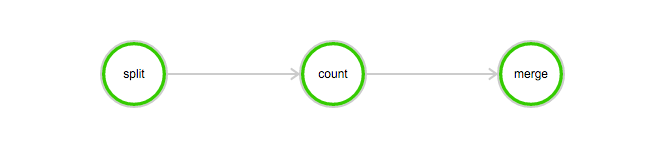
The split task is used to divide the log file into three parts.
The count task is used to count the number of times INFO, WARN, ERROR, and DEBUG appear in each part of the log file. In the count task, InstanceCount must be set to 3, indicating that three count tasks are started concurrently.
The merge task is used to merge all count results.
DAG
1.1. Upload a data file to OSS
Download the data file used in this example: log-count-data.txt
Upload the log-count-data.txt file to oss://<your-bucket>/log-count/log-count-data.txt.
Replace <your-bucket> with the name of the bucket created by yourself. In this example, the cn-shenzhen region is used.
1.2. Use the sample codes
Here, Java is used to compile the tasks of the job, and specifically Maven is used for compiling. We recommend that you use IDEA, and you can download the free Community version of IDEA from https://www.jetbrains.com/idea/download/.
Download the sample program: java-log-count.zip
This is a Maven project.
You do not need to modify codes.
1.3. Compile and pack codes
Run the following command to compile and pack the codes:
mvn packageThe following .jar packages are obtained under the target directory:
batchcompute-job-log-count-1.0-SNAPSHOT-Split.jar
batchcompute-job-log-count-1.0-SNAPSHOT-Count.jar
batchcompute-job-log-count-1.0-SNAPSHOT-Merge.jarRun the following command to pack the three .jar packages into a tar.gz file:
> cd target # Switch to the target directory.
> tar -czf worker.tar.gz *SNAPSHOT-*.jar # Pack the .jar packages.Run the following command to check whether the package content is correct:
> tar -tvf worker.tar.gz
batchcompute-job-log-count-1.0-SNAPSHOT-Split.jar
batchcompute-job-log-count-1.0-SNAPSHOT-Count.jar
batchcompute-job-log-count-1.0-SNAPSHOT-Merge.jarBatch Compute supports only the compressed packages with the extension tar.gz. Make sure that you use the preceding method (gzip) for packaging. Otherwise, the package cannot be parsed.
1.4. Upload the package to the OSS
In this example, upload worker.tar.gz to oss://<your-bucket>/log-count/worker.tar.gz.
To run the job in this example, you must create your own bucket. In addition, upload worker.tar.gz to the path of your own bucket.
2. Use the SDK to create (submit) the job
2.1. Create a Maven project
Add the following dependencies to pom.xml:
<dependencies>
<dependency>
<groupId>com.aliyun</groupId>
<artifactId>aliyun-java-sdk-batchcompute</artifactId>
<version>5.2.0</version>
</dependency>
<dependency>
<groupId>com.aliyun</groupId>
<artifactId>aliyun-java-sdk-core</artifactId>
<version>3.2.3</version>
</dependency>
</dependencies>Make sure that the SDK of the latest version is used. For more information, see Download and install.
2.2. Create a Java class: Demo.java
When submitting a job, you must specify a cluster ID or use the AutoCluster parameters.
In this example, the AutoCluster parameters are used. You must configure the following parameters for the AutoCluster:
Available image ID. You can use an image provided by the system or a custom image.
InstanceType. For more information about the available instance types, see Currently supported instance types.
Create a path for storing the StdoutRedirectPath (program outputs) and StderrRedirectPath (error logs) in the OSS. In this example, the created path is oss://your-bucket/log-count/logs/.
To run the program in this example, modify variables with comments in the program based on the previously described variables and OSS path variables.
The following provides a sample program that uses the Java SDK to submit a job. For specific meanings of parameters in the program, see SDK interface description.
Demo.java:
/*
* IMAGE_ID: ECS image. It can be obtained according to the previous descriptions.
* INSTANCE_TYPE: Instance type. It can be obtained according to the previous descriptions.
* REGION_ID: The region is Qingdao or Hangzhou. Currently, the Batch Compute service is provided only in Qingdao. The region must be consistent with the region of the bucket used to store the worker.tar.gz in the OSS.
* ACCESS_KEY_ID: The AccessKeyID can be obtained according to the previous descriptions.
* ACCESS_KEY_SECRET: The AccessKeySecret can be obtained according to the previous descriptions.
* WORKER_PATH: OSS storage path to which worker.tar.gz is packed and uploaded.
* LOG_PATH: Storage path of the error feedback and task outputs.
