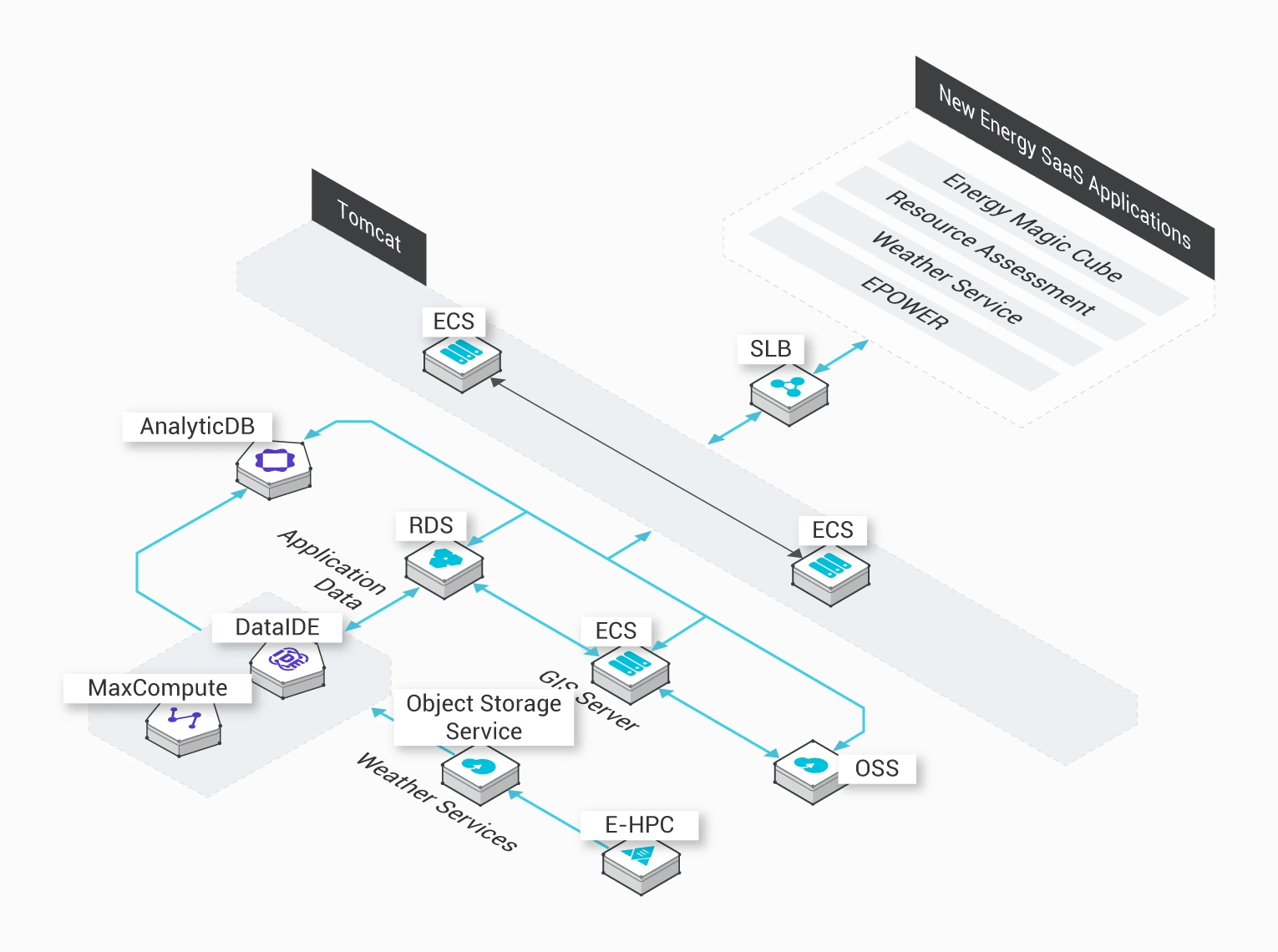
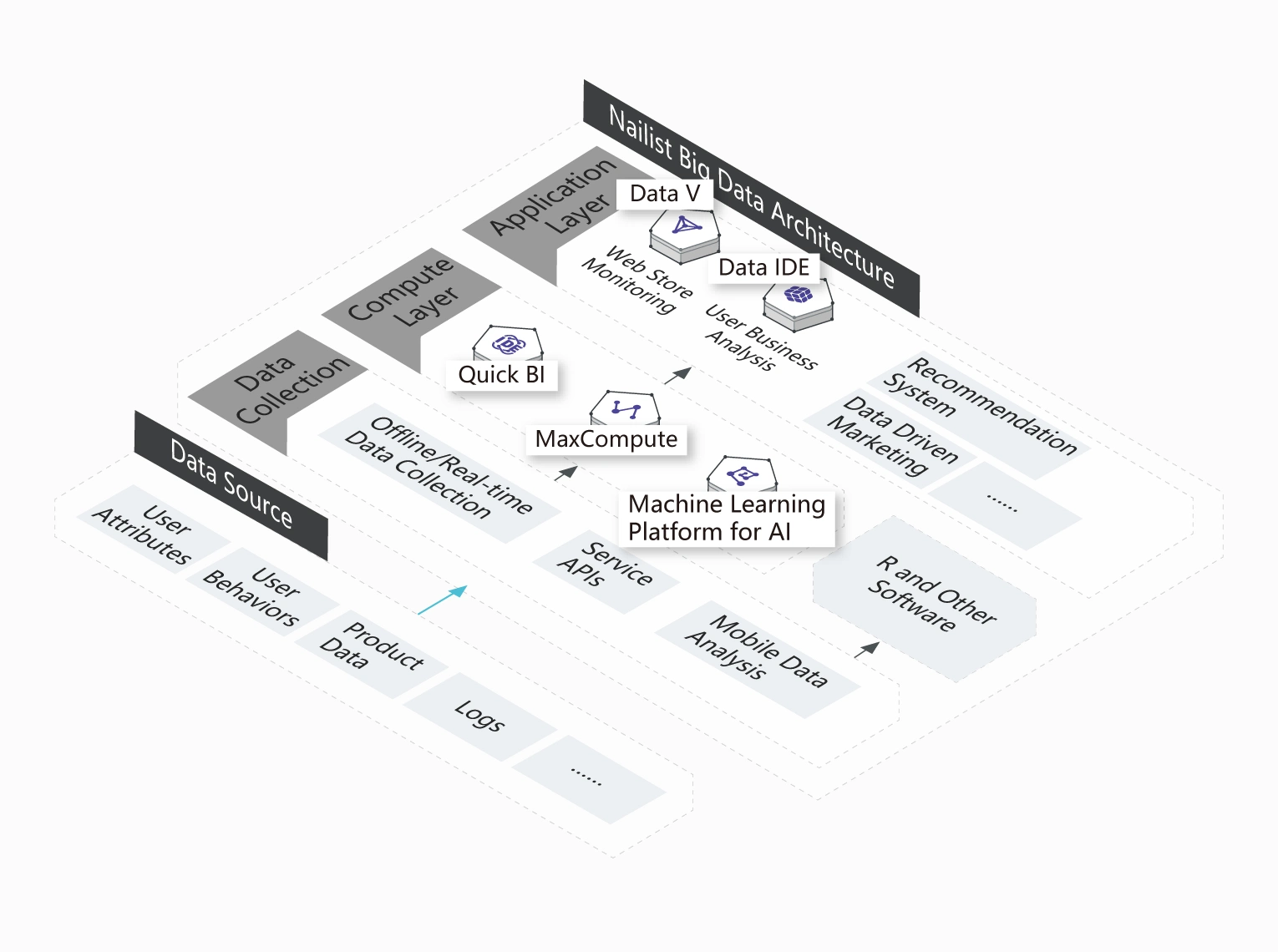
阿里雲 MaxCompute (原名 ODPS) 是一項全面寄存的 TB/PB 級快速數據庫解決方案,向用戶提供完善的數據導入方案,以及多種經典分佈式運算模型,可更快速解決用戶的海量數據運算問題,有效降低企業成本,並保障數據安全。
產品優勢
-
大規模運算儲存
適用於 100GB 以上規模的儲存及運算需求,最大可達 EB 級別
-
多種運算模型
支援 SQL、MapReduce、Graph 等運算類型及 MPI 迭代類運算法
-
數據安全穩妥
穩定支援 Alibaba 各項離線分析業務達 7 年以上,提供多層沙箱防護及監控

