PolarDB for MySQL 8.0 provides the elastic parallel query (ePQ) feature. The ePQ feature is automatically enabled when the query data volume exceeds the specified threshold, which significantly reduces the query execution time.
Introduction
The ePQ feature supports two parallel engines: single-node elastic parallel query and multi-node elastic parallel query. Single-node elastic parallel query is equivalent to the original parallel query feature. Multi-node elastic parallel query supports adaptive scheduling across nodes in a cluster.
PolarDB for MySQL 8.0.1 supports only single-node elastic parallel query. Query data are sharded across different threads at the storage layer. The threads run in parallel and return the results to the leader thread. Then, the leader thread merges the results and returns the final result to users. This improves the query efficiency.
PolarDB for MySQL 8.0.2 supports single-node elastic parallel query and multi-node elastic parallel query. Multi-node elastic parallel query significantly improves linear acceleration capabilities and implements multi-node distributed parallel computing. Cost-based optimization allows execution plans to be flexible and run in parallel. This addresses potential leader bottlenecks and worker load imbalances that occur in single-node elastic parallel queries. This also overcomes the CPU, memory, and I/O bottlenecks of a single node. Multi-node resource views and the adaptive scheduling of parallel computing tasks greatly enhance parallel computing capabilities, reduce query latency, balance the resource loads of nodes, and improve the overall resource usage of a cluster.
The ePQ feature can address the issue of low and uneven CPU resource utilization in cloud-based user instances by fully using the parallel processing capabilities of multi-core CPUs within the cluster. The following figure shows the process in an 8-core, 32 GB PolarDB for MySQL cluster (dedicated specifications).

Prerequisites
The PolarDB for MySQL cluster meets the following requirements:
Single-node elastic parallel query:
Database engine: 8.0.1 whose revision version is 8.0.1.0.5 or later.
Database edition: Enterprise Edition.
Single-node elastic parallel query:
Database engine: 8.0.2 whose revision version is 8.0.2.1.4.1 or later.
Database edition: Enterprise Edition.
Multi-node elastic parallel query:
Database engine: 8.0.2 whose revision version is 8.0.2.2.6 or later.
Database edition: Enterprise Edition.
For information about how to view the version of a cluster, see Query the engine version.
Scenarios
The ePQ feature is applicable to most SELECT statements, such as queries on large tables, multi-table queries that use JOIN statements, and queries on a large amount of data. The feature does not provide significant benefits for short queries. The diverse parallel methods make the feature suitable for the following scenarios:
Analytic queries on vast amounts of data
If medium or large amounts of data is involved, SQL statements for analytic queries are often complex and time-consuming. You can enable the ePQ feature to linearly reduce the response time.
Imbalanced resource loads
The load balancing capabilities of PolarProxy can help ensure that similar numbers of connections are created for nodes in a cluster. However, due to computing complexity in queries and differences in resource usage, load balancing based on connections cannot completely prevent load imbalance between nodes. Similar to other distributed databases, hotspot nodes have a negative impact on PolarDB:
If a hotspot read-only node causes slow queries, the primary node may not be able to purge undo logs, resulting in disk bloating.
If a hotspot read-only node causes slow redo apply operations, the primary node may not be able to flush data, resulting in reduced write throughput performance.
The ePQ feature introduces global resource views and adaptive task scheduling based on views. Based on the resource usage and data affinity values of each node, some or all query tasks are scheduled to nodes that have idle resources to ensure the desired degree of parallelism (DOP) and balanced resource usage within the cluster.
