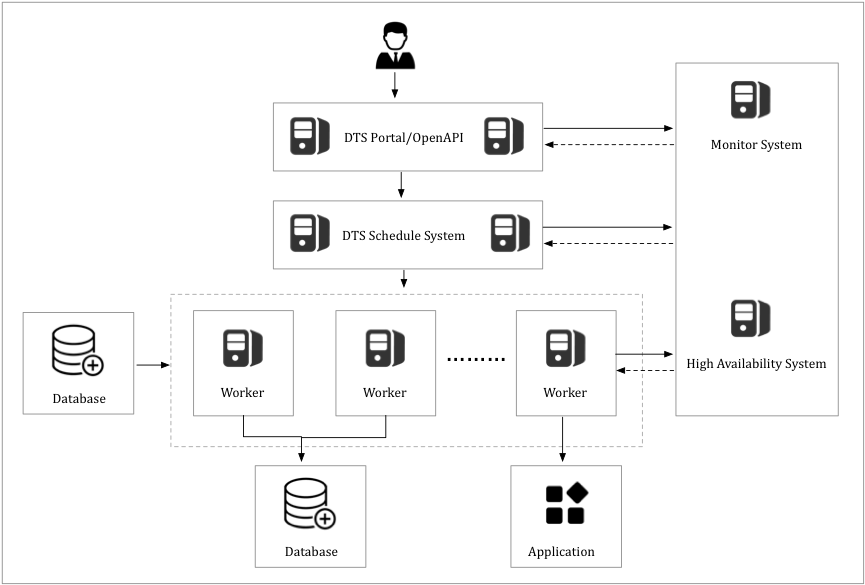
Data Transmission Service (DTS) uses a modular architecture built around high availability (HA). Each module runs on servers with primary/secondary redundancy. The HA manager continuously health-checks every server and, when it detects an exception, switches workloads to a healthy server with minimal latency. For continuous replications — data synchronization and change tracking — the HA manager also detects endpoint changes on data sources and reconfigures the connection automatically.
- Primary/secondary redundancy
Each DTS module is deployed in a primary/secondary architecture for redundancy. The disaster recovery system continuously performs health checks on each server. If a server fails, its workloads are switched over to a healthy server with minimal latency.
- Dynamic endpoint detection
For data synchronization and change tracking tasks, the disaster recovery system detects changes to the data source endpoint. If an endpoint change is detected, the disaster recovery system reconfigures the data source to ensure the connection remains stable.
How DTS works in data migration mode
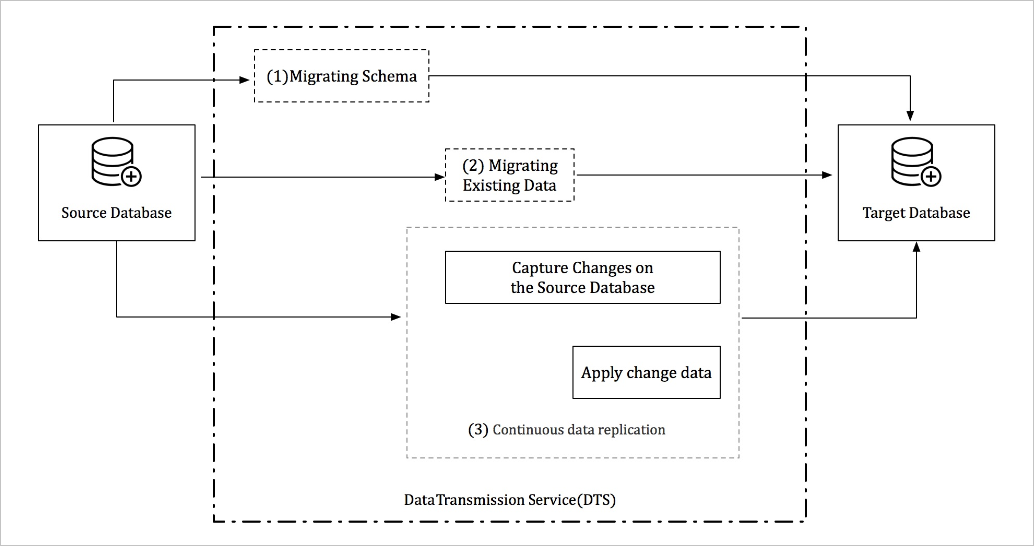
A complete data migration runs through three sequential phases: schema migration, full data migration, and incremental data migration. Select all three phases when you configure a data migration task — this keeps the source database operational throughout.
Schema migration: DTS re-creates the schema in the destination database before any data moves. For migrations between heterogeneous databases, DTS parses the DDL (Data Definition Language) of the source database, translates it into the destination database syntax, and re-creates the schema objects.
Full data migration: DTS migrates historical data from the source to the destination. The source database stays online and continues accepting writes during this phase. To capture those ongoing writes, DTS activates an incremental data reader at the start of full data migration. Incremental data is parsed, reformatted, and stored locally on the DTS server while the full migration runs.
Incremental data migration: After full data migration completes, DTS retrieves the locally stored incremental data and applies it to the destination. This phase continues until the destination is in sync with the source and the replication lag reaches a steady state.
