Designer提供自定义Python脚本的功能,您可以使用Python脚本组件自定义安装依赖包及运行自定义的Python函数。本文为您介绍Python脚本组件的配置方法及使用示例。
背景信息
Python脚本组件位于Designer组件的自定义算法组件文件夹下。
前提条件
已完成DLC相关权限授权,授权方法详情请参见云产品依赖与授权:DLC。
由于Python脚本需要依赖于DLC作为底层计算资源,因此您需要在工作空间关联DLC计算资源,详情请参见管理工作空间。
由于Python脚本依赖OSS作为代码存储环境,因此您需要先创建OSS Bucket,详情请参见创建存储空间。
重要创建的OSS Bucket必须与Designer和DLC在同一地域。
已在工作空间中,为使用该组件的RAM账号添加算法开发角色,详情请参见管理工作空间成员。如果操作账号还需同时使用MaxCompute作为数据源,还需要同时添加MaxCompute开发角色。
可视化配置组件
输入桩
Python脚本组件共有4个输入端口,均可以连接OSS路径或MaxCompute表类型的数据。
OSS路径输入
来自上游组件的OSS输入,会被挂载到Python脚本执行的节点上,系统会将挂载后的文件路径,以arguments的形式,传递给Python脚本,无需手工配置。arguments的规范如
python main.py --input1 /ml/input/data/input1,代表第一个输入端口输入的OSS路径。在Python脚本中可以按照读本地文件的方式访问/ml/input/data/input1来读取挂载后的文件。MaxCompute表输入
MaxCompute表的输入不支持挂载,系统会将对应的表信息以URI的形式,作为arguments传递给Python脚本,无需手工配置。arguments的规范如
python main.py --input1 odps://some-project-name/tables/table,代表第一个输入端口输入的MaxCompute表。对于MaxCompute URI形式的输入,您可以使用该组件代码模板内的parse_odps_url函数解析出对应的ProjectName、TableName和Partition等元信息,详情请参见使用示例。
输出桩
Python脚本组件共有4个输出端口,其中输出端口1和输出端口2是OSS路径输出端口,输出端口3和输出端口4是MaxCompute表输出端口。
OSS路径输出
该组件的脚本设置页签的任务输出路径参数配置的OSS路径,会被系统自动挂载到
/ml/output/下。该组件的输出端口OSS输出-1和OSS输出-2,分别对应子目录/ml/output/output1和/ml/output/output2。在脚本中可以按照写本地文件的方式将需要传递给下游节点的文件写到这两个目录中。MaxCompute表输出
如果当前工作空间配置了MaxCompute项目,系统会自动传递一个临时表URI到Python脚本,例如:
python main.py --output3 odps://<some-project-name>/tables/<output-table-name>,您可以通过PyODPS来创建临时表URI中指定的表,并将Python脚本处理完成的数据写出到这个表,最后通过组件连线将表传递给下游组件,详情可参考下文中的示例。
组件参数
脚本设置
参数
描述
任务输出路径
选择任务输出的OSS路径。
配置好的OSS目录会挂载到作业容器的
/ml/output/路径下,任务写出到/ml/output/路径下的数据,会被持久化保存到对应的OSS目录。组件的输出端口OSS输出-1和OSS输出-2分别对应
/ml/output/路径下的子路径output1和output2。当组件的OSS输出端口接入下游组件时,下游组件接收到的数据为对应子路径的数据。
设置代码源
(任选一种即可)
编辑框提交
Python代码:选择代码保存的OSS路径,编辑框中写入的代码会保存在该OSS路径下。Python代码的文件名称默认为main.py。
重要第一次单击保存前,请确认指定的代码保存路径下无同名文件,避免文件被覆盖。
Python代码编辑器:编辑框内默认提供示例代码,详情请参见使用示例。您可以直接在编辑器内编写代码。
指定Git配置
Git地址:Git仓库地址。
代码分支:代码分支,默认为master。
代码Commit:Commit的优先级大于Branch,如果您填写了该参数,则Branch不生效。
Git用户名:如果您需要访问私有代码集,则需要指定该参数。
Git访问Token:访问私有代码仓库时必填。更多信息,请参见附录:获取GitHub账号的Token。
选择代码配置
选择代码配置:选择已创建的代码配置。具体操作,请参见代码配置。
代码分支:代码分支,默认为master。
代码Commit:Commit的优先级大于Branch,如果您填写了该参数,则Branch不生效。
从OSS中选择文件或目录
在OSS路径选择对应代码上传的路径。
执行命令
在文本框中,输入您需要执行的命令,比如:
python main.py。说明系统会自动按照脚本名称和组件输入输出端口的连接情况来生成执行命令,无需手动配置。