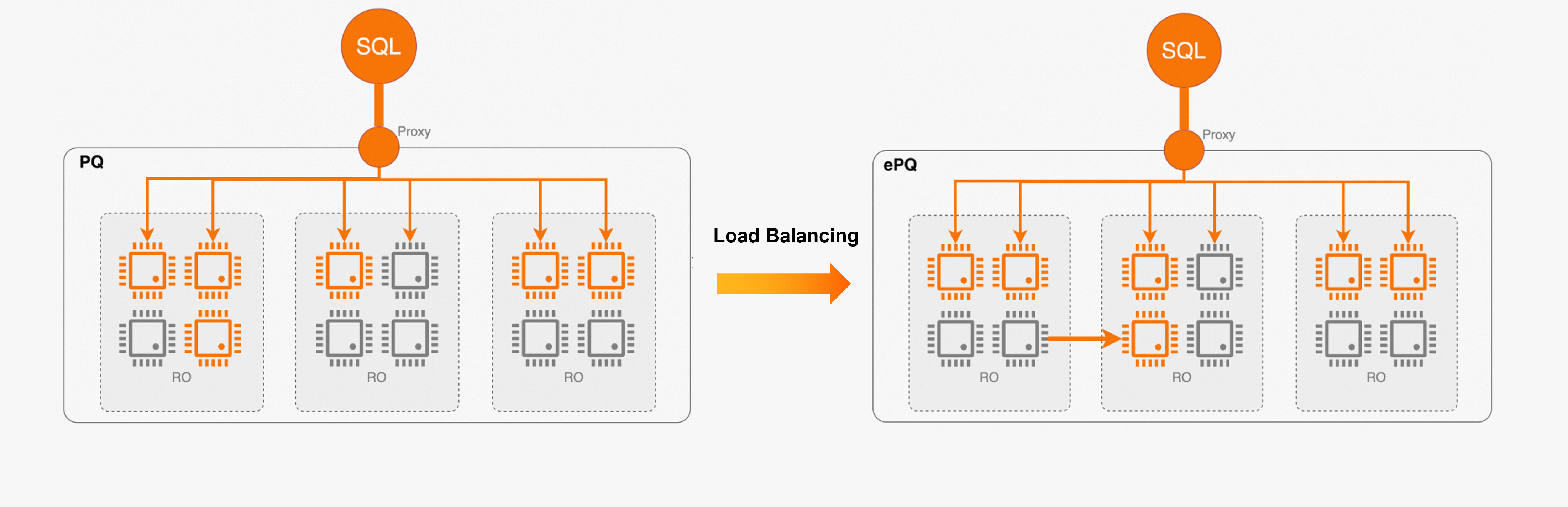
Elastic computing
Elasticity is one of the core capabilities of PolarDB. Automatic scaling provides elasticity that is suitable for short queries. However, it is not suitable for complex analytic queries because a single query cannot be accelerated by adding nodes in large-scale query scenarios. When the ePQ feature is enabled for a cluster, newly scaled out nodes are automatically added to the cluster to share computing resources and enhance elasticity.
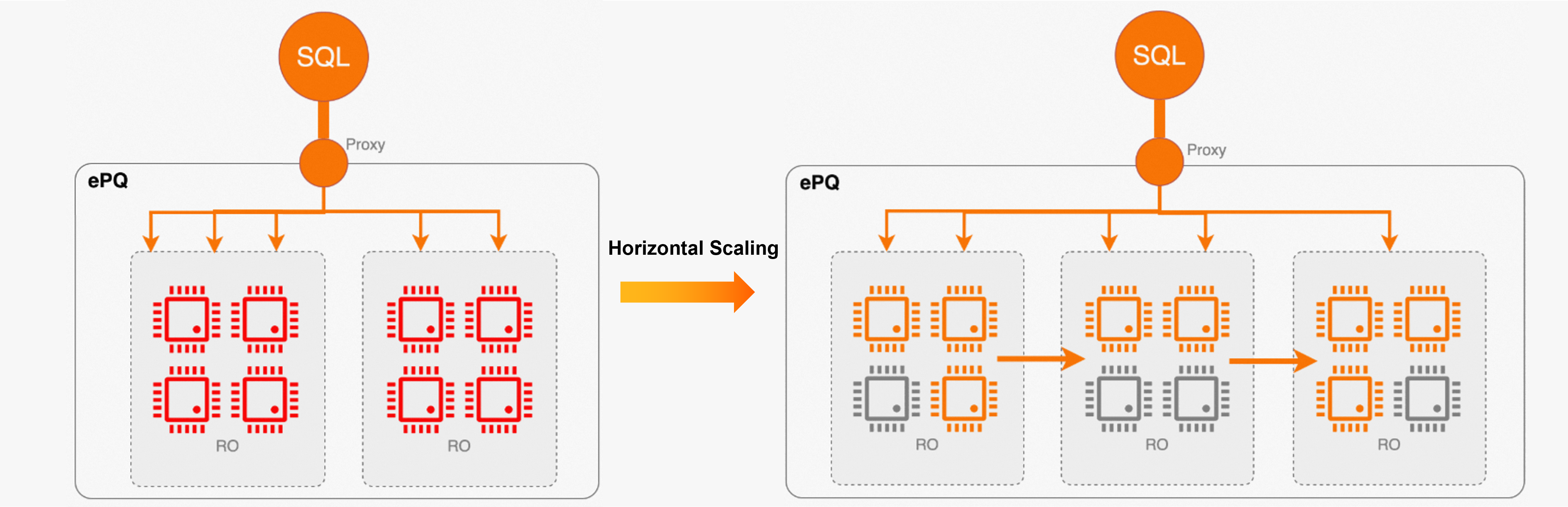
Combination of online and offline services
The most effective isolation method is to route the online transaction service and the offline analytic service to different node sets. However, this method increases costs. In most cases, the online transaction service and the offline analytic service have different peak hours. An economical method is to share cluster resources between the online transaction service and the offline analytic service and route the services to different cluster endpoints. After the ePQ feature is enabled, idle resources are distributed to the offline analytic service during off-peak hours of the online transaction service to reduce costs and improve efficiency.