How DTS works in data synchronization mode
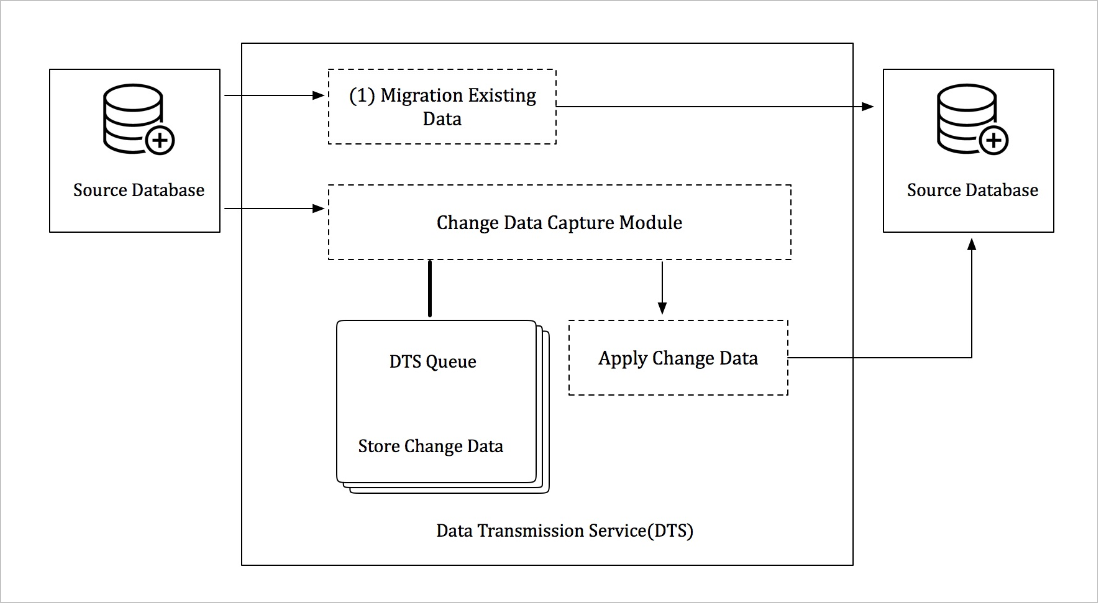
Data synchronization mode replicates ongoing data changes between two data stores. It is commonly used for OLTP-to-OLAP replications, where OLTP (online transaction processing) handles transactional workloads and OLAP (online analytical processing) handles analytical queries.
A data synchronization task runs two phases in sequence:
Initial data synchronization: DTS synchronizes historical data from the source to the destination.
Real-time data synchronization: DTS continuously replicates ongoing data changes to keep the destination in sync with the source.
Two components handle the ongoing replication:
Transaction log reader: Connects to the source instance over the appropriate protocol — for example, over the binlog dump protocol for an ApsaraDB RDS for MySQL instance. It reads incremental logs, then parses, filters, and converts the data before persisting it locally on the DTS server.
Transaction log applier: Retrieves updates from the transaction log reader, filters out changes unrelated to the objects being replicated, and applies the remaining changes to the destination database. The applier preserves the atomicity, consistency, isolation, and durability (ACID) properties of each transaction.
Both components run in redundancy mode. If an exception occurs on either component, the HA manager resumes transaction log execution on a healthy server.
How DTS works in change tracking mode
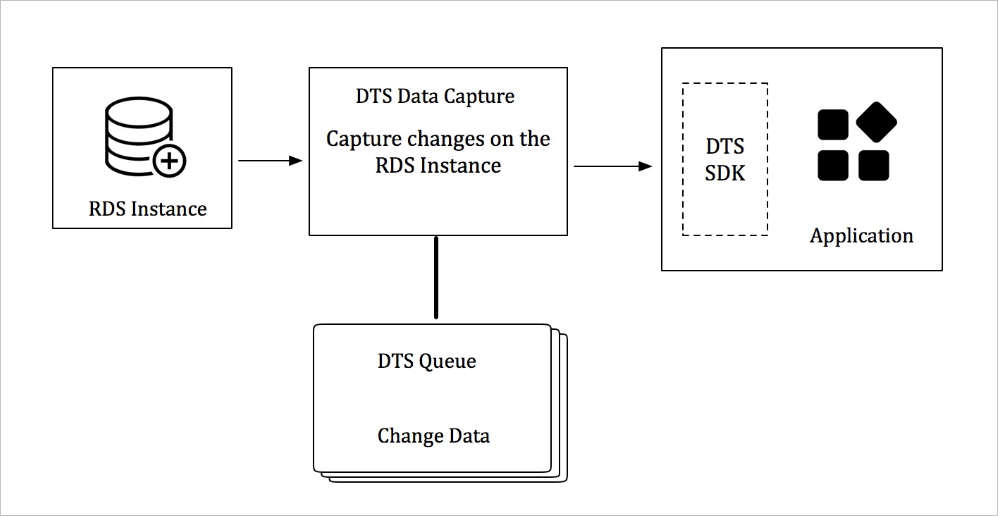
Change tracking mode gives you real-time access to the incremental data logs of an ApsaraDB RDS instance. Consume the logs on the change tracking server using DTS SDKs, and define custom data consumption rules to match your requirements.
The log processor connects to the source instance over the appropriate protocol — for example, over the binlog dump protocol for an ApsaraDB RDS for MySQL instance. It reads the incremental logs, then parses, filters, and converts the syntax before storing the data locally on the DTS server.
DTS ensures high availability at two levels:
Log processor HA: When the HA manager detects an exception on the log processor, it restarts the log processor on a healthy service node.
SDK consumption HA: Start multiple SDK-based consumption processes for a single change tracking task. The server pushes incremental data through one process at a time. If that process encounters an exception, the server automatically switches to another consumption process.