AnalyticDB for PostgreSQL can import data from Object Storage Service (OSS) in parallel using the gpossext external table feature. Each compute node reads OSS objects simultaneously, making this approach significantly faster than row-by-row insertion for bulk data loads.
This feature applies to AnalyticDB for PostgreSQL V6.0 instances only. For V7.0, see Use OSS foreign tables to import and export data.
How it works
The gpossext feature extends AnalyticDB for PostgreSQL with an oss:// protocol handler. After installing the oss_ext extension, you define a readable external table that maps to OSS objects. When you run INSERT INTO ... SELECT * FROM, each compute node reads a subset of OSS objects in parallel via a polling mechanism, then redistributes rows to the correct destination partitions.
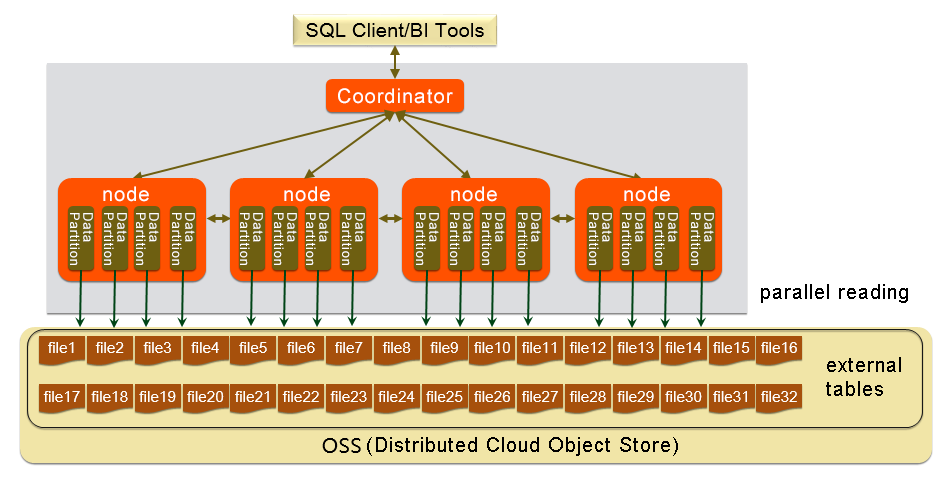
gpossext reads TEXT and CSV files, with or without GZIP compression.
The syntax used to create and use external tables is the same as that of Greenplum Database, except for the syntax of location-related parameters.
Prerequisites
Before you begin, make sure you have:
An AnalyticDB for PostgreSQL V6.0 instance
An OSS bucket in the same region as your instance
An AccessKey ID and AccessKey secret with read access to the bucket
Source data already uploaded to OSS as TEXT or CSV files (plain or GZIP-compressed)
Import data from OSS
Step 1: Install the oss_ext extension
Run the following statement in each database that needs OSS access:
CREATE EXTENSION IF NOT EXISTS oss_ext;Step 2: Distribute source files for parallel reads
Each compute node uses a polling mechanism to claim OSS objects. For best throughput, set the number of OSS objects to an integer multiple of your instance's compute node count. For example, if you have 4 compute nodes, use 4, 8, or 12 objects.
For more information on how compute nodes distribute work, see Overview of OSS foreign tables.
Step 3: Create a readable external table
CREATE [READABLE] EXTERNAL TABLE tablename
( columnname datatype [, ...] | LIKE othertable )
LOCATION ('ossprotocol')
FORMAT 'TEXT'
[( [HEADER]
[DELIMITER [AS] 'delimiter' | 'OFF']
[NULL [AS] 'null string']
[ESCAPE [AS] 'escape' | 'OFF']
[NEWLINE [ AS ] 'LF' | 'CR' | 'CRLF']
[FILL MISSING FIELDS] )]
| 'CSV'
[( [HEADER]
[QUOTE [AS] 'quote']
[DELIMITER [AS] 'delimiter']
[NULL [AS] 'null string']
[FORCE NOT NULL column [, ...]]