Usage notes
For information about how to use the ePQ feature, see Usage.
Performance metrics
The following test uses 100 GB of data that is generated based on TPC Benchmark H (TPC-H) to examine the performance of a PolarDB for MySQL 8.0 cluster. In the test, the PolarDB cluster has four nodes that use 32 CPU cores and 256 GB of memory (Dedicated). For single-node elastic parallel query, the max_parallel_degree parameter is set to 32 and 0. Compare the performance data for sequential query, single-node elastic parallel query with DOP of 32, and four-node elastic parallel query with DOP of 128. For more information, see Performance test results in parallel query scenarios.
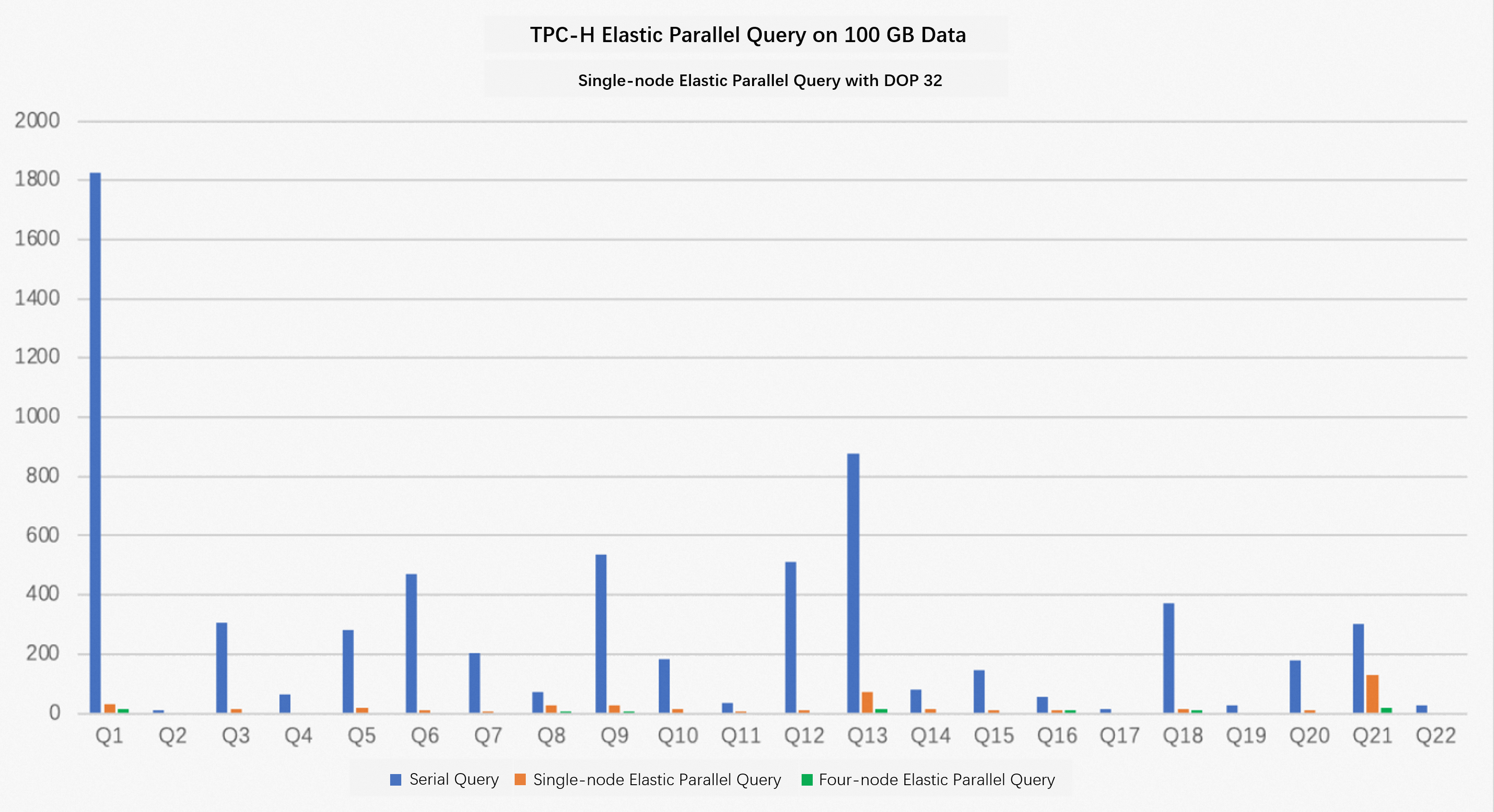
The preceding test results show that 100% of the SQL queries in TPC-H are accelerated. The query speed is 17 times faster on average and 56 times faster at maximum.