*/
import com.aliyuncs.batchcompute.main.v20151111.*;
import com.aliyuncs.batchcompute.model.v20151111.*;
import com.aliyuncs.batchcompute.pojo.v20151111.*;
import com.aliyuncs.exceptions.ClientException;
import java.util.ArrayList;
import java.util.List;
public class Demo {
static String IMAGE_ID = "img-ubuntu";; //Enter the ECS image ID
static String INSTANCE_TYPE = "ecs.sn1.medium"; //Enter the appropriate instance type based on the region
static String REGION_ID = "cn-shenzhen"; //Enter the region
static String ACCESS_KEY_ID = ""; //"your-AccessKeyId"; Enter your AccessKeyID
static String ACCESS_KEY_SECRET = ""; //"your-AccessKeySecret"; Enter your AccessKeySecret
static String WORKER_PATH = ""; //"oss://your-bucket/log-count/worker.tar.gz"; // Enter the OSS storage path to which worker.tar.gz is uploaded
static String LOG_PATH = ""; // "oss://your-bucket/log-count/logs/"; // Enter the OSS storage path of the error feedback and task outputs
static String MOUNT_PATH = ""; // "oss://your-bucket/log-count/";
public static void main(String[] args){
/** Construct the BatchCompute client */
BatchCompute client = new BatchComputeClient(REGION_ID, ACCESS_KEY_ID, ACCESS_KEY_SECRET);
try{
/** Construct the job object */
JobDescription jobDescription = genJobDescription();
// Create a job
CreateJobResponse response = client.createJob(jobDescription);
//After the successful creation, the jobId is returned
String jobId = response.getJobId();
System.out.println("Job created success, got jobId: "+jobId);
//Query the job status
GetJobResponse getJobResponse = client.getJob(jobId);
Job job = getJobResponse.getJob();
System.out.println("Job state:"+job.getState());
} catch (ClientException e) {
e.printStackTrace();
System.out.println("Job created failed, errorCode:"+ e.getErrCode()+", errorMessage:"+e.getErrMsg());
}
}
private static JobDescription genJobDescription(){
JobDescription jobDescription = new JobDescription();
jobDescription.setName("java-log-count");
jobDescription.setPriority(0);
jobDescription.setDescription("log-count demo");
jobDescription.setJobFailOnInstanceFail(true);
jobDescription.setType("DAG");
DAG taskDag = new DAG();
/** Add a split task */
TaskDescription splitTask = genTaskDescription();
splitTask.setTaskName("split");
splitTask.setInstanceCount(1);
splitTask.getParameters().getCommand().setCommandLine("java -jar batchcompute-job-log-count-1.0-SNAPSHOT-Split.jar");
taskDag.addTask(splitTask);
/** Add a count task */
TaskDescription countTask = genTaskDescription();
countTask.setTaskName("count");
countTask.setInstanceCount(3);
countTask.getParameters().getCommand().setCommandLine("java -jar batchcompute-job-log-count-1.0-SNAPSHOT-Count.jar");
taskDag.addTask(countTask);
/** Add a merge task */
TaskDescription mergeTask = genTaskDescription();
mergeTask.setTaskName("merge");
mergeTask.setInstanceCount(1);
mergeTask.getParameters().getCommand().setCommandLine("java -jar batchcompute-job-log-count-1.0-SNAPSHOT-Merge.jar");
taskDag.addTask(mergeTask);
/** Add the task dependencies: split-->count-->merge */
List<String> taskNameTargets = new ArrayList();
taskNameTargets.add("merge");
taskDag.addDependencies("count", taskNameTargets);
List<String> taskNameTargets2 = new ArrayList();
taskNameTargets2.add("count");
taskDag.addDependencies("split", taskNameTargets2);
//dag
jobDescription.setDag(taskDag);
return jobDescription;
}
private static TaskDescription genTaskDescription(){
AutoCluster autoCluster = new AutoCluster();
autoCluster.setInstanceType(INSTANCE_TYPE);
autoCluster.setImageId(IMAGE_ID);
//autoCluster.setResourceType("OnDemand");
TaskDescription task = new TaskDescription();
//task.setTaskName("Find");
//If the VPC instance is used, configure the CIDR block and avoid any CIDR block conflict
Configs configs = new Configs();
Networks networks = new Networks();
VPC vpc = new VPC();
vpc.setCidrBlock("192.168.0.0/16");
networks.setVpc(vpc);
configs.setNetworks(networks);
autoCluster.setConfigs(configs);
//Complete OSS path of the job for packaging and uploading
Parameters p = new Parameters();
Command cmd = new Command();
//cmd.setCommandLine("");
//Complete OSS path of the job for packaging and uploading
cmd.setPackagePath(WORKER_PATH);
p.setCommand(cmd);
//Error feedback storage path
p.setStderrRedirectPath(LOG_PATH);
//Final result storage path
p.setStdoutRedirectPath(LOG_PATH);
task.setParameters(p);
task.addInputMapping(MOUNT_PATH, "/home/input");
task.addOutputMapping("/home/output",MOUNT_PATH);
task.setAutoCluster(autoCluster);
//task.setClusterId(clusterId);
task.setTimeout(30000); /* 30000 seconds*/
task.setInstanceCount(1); /** Use one instance to run the program */
return task;
}
}Sample output:
Job created success, got jobId: job-01010100010192397211
Job state:Waiting3. Check job status
You can view the job status by referring to getJob.
//Query the job status
GetJobResponse getJobResponse = client.getJob(jobId);
Job job = getJobResponse.getJob();
System.out.println("Job state:"+job.getState());A job may be in one of the following states: Waiting, Running, Finished, Failed, and Stopped.
4. Check job execution result
You can view the job status by logging on to the Batch Compute console.
After the job finishes running, you can log on to the OSS console and check the following file under your-bucket: /log-count/merge_result.json.
The expected result is as follows:
{"INFO": 2460, "WARN": 2448, "DEBUG": 2509, "ERROR": 2583}Alternatively, you can use the OSS SDK to obtain the results.