Spark on MaxCompute is a computing service that is provided by MaxCompute and compatible with open source Spark. This service provides a Spark computing framework based on unified computing resource and dataset permission systems. This service allows you to use your preferred development method to submit and run Spark jobs. Spark on MaxCompute can fulfill diverse data processing and analytics requirements.
Limits
You can use Spark on MaxCompute to perform the following operations:
Perform offline computing by using Spark components, such as GraphX, MLlib, Resilient Distributed Dataset (RDD), Spark SQL, and PySpark.
Read data from and write data to MaxCompute tables.
Reference files in MaxCompute.
Read data from and write data to services that are deployed in virtual private clouds (VPCs), such as ApsaraDB RDS, ApsaraDB for Redis, ApsaraDB for HBase, and services that are deployed on Elastic Compute Service (ECS) instances.
Read and write Object Storage Service (OSS) unstructured storage data.
You cannot use Spark on MaxCompute to perform the following operations:
Run interactive or computing jobs, such as Spark-Shell, Spark-SQL-Shell, PySpark-Shell, and Spark Streaming jobs.
Access MaxCompute external tables, built-in functions, and user-defined functions (UDFs).
Use checkpoints.
Benefits
Supports different versions of native Spark jobs.
MaxCompute supports native community Spark and is fully compatible with the APIs of all native Spark versions. Different versions of Spark can run in MaxCompute at the same time. Spark on MaxCompute provides native Spark web UIs.
Runs based on centralized computing resources.
Similar to MaxCompute SQL jobs and MapReduce jobs, Spark on MaxCompute runs based on the centralized computing resources that are purchased for MaxCompute projects.
Supports centralized data and permission management.
Spark on MaxCompute complies with the permissions that are configured for MaxCompute projects. This allows you to query data without the need to modify permissions on your MaxCompute projects.
Provides the same user experience as open source Spark.
Spark on MaxCompute provides the same user experience as open source Spark, such as open source application UIs and online interactions. Spark on MaxCompute supports native, open source, and real-time UIs that can be used to debug open source applications. Spark on MaxCompute also allows you to query historical logs. For some open source applications, Spark on MaxCompute can run real-time interactions in the backend. This implements an interactive experience.
Architecture
Spark on MaxCompute is an Alibaba Cloud solution that allows native Spark to run in MaxCompute.
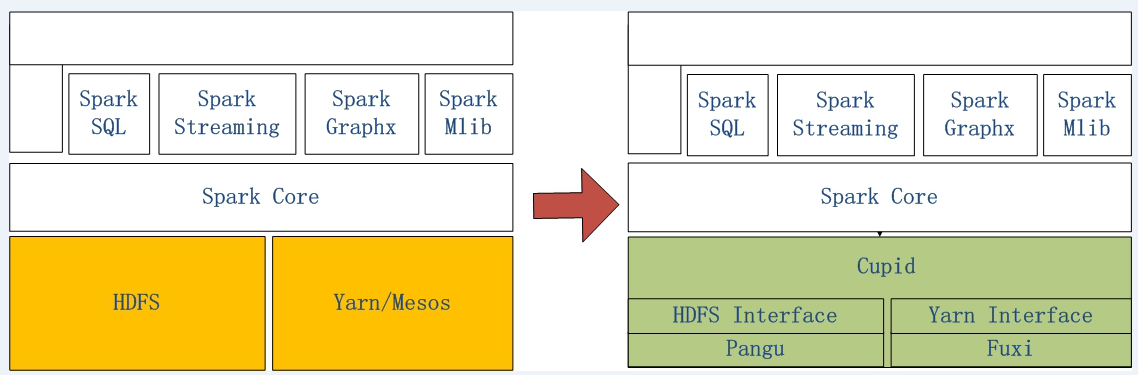
The left part of the preceding figure shows the architecture of native Spark. The right part shows the architecture of Spark on MaxCompute, which runs on the Cupid platform developed by Alibaba Cloud. The Cupid platform is fully compatible with the computing framework supported by open source YARN.