When multi-node elastic parallel query is enabled, the query speed is 59 times faster on average and 159 times faster at maximum.
The TPC-H performance test described in this topic is implemented based on the TPC-H benchmark test but cannot meet all requirements of the TPC-H benchmark test. Therefore, the test results cannot be compared with the published results of the TPC-H benchmark test.
View elastic parallel query execution plans
For information about how to execute the EXPLAIN statement to view elastic parallel query information in execution plans, see Execute the EXPLAIN statement to view elastic parallel query execution plans.
Terms
Parallel scan
In a parallel scan, workers scan the data of a table in parallel. Each worker produces a partial result and returns the partial result to the leader thread. The leader thread gathers the results by using the gather node and returns the final result to the client side.
Parallel joins on multiple tables
If the ePQ feature is enabled, the multi-table join operation is pushed down to workers for parallel processing. The PolarDB optimizer selects the optimal table for parallel scanning, but does not perform parallel scanning for other tables. Each worker produces a partial result and returns the partial result to the leader thread. The leader thread gathers the results by using the gather node and returns the final result to the client.
Parallel sorting
The PolarDB optimizer pushes down the ORDER BY operation to all workers for parallel sorting. Each worker produces a partial result and returns the partial result to the leader thread. The leader thread gathers, merges, and sorts all partial results by using the gather merge node, and returns the final sorting result to the client side.
Parallel grouping
The PolarDB optimizer pushes down the GROUP BY operation to workers for parallel processing. Each worker performs the GROUP BY operation on a portion of data. Each worker produces a partial result of GROUP BY and returns the partial result to the leader thread. The leader thread gathers the results from all workers by using the gather node. The PolarDB optimizer determines whether to perform a GROUP BY operation in the leader thread again based on the query plan. For example, if a loose index scan is used to execute a GROUP BY statement, the leader thread does not perform a GROUP BY operation. If the loose index scan is not used, the leader thread performs a GROUP BY operation and returns the final result to the client side.
Parallel aggregation
If the ePQ feature is enabled, the aggregate function is sent to all workers for parallel aggregation. The optimizer determines whether to perform serial execution, one-phase aggregation, or two-phase aggregation based on the cost.
One-phase aggregation: The optimizer distributes the aggregation operation to workers. Each worker contains all data in the groups. Therefore, the second-phase aggregation computing is not required. Each worker directly computes the final aggregation results of the groups to prevent the leader thread from performing a second aggregation.
Two-phase aggregation: In the first phase, each worker involved in elastic parallel query performs the aggregation. In the second phase, the gather node or gather merge node returns the results generated by each worker to the leader thread. Then, the leader thread aggregates the results from all workers to generate the final result.
Two-phase shuffle aggregation: In the first phase, each worker in the elastic parallel query performs the aggregation. In the second phase, the repartition node distributes the result generated by each worker to multiple workers by grouped columns. The workers complete the final aggregation computing in parallel. Finally, the aggregation results are summarized in the leader thread.
The PolarDB optimizer determines the specific aggregation method based on the cost.
Parallel window function
The PolarDB optimizer performs computing and distributes window functions to workers for parallel execution based on costs. Each worker computes a portion of data. The distribution method is determined by the key of the PARTITION BY clause in window functions. If window functions do not contain the PARTITION BY clause, serial computing is performed. If parallel computing can be performed at a later point in time, subsequent computing tasks are distributed to multiple workers for execution based on the cost to ensure maximum parallelization.
Support for subqueries
In an elastic parallel query, you can use one of the following policies to run subqueries:
Sequential execution in the leader thread
If subqueries do not support parallel processing, the subqueries in the leader thread are performed in sequence. For example, if two tables are joined by using a JOIN clause that references user-defined functions (UDFs), the subqueries are performed in sequence.
Parallel execution in the leader thread (another group of workers is used)
After an elastic parallel query plan is generated, if the execution plan of the leader thread includes the subqueries that support parallel processing, these parallel subqueries cannot be run in advance or run in parallel based on the shared access policy. For example, if the subqueries include window functions, the subqueries cannot run in parallel based on the shared access policy.
Shared access
After an elastic parallel query plan is generated, if the execution plans of workers reference the subqueries that support parallel processing, the PolarDB optimizer runs the parallel subqueries in advance. This way, the workers can directly access the results of the subqueries.
Pushed down
After an elastic parallel query plan is generated, if the execution plans of workers reference correlated subqueries, the workers run the correlated subqueries.