In a native Kubernetes Service, backend endpoints are distributed across all nodes in the cluster. In edge computing scenarios, edge nodes are grouped into isolated node pools with separate networks, which causes cross-pool traffic failures or poor performance. Service traffic topology lets you restrict which nodes can reach a Service's backend endpoints — keeping traffic within the same node pool or on the same node.
How it works
ACK Edge extends the native Kubernetes Service with endpoint topology management. Add an annotation to a Service to define its topology scope. The following diagram shows node-pool-scoped traffic routing.

-
Service 1 has two backend instances: Pod 2 (Node 2, node pool A) and Pod 3 (Node 4, node pool B).
-
The annotation
openyurt.io/topologyKeys: kubernetes.io/zoneon Service 1 sets its topology scope to node pool. -
When Pod 1 accesses Service 1, traffic is forwarded only to Pod 2. Pod 3 is in a different node pool, so traffic to it is blocked.
Prerequisites
Before you begin, ensure that you have:
-
An ACK Edge cluster with edge nodes assigned to node pools
Annotation reference
Add the openyurt.io/topologyKeys annotation to a Service to control its traffic scope.
| Annotation key | Annotation value | Description |
|---|---|---|
openyurt.io/topologyKeys |
kubernetes.io/hostname |
Restricts Service access to the local node only. |
openyurt.io/topologyKeys |
kubernetes.io/zone or openyurt.io/nodepool |
Restricts Service access to nodes in the same node pool. For ACK Edge cluster versions 1.18 or later, use openyurt.io/nodepool. |
| - | - | No topology restriction. The Service is accessible from all nodes. |
Version-specific behavior
-
Earlier than v1.26.3-aliyun.1: Add the topology annotation when creating the Service. Adding it after creation has no effect — delete and recreate the Service for the change to take effect.
-
v1.26.3-aliyun.1 and later: Add or modify the topology annotation at any time. The change takes effect immediately.
Configure Service traffic topology
Choose either the console or the command line.
Use the console
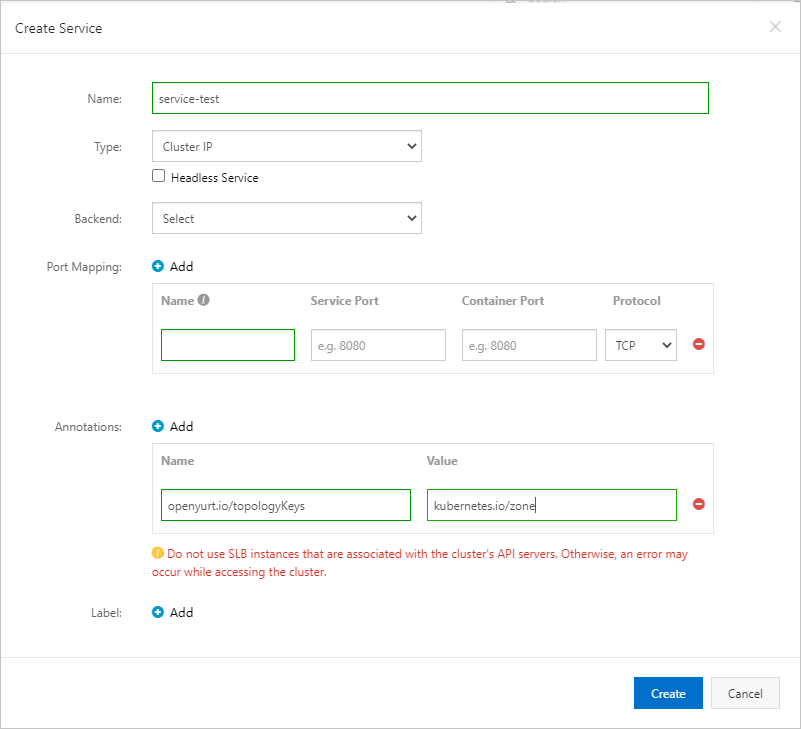
When creating a Service, add the topology annotation in the Annotations section:
-
Name:
openyurt.io/topologyKeys -
Value:
kubernetes.io/zone
For instructions on creating a Service, see Service management.
Use the command line
Apply the following YAML to create a Service with node-pool-scoped traffic topology:
apiVersion: v1
kind: Service
metadata:
annotations:
openyurt.io/topologyKeys: kubernetes.io/zone
name: my-service-nodepool
namespace: default
spec:
ports:
- port: 80
protocol: TCP
targetPort: 8080
selector:
app: nginx
sessionAffinity: None
type: ClusterIPAfter applying the manifest, verify that the annotation is set:
kubectl get service my-service-nodepool -o jsonpath='{.metadata.annotations.openyurt\.io/topologyKeys}'The expected output is kubernetes.io/zone, confirming that traffic is restricted to nodes in the same node pool.
What's next
-
To learn more about managing Services in ACK Edge, see Service management.