Use Tunnel Upload commands on the MaxCompute client to upload local CSV or TXT data files directly into MaxCompute tables. Each command transfers a file from your local machine to a specified table or partition in a single step.
Prerequisites
Before you begin, make sure you have:
Created the target tables. See Create tables
Downloaded the data files to your local machine. This topic uses the following sample files:
Non-partitioned table: banking.txt
Partitioned table: banking_nocreditcard.csv, banking_uncreditcard.csv, and banking_yescreditcard.csv
Step 1: Upload data files
Run Tunnel Upload commands on the MaxCompute client to upload local data files to MaxCompute tables. For the full list of Tunnel command options, see Tunnel commands.
The file path format in the command depends on where you store the file:
| Location | Path format | Example |
|---|---|---|
bin directory of the MaxCompute client | <filename>.<extension> | banking.txt |
| Windows (any other directory) | <drive>:\<folder>\<filename>.<extension> | D:\test\banking_yescreditcard.csv |
In this example, banking.txt is stored in the bin directory, and the three CSV files are stored in D:\test\ on Windows. Replace these paths and table names with your actual values.
Run the following commands:
tunnel upload banking.txt bank_data;
tunnel upload D:\test\banking_yescreditcard.csv bank_data_pt/credit="yes";
tunnel upload D:\test\banking_uncreditcard.csv bank_data_pt/credit="unknown";
tunnel upload D:\test\banking_nocreditcard.csv bank_data_pt/credit="no";When OK is returned, the upload is complete. 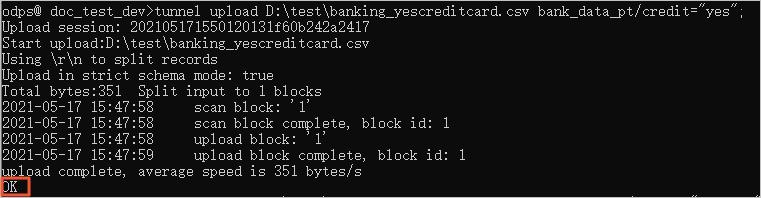
Step 2: Verify the import
After uploading, verify that the row counts match the source files. A mismatch means the data was not fully imported.
The sample files contain the following row counts:
| File | Rows | Target |
|---|---|---|
| banking.txt | 41,188 | bank_data |
| banking_yescreditcard.csv | 3 | bank_data_pt (credit="yes") |
| banking_uncreditcard.csv | 8,597 | bank_data_pt (credit="unknown") |
| banking_nocreditcard.csv | 32,588 | bank_data_pt (credit="no") |
Run the following queries:
select count(*) as num1 from bank_data;
select count(*) as num2 from bank_data_pt where credit="yes";
select count(*) as num3 from bank_data_pt where credit="unknown";
select count(*) as num4 from bank_data_pt where credit="no";Expected output:
-- The number of data records in bank_data.
+------------+
| num1 |
+------------+
| 41188 |
+------------+
-- The number of data records in the partition for which the value of credit is yes in bank_data_pt.
+------------+
| num2 |
+------------+
| 3 |
+------------+
-- The number of data records in the partition for which the value of credit is unknown in bank_data_pt.
+------------+
| num3 |
+------------+
| 8597 |
+------------+
-- The number of data records in the partition for which the value of credit is no in bank_data_pt.
+------------+
| num4 |
+------------+
| 32588 |
+------------+If the counts match, all data is successfully imported.
What's next
Run SQL statements on the MaxCompute client to process the data, then export the results using Tunnel Download. See Execute SQL statements and export the result data.