高级选项
第三方依赖库:在文本框中,您可以通过添加脚本的方式安装第三方依赖库,格式与Python的requirement.txt相同,具体如下所示。节点执行前,会自动安装文本框中配置的第三方依赖库。
cycler==0.10.0 # via matplotlib kiwisolver==1.2.0 # via matplotlib matplotlib==3.2.1 numpy==1.18.5 pandas==1.0.4 pyparsing==2.4.7 # via matplotlib python-dateutil==2.8.1 # via matplotlib, pandas pytz==2020.1 # via pandas scipy==1.4.1 # via seaborn是否开启容错监控:勾选该参数后,会出现容错监控配置文本框,您可以在文本框中通过添加容错监控具体参数,指定容错监控的内容。
执行配置
参数
描述
选择资源组
支持选择DLC公共资源组:
当选择公共资源组时,您需要配置选择机器实例类型参数,支持配置CPU或GPU机器实例。默认为:
ecs.c6.large。
默认为当前工作空间下的DLC云原生资源的默认资源组。
专有网络配置
支持选择已创建的专有网络进行挂载。
安全组
支持选择已创建的安全组进行挂载。
高级选项
选中该参数后,支持配置以下参数:
选择机器实例个数:您可以按照实际需要配置机器实例个数,默认为1。
选择作业镜像:默认为开源的xgboost1.6.0版本,如果您需要使用深度学习框架,则需要修改镜像。
选择任务类型:仅当提交的代码按照分布式实现时,才需要修改该参数,支持以下取值:
XGBoost/LightGBM Job
TensorFlow Job
PyTorch Job
MPI Job
使用示例
默认示例代码解析
Python脚本组件默认提供的示例代码如下。
import os
import argparse
import json
"""
Python V2 组件示例代码
"""
# 当前工作空间下的默认MaxCompute执行环境,包含MaxCompute项目的名称以及Endpoint。
# 需要当前的工作空间下有MaxCompute项目时,作业的执行环境才会注入。
# 示例: {"endpoint": "http://service.cn.maxcompute.aliyun-inc.com/api", "odpsProject": "lq_test_mc_project"}。
ENV_JOB_MAX_COMPUTE_EXECUTION = "JOB_MAX_COMPUTE_EXECUTION"
def init_odps():
from odps import ODPS
# 当前工作空间的默认MaxCompute项目信息。
mc_execution = json.loads(os.environ[ENV_JOB_MAX_COMPUTE_EXECUTION])
o = ODPS(
access_id="<YourAccessKeyId>",
secret_access_key="<YourAccessKeySecret>",
# 请根据Project所在的Region选择,比如:http://service.cn-shanghai.maxcompute.aliyun-inc.com/api。
endpoint=mc_execution["endpoint"],
project=mc_execution["odpsProject"],
)
return o
def parse_odps_url(table_uri):
from urllib import parse
parsed = parse.urlparse(table_uri)
project_name = parsed.hostname
r = parsed.path.split("/", 2)
table_name = r[2]
if len(r) > 3:
partition = r[3]
else:
partition = None
return project_name, table_name, partition
def parse_args():
parser = argparse.ArgumentParser(description="PythonV2 component script example.")
parser.add_argument("--input1", type=str, default=None, help="Component input port 1.")
parser.add_argument("--input2", type=str, default=None, help="Component input port 2.")
parser.add_argument("--input3", type=str, default=None, help="Component input port 3.")
parser.add_argument("--input4", type=str, default=None, help="Component input port 4.")