[ESCAPE [AS] 'escape']
[NEWLINE [ AS ] 'LF' | 'CR' | 'CRLF']
[FILL MISSING FIELDS] )]
[ ENCODING 'encoding' ]
[ [LOG ERRORS [INTO error_table]] SEGMENT REJECT LIMIT count
[ROWS | PERCENT] ]
ossprotocol:
oss://oss_endpoint [prefix=prefix_name|dir=[folder/[folder/]...]/file_name|filepath=[folder/[folder/]...]/file_name]
id=userossid key=userosskey bucket=ossbucket compressiontype=[none|gzip] async=[true|false]Required parameters
| Parameter | Description |
|---|---|
oss://oss_endpoint | OSS endpoint in the format oss://oss_endpoint. Example: oss://oss-cn-hangzhou.aliyuncs.com. If your AnalyticDB instance runs on an Alibaba Cloud server, use an internal endpoint (the endpoint URL contains the keyword internal) to avoid Internet traffic charges. |
id | Your AccessKey ID. See Create an AccessKey pair. |
key | Your AccessKey secret. See Create an AccessKey pair. |
bucket | The OSS bucket name. Create the bucket before running the import. |
Path parameters (mutually exclusive — specify exactly one)
| Parameter | Description |
|---|---|
prefix | Path prefix for OSS objects. Imports all objects whose paths start with the prefix. Regex is not supported. For example, prefix=test/filename/ imports only test/filename/aa, while prefix=test/filename imports test/filename, test/filenamexxx, test/filename/aa, test/filenameyyy/aa, and test/filenameyyy/bb/aa. |
dir | OSS directory path. The path must end with / (example: test/mydir/). Imports all objects directly in the directory, excluding subdirectories. |
filepath | The object name that contains the OSS object path. Readable external tables only. |
Optional parameters
| Parameter | Default | Description |
|---|---|---|
FORMAT | — | File format: TEXT or CSV. |
ENCODING | — | Character encoding of the objects, such as utf8. |
compressiontype | none | Compression format. Valid values: none, gzip. |
compressionlevel | 6 | Compression level for files written to OSS. Valid values: 1–9. |
async | true | Enables asynchronous import using auxiliary threads. Set to false or f to disable. Asynchronous import consumes more hardware resources compared with regular data import. |
oss_connect_timeout | 10 (seconds) | Connection timeout. |
oss_dns_cache_timeout | 60 (seconds) | DNS resolution timeout. |
oss_speed_limit | 1024 (bytes/s) | Minimum transmission rate. Must be configured together with oss_speed_time. |
oss_speed_time | 15 (seconds) | Maximum duration the transmission rate can remain below oss_speed_limit before a timeout occurs. Must be configured together with oss_speed_limit. With defaults, a timeout triggers if the rate stays below 1 KB/s for 15 consecutive seconds. |
LOG ERRORS | — | Skips rows that fail to import and writes them to error_table. Use count to set the error tolerance threshold. |
Step 4: (Optional) Verify the external table is readable
Before running the full import, confirm the external table can read from OSS:
-- Check a sample of rows
SELECT * FROM <External table> LIMIT 10;
-- Inspect the query plan to confirm parallel reads
EXPLAIN INSERT INTO <Destination table> SELECT * FROM <External table>;The query plan should show External Scan nodes running across all segments, confirming that compute nodes will read OSS objects in parallel.
Step 5: Run the parallel import
INSERT INTO <Destination table> SELECT * FROM <External table>;Each compute node reads its assigned OSS objects and inserts rows into the destination table. The redistribution motion node hashes rows and routes them to the correct compute nodes based on the distribution key.
Example
This example imports stock data from OSS into a table named example.
1. Install the extension.
CREATE EXTENSION IF NOT EXISTS oss_ext;2. Create the destination table.
CREATE TABLE example
(date text, time text, open float,
high float, low float, volume int)
DISTRIBUTED BY (date);For best import performance, use column-oriented storage with compression. For example, you can specify the following clause: WITH (APPENDONLY=true, ORIENTATION=column, COMPRESSTYPE=zlib, COMPRESSLEVEL=5, BLOCKSIZE=1048576). For more information, see CREATE TABLE.