-
低成本
與企業自建私有雲端相比,運算儲存更高效,降低 20%-30% 採購成本
精心設計的功能
-
數據通道
支援批量/歷史數據通道和實時/增量數據通道
批量歷史數據通道
Tunnel 是 MaxCompute 向用戶提供的數據傳輸服務,其服務水平可擴展,支援每日 TB/PB 級數據導入導出,特別適合全量數據或歷史數據的批量導入。Tunnel 提供 Java SDK,且在 MaxCompute 的客戶端工具中有相應指令,讓內部文件與服務數據進行互通。
實時增量數據通道
另一方面,MaxCompute 針對實時數據上載場景,提供了另一套名為 DataHub 的服務。該項服務具有延遲低、使用方便等特點,特別適用於增量數據導入。Datahub 亦支援多種數據傳輸外掛程式,例如:Logstash、Flume、Fluentd、Sqoop 等;同時支援 Log Service 中的日誌數據一鍵投遞至 MaxCompute,進而利用大數據開發套件進行日誌分析和挖掘。
-
以二維表格儲存數據
所有數據均以表格儲存,不曝露文件系統,並採用列壓縮儲存格式,數據壓縮比例極高,顯著節省用戶成本。一般情況下,MaxCompute 儲存具備 5 倍壓縮功能
-
運算模型
支援 SQL、MapReduce、Graph 多種運算模型於一身
SQL
MaxCompute SQL 採用標準 SQL 語法,兼容部分 Hive 語法,在語法上與 HQL 非常接近,熟悉 SQL 或 HQL 的編程人員都容易上手。另外,MaxCompute 提供更高效的運算框架,支援 SQL 運算模型,執行效率比普通 MapReduce 模型更高。惟請留意:MaxCompute SQL 不支援事務、索引及 Update/Delete 等操作。
MapReduce
MaxCompute 可提供 Java MapReduce 編程模型。值得留意的是:由於 MaxCompute 並無開放文件接口,用戶只能透過其所提供的 Table 讀寫數據。因此,MaxCompute 的 MapReduce 模型與開源社群中通用的 MapReduce 模型在用法上有一定區別。我們深信:上述改動雖稍失靈活性 (例如:無法自訂排序及雜湊運算法),卻能簡化開發流程,免除眾多瑣碎工作。更重要的是:MaxCompute 亦提供了以 MapReduce 為基礎的擴展運算模型,即 MR2,在單一 Map 函數後可連續接入多個 Reduce 函數。
Graph
對於個別繁複迭代運算場景 (例如:K-Means、PageRank 等) 而言,如繼續使用 MapReduce 來完成運算任務,實在耗時甚長。MaxCompute 提供的 Graph 模型就能有效完成此類運算任務。
-
安全
MaxCompute 是多租戶運算平台。在預設情況下,各租戶之間數據不共享,彼此隔離;惟用戶可透過 MaxCompute 提供的授權機制,與項目組別內的其他組員共享數據。
領軍客戶實戰場景
-
使用成本低

-
大數據庫

-
日誌大數據分析

-
精密營運

-
精準廣告營銷

-
海量營銷數據分析