parser.add_argument("--output1", type=str, default=None, help="Output OSS port 1.")
parser.add_argument("--output2", type=str, default=None, help="Output OSS port 2.")
parser.add_argument("--output3", type=str, default=None, help="Output MaxComputeTable 1.")
parser.add_argument("--output4", type=str, default=None, help="Output MaxComputeTable 2.")
args, _ = parser.parse_known_args()
return args
def write_table_example(args):
# 示例:通过执行SQL语句复制PAI提供的公共表数据,作为当前组件输出端口3指定的临时表。
output_table_uri = args.output3
o = init_odps()
project_name, table_name, partition = parse_odps_url(output_table_uri)
o.run_sql(f"create table {project_name}.{table_name} as select * from pai_online_project.heart_disease_prediction;")
def write_output1(args):
# 示例:将数据结果写入挂载的OSS路径(输出端口1的子目录),对应的结果可以通过连线传递到下游组件。
output_path = args.output1
os.makedirs(output_path, exist_ok=True)
p = os.path.join(output_path, "result.text")
with open(p, "w") as f:
f.write("TestAccuracy=0.88")
if __name__ == "__main__":
args = parse_args()
print("Input1={}".format(args.input1))
print("Output1={}".format(args.output1))
# write_table_example(args)
# write_output1(args)
常用函数说明:
init_odps():初始化一个ODPS实例,用来读取MaxCompute表数据,需要填写您的AccessKeyId和AccessKeySecret,关于如何获取AccessKey,详情请参见获取AccessKey。
parse_odps_url(table_uri):解析输入的MaxCompute表的URI,返回解析完成得到的项目名称、表名和分区。table_uri格式为:
odps://${your_projectname}/tables/${table_name}/${pt_1}/${pt_2}/,比如:odps://test/tables/iris/pa=1/pb=1,其中pa=1/pb=1为一个多级分区。parse_args():解析传入脚本的arguments,输入输出数据会以arguments的方式传递给执行的脚本。
使用示例1:Python脚本组件与其他组件串联使用
参考并修改心脏病预测案例模板,来说明Python脚本组件如何与Designer其他组件串联使用。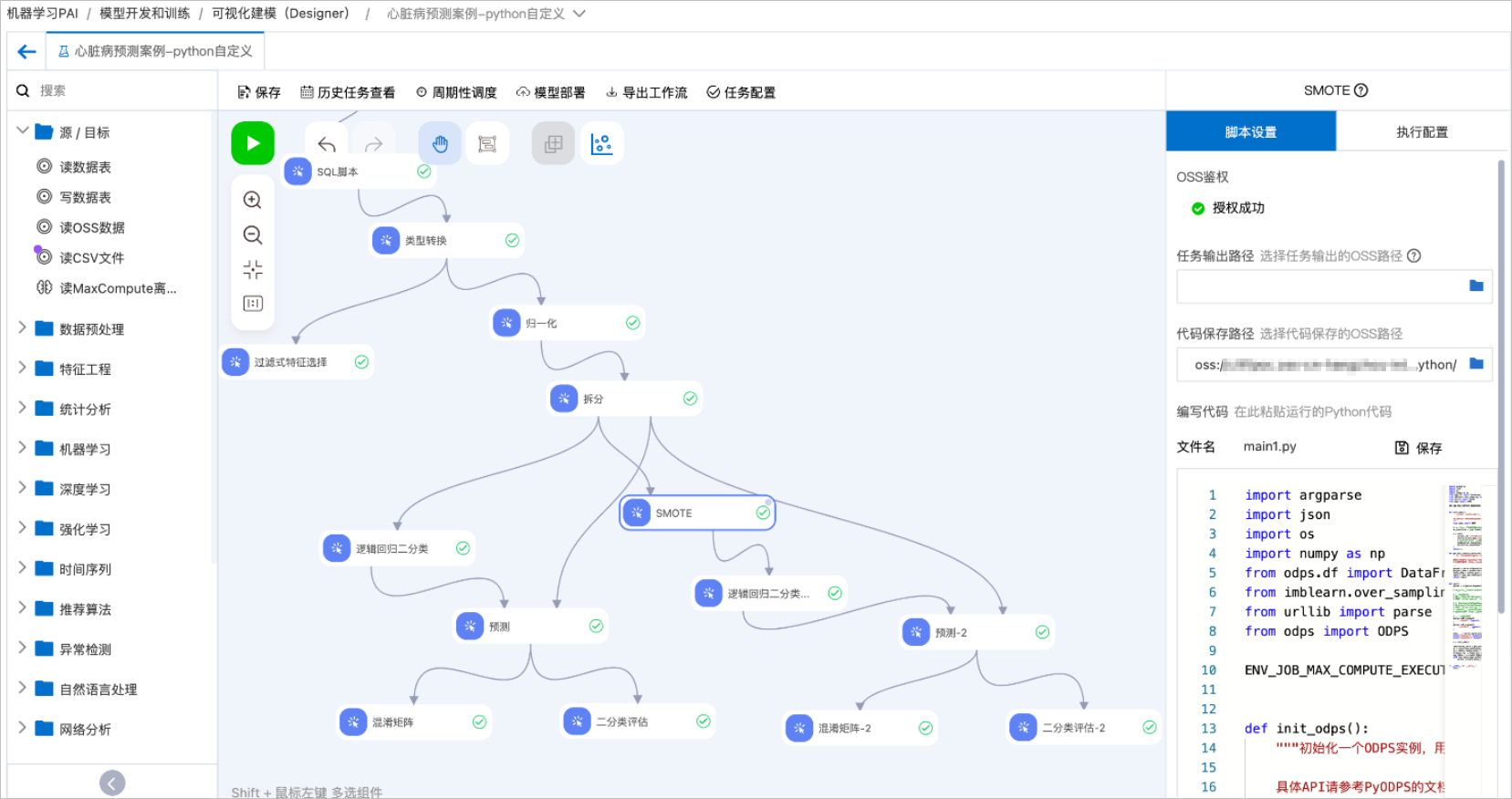 工作流配置说明:
工作流配置说明:
创建心脏病预测案例模板并进入工作流,具体操作请参见心脏病预测。
将Python脚本组件拖入画布并重命名为SMOTE,并配置以下代码。
重要在我们使用的镜像中没有imblearn库,需要在该组件的脚本设置页签的第三方依赖库中配置imblearn。在节点执行前,会自动安装该库。