3. Create the external table. Choose the path parameter that matches how your files are organized in OSS.
Using prefix (imports all objects with a matching path prefix, supports GZIP):
CREATE READABLE EXTERNAL TABLE ossexample
(date text, time text, open float, high float,
low float, volume int)
location('oss://oss-cn-hangzhou.aliyuncs.com
prefix=osstest/example id=XXX
key=XXX bucket=testbucket compressiontype=gzip')
FORMAT 'csv' (QUOTE '''' DELIMITER E'\t')
ENCODING 'utf8'
LOG ERRORS SEGMENT REJECT LIMIT 5;Using dir (imports all objects directly in the directory, no GZIP):
CREATE READABLE EXTERNAL TABLE ossexample
(date text, time text, open float, high float,
low float, volume int)
location('oss://oss-cn-hangzhou.aliyuncs.com
dir=osstest/ id=XXX
key=XXX bucket=testbucket')
FORMAT 'csv'
LOG ERRORS SEGMENT REJECT LIMIT 5;Using filepath (imports the specified object):
CREATE READABLE EXTERNAL TABLE ossexample
(date text, time text, open float, high float,
low float, volume int)
location('oss://oss-cn-hangzhou.aliyuncs.com
filepath=osstest/example.csv id=XXX
key=XXX bucket=testbucket')
FORMAT 'csv'
LOG ERRORS SEGMENT REJECT LIMIT 5;4. Import data.
INSERT INTO example SELECT * FROM ossexample;The query plan confirms that all four compute nodes read from OSS in parallel:
EXPLAIN INSERT INTO example SELECT * FROM ossexample;
QUERY PLAN
-------------------------------------------------------------------------------------------------
Insert (slice0; segments: 4) (rows=250000 width=92)
-> Redistribute Motion 4:4 (slice1; segments: 4) (cost=0.00..11000.00 rows=250000 width=92)
Hash Key: ossexample.date
-> External Scan on ossexample (cost=0.00..11000.00 rows=250000 width=92)
(4 rows)TEXT and CSV format reference
The following parameters control how gpossext parses TEXT and CSV files. Specify them in the FORMAT clause of your CREATE EXTERNAL TABLE statement.
\n: line delimiter (newline character)DELIMITER: column separator. If specified,QUOTEmust also be specified. Common choices:,,|,\t.QUOTE: wraps column values that contain special characters. Must differ fromDELIMITER. Default:". Values containingQUOTEcharacters must also useESCAPE.ESCAPE: placed before any character that needs to be treated as a literal. Default: same asQUOTE. Backslash (\) is also commonly used.
All control characters must be single-byte.
Default control characters
| Control character | TEXT | CSV |
|---|---|---|
| DELIMITER | \t (Tab) | , (Comma) |
| QUOTE | " (Double quotation mark) | " (Double quotation mark) |
| ESCAPE | N/A | " (Double quotation mark) |
| NULL | \N (Backslash n) | Empty string without quotation marks |
Troubleshooting
Review import errors
If you used LOG ERRORS when creating the external table, retrieve failed rows with:
SELECT * FROM gp_read_error_log('external_table_name');To clear the error log after reviewing:
SELECT gp_truncate_error_log('external_table_name');The error log is deleted automatically when you drop the external table.
Interpret SDK error fields
OSS SDK errors in the import log include the following fields:
| Field | Description |
|---|---|
code | HTTP status code of the failed request |
error_code | OSS error code |
error_msg | OSS error message |
req_id | UUID of the failed request. Provide this to Alibaba Cloud support when reporting persistent issues. |
For details on OSS error codes, see Error responses.
Fix timeout errors
Adjust oss_speed_limit and oss_speed_time together to tune timeout behavior. For general OSS timeout handling, see Error handlingError handling.
What's next
OSS domain names — find the correct endpoint for your region
OSS documentation — manage buckets and objects
CREATE TABLE — full syntax for table storage options
Error responses — OSS error code reference
Error handlingError handling — timeout and error handling guidance