Delta Lake is a data lake solution that is developed by Databricks. Delta Lake provides features that can be used to write data to data lakes, manage data, query data, and read data from data lakes. You can build easy-to-use and secure data lakes by using Delta Lake and third-party upstream and downstream tools.
Background information
Traditional data lake solutions allow you to use a big data storage engine, such as Alibaba Cloud Object Storage Service (OSS) or Hadoop Distributed File System (HDFS), to build a data lake and store various types of data in the data lake. You can connect the data lake to an analytics engine such as Spark or Presto to analyze the data stored in the data lake. Traditional data lake solutions have the following disadvantages:
Data ingestion may fail. If data ingestion fails, dirty data cleanup and job recovery are required.
Data quality control is unavailable due to the lack of extract, transform, load (ETL) operations.
In streaming processing and batch processing, no transactions can be used to isolate reads and writes.
Description of the Delta Lake solution:
This solution provides a data management layer on top of the big data storage layer. This data management layer functions in a similar manner to the metadata management module for a database. Delta Lake metadata is stored together with data and is visible to users. Data warehouses and data lakes shows an example.
Delta Lake provides atomicity, consistency, isolation, durability (ACID) transactions based on metadata management to prevent malformed data ingestion and isolate reads and writes during data ingestion. This also ensures that dirty data is not generated.
Field information is stored in metadata. Delta Lake verifies data during data ingestion to ensure data quality.
The transaction feature isolates reads from writes in streaming processing and batch processing.
ACID refers to four basic properties of database transactions. The four basic properties are atomicity, consistency, isolation, and durability.
Figure 1. Data warehouses and data lakes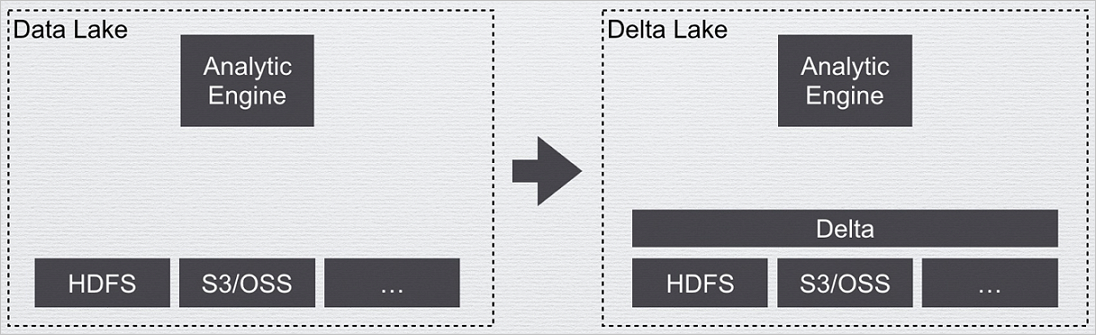
The following table compares a data warehouse, a traditional data lake, and Delta Lake.
Item | Data warehouse | Data lake | Delta Lake |
Architecture | Integrated or separated computing and storage | Separated computing and storage | Separated computing and storage |
Storage management | Stringent and non-general format | Native format | General and lightweight format |
Scenario | Reports and analytics | Reports, analytics, and data science | Reports, analytics, and data science |
Flexibility | Low | High | Medium |
Data quality and reliability | High | Low | Medium |
Transaction | Supported | Not supported | Supported |
Performance | High | Low | Medium |
Scalability | Based on specific scenarios | High | High |
Typical users | Managerial staff | Managerial staff and data scientists | Managerial staff and data scientists |
Costs | High | Low | Low |
Scenarios
Delta Lake is an ideal solution to manage cloud-based data lakes. You can use Delta Lake in the following scenarios:
Real-time query: Upstream data is ingested to Delta Lake in real time to support real-time query. For example, in Change Data Capture (CDC) scenarios, when you use a Spark Streaming job to consume binary logs in real time, you can use the merge feature that is provided by Delta Lake to merge upstream data updates to Delta Lake in real time. This way, you can use Hive, Spark, or Presto to query the data in real time. ACID transactions isolate data writes from queries to avoid dirty reads.
Data deletes and updates due to General Data Protection Regulation (GDPR) requests: Traditional data lakes do not support data deletes or updates. If you want to delete data, you must manually delete the data. If you want to update data, you must manually delete the original data and write the updated data into the storage. Delta Lake supports data deletes and updates.
Real-time data synchronization based on CDC: You can run a streaming job to merge upstream data updates to Delta Lake in real time by using the merge feature that is provided by Delta Lake.
Data quality control: Delta Lake provides the schema verification feature that allows you to remove abnormal data during data ingestion. You can also use this feature to process abnormal data.
Data evolution: You may need to change your data schema. Delta Lake provides an API for you to change your data schema.
Real-time machine learning: In machine learning scenarios, you may require a significant amount of time to process data, such as to cleanse, convert, and characterize data. You also need to separately process historical data and real-time data. Delta Lake simplifies these workflows. Delta Lake provides a complete and reliable real-time stream to cleanse, convert, and characterize data. You do not need to separately process historical data and real-time data.
Comparison with open source Delta Lake
EMR Delta Lake has higher performance than open source Delta Lake. For example, EMR Delta Lake supports more SQL statements and provides the Optimize feature. The following table lists the basic features of Delta Lake and compares EMR Delta Lake with open source Delta Lake 0.6.1.
Feature | EMR Delta Lake | Open source Delta Lake |
SQL |
|
|
API |
|
|
Hive connector | Supported | Supported |
Presto connector | Supported | Supported |
Parquet | Supported | Supported |
ORC | Not supported | Not supported |
Text format | Not supported | Not supported |
Data skipping | Supported | Not supported |
Z-order | Supported | Not supported |
Native DeltaLog | Supported | Not supported |