import argparse import json import os from odps.df import DataFrame from imblearn.over_sampling import SMOTE from urllib import parse from odps import ODPS ENV_JOB_MAX_COMPUTE_EXECUTION = "JOB_MAX_COMPUTE_EXECUTION" def init_odps(): # 当前工作空间的默认MaxCompute项目信息。 mc_execution = json.loads(os.environ[ENV_JOB_MAX_COMPUTE_EXECUTION]) o = ODPS( access_id="<替换成您自己的AccessKey>", secret_access_key="<替换成您自己的AccessKeySecret>", # 请根据Project所在的Region选择,比如:http://service.cn-shanghai.maxcompute.aliyun-inc.com/api。 endpoint=mc_execution["endpoint"], project=mc_execution["odpsProject"], ) return o def get_max_compute_table(table_uri, odps): parsed = parse.urlparse(table_uri) project_name = parsed.hostname table_name = parsed.path.split('/')[2] table = odps.get_table(project_name + "." + table_name) return table def run(): parser = argparse.ArgumentParser(description='PythonV2 component script example.') parser.add_argument( '--input1', type=str, default=None, help='Component input port 1.' ) parser.add_argument( '--output3', type=str, default=None, help='Component input port 1.' ) args, _ = parser.parse_known_args() print('Input1={}'.format(args.input1)) print('output3={}'.format(args.output3)) o = init_odps() imbalanced_table = get_max_compute_table(args.input1, o) df = DataFrame(imbalanced_table).to_pandas() sm = SMOTE(random_state=2) X_train_res, y_train_res = sm.fit_resample(df, df['ifhealth'].ravel()) new_table = o.create_table(get_max_compute_table(args.output3, o).name, imbalanced_table.schema, if_not_exists=True) with new_table.open_writer() as writer: writer.write(X_train_res.values.tolist()) if __name__ == '__main__': run()其中access_id和secret_access_key需要配置您自己的AccessKey和AccessKeySecret。关于如何获取AccessKey,详情请参见获取AccessKey。
将SMOTE组件接入拆分组件的下游,使用经典的SMOTE算法对拆分完得到的训练数据做过采样,对训练集里样本数量较少的类别进行过采样,合成新的样本来缓解类不平衡。
将SMOTE组件得到的新数据接入逻辑回归二分类组件做训练。
将训练得到的模型与左侧分支中的模型一样,连接相同的预测数据和评估组件做横向对比。组件运行成功后,单击
 进入可视化页面,查看最终评估结果。
进入可视化页面,查看最终评估结果。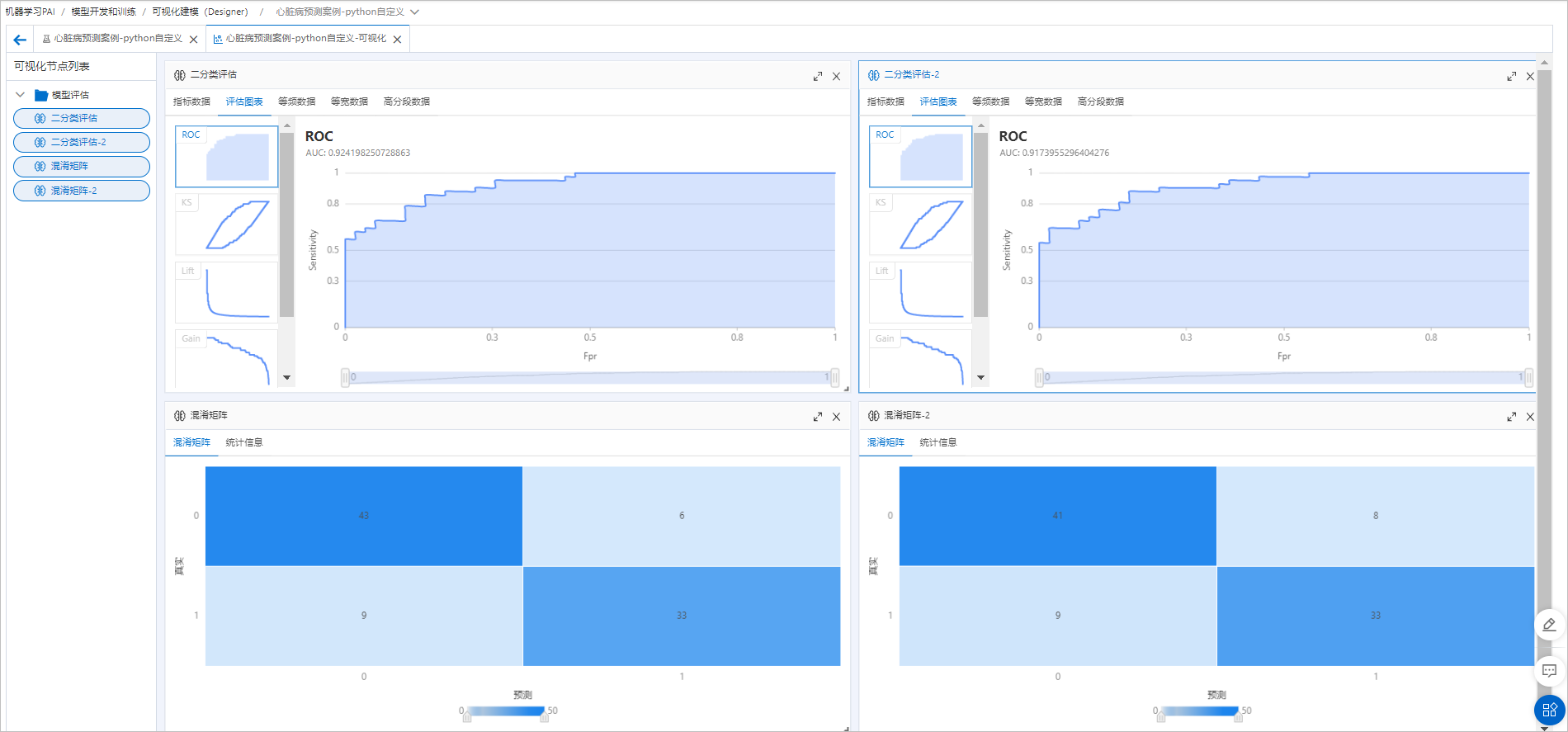
额外做过采样并未对模型效果有特别明显的提升,说明原样本分布及模型效果都比较好。
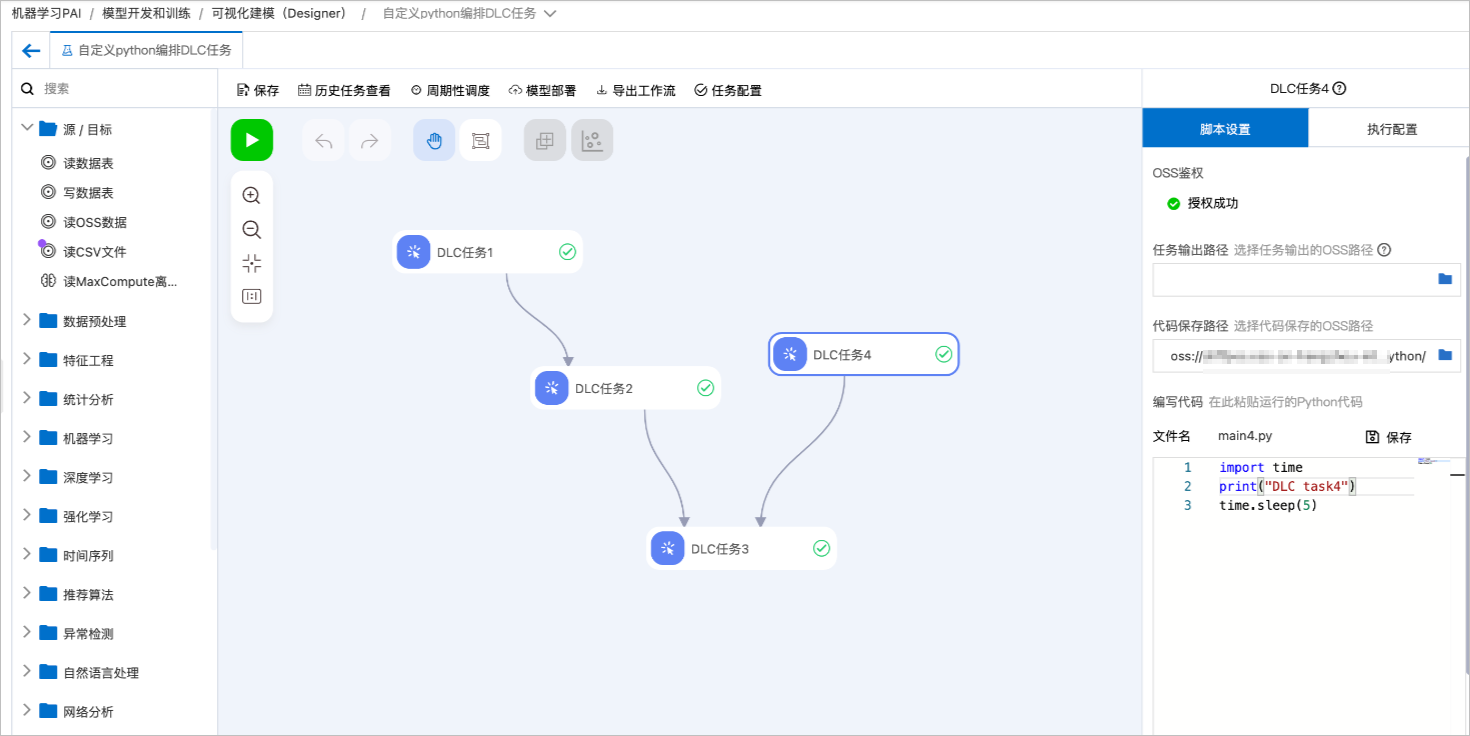
使用示例2:使用Designer做纯DLC任务的编排
您可以在Designer中连接多个自定义Python脚本组件,来实现一组DLC任务的Pipeline编排和定时调度。以下图为例,按照Directed Acyclic Graph(DAG)图顺序启动4个DLC任务。
如果DLC的执行代码不需要读取上游节点数据,也不需要给下游节点传递数据,则节点之间的连线只表示调度执行的依赖关系和先后顺序。
 后续您可以将使用Designer开发完成的整个工作流,一键部署到DataWorks做定时调度,具体操作请参见使用DataWorks离线调度Designer工作流。
后续您可以将使用Designer开发完成的整个工作流,一键部署到DataWorks做定时调度,具体操作请参见使用DataWorks离线调度Designer工作流。
使用示例3:将全局变量传入Python脚本组件
配置全局变量。
在Designer工作流页面单击空白画布,在右侧全局变量页签配置全局变量。
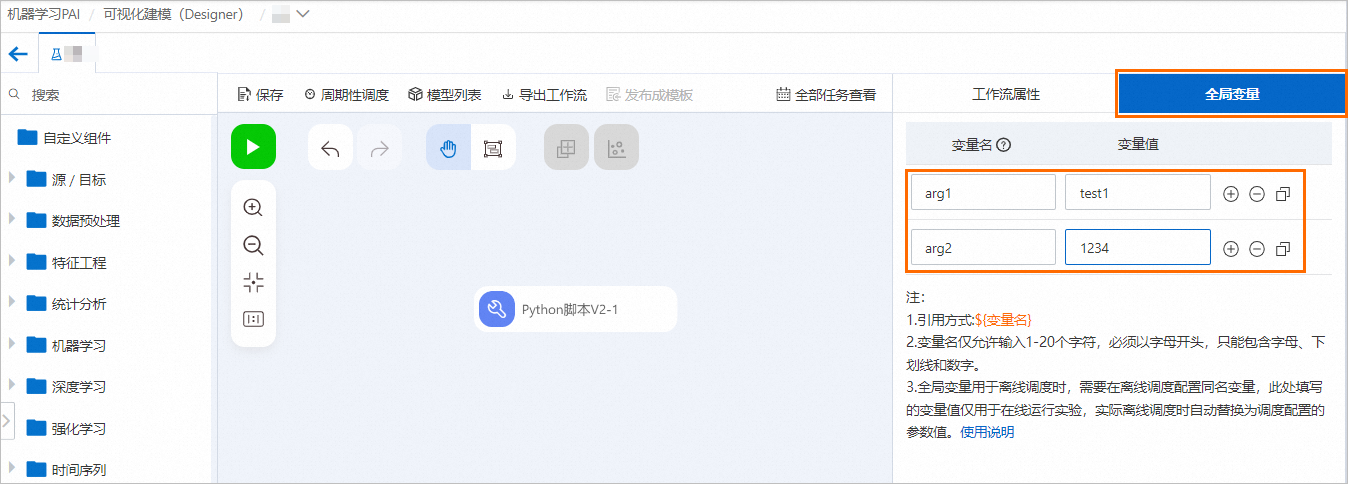
使用以下两种方式将已配置的全局变量传入Python脚本组件,您可以任意选择一种方式。
单击Python脚本组件节点,在右侧脚本设置页签选中高级选项,在执行命令中配置传入参数为全局变量。
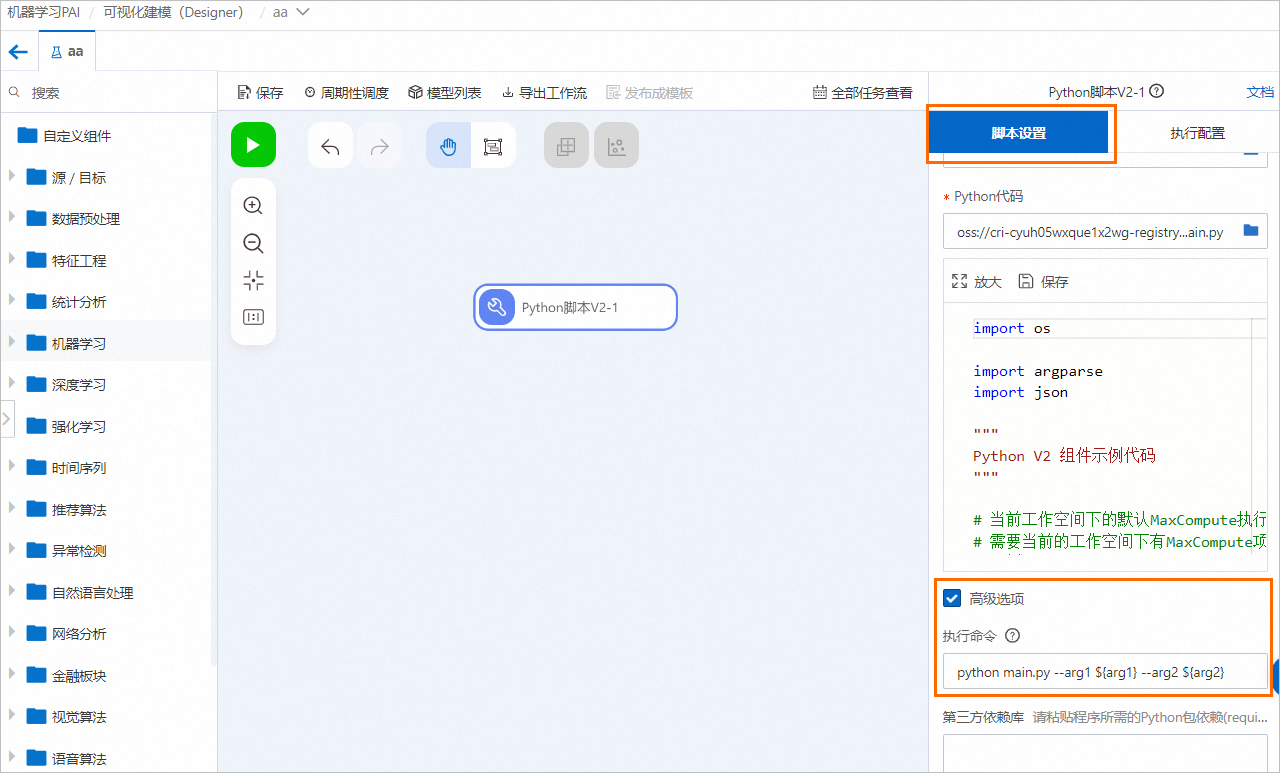
修改Python代码,使用argparser解析参数。
更新后的Python代码如下,该代码以步骤1配置的全局变量为例,您需要根据实际配置的全局变量更新代码。后续您可以直接将更新后的代码替换到Python脚本组件节点脚本设置页签的代码编辑区域。
import os import argparse import json """ Python V2 组件示例代码 """ ENV_JOB_MAX_COMPUTE_EXECUTION = "JOB_MAX_COMPUTE_EXECUTION" def init_odps(): from odps import ODPS mc_execution = json.loads(os.environ[ENV_JOB_MAX_COMPUTE_EXECUTION]) o = ODPS( access_id="<YourAccessKeyId>", secret_access_key="<YourAccessKeySecret>", endpoint=mc_execution["endpoint"], project=mc_execution["odpsProject"], ) return o def parse_odps_url(table_uri): from urllib import parse parsed = parse.urlparse(table_uri) project_name = parsed.hostname r = parsed.path.split("/", 2) table_name = r[2] if len(r) > 3: partition = r[3] else: partition = None return project_name, table_name, partition def parse_args(): parser = argparse.ArgumentParser(description="PythonV2 component script example.") parser.add_argument("--input1", type=str, default=None, help="Component input port 1.") parser.add_argument("--input2", type=str, default=None, help="Component input port 2.") parser.add_argument("--input3", type=str, default=None, help="Component input port 3.") parser.add_argument("--input4", type=str, default=None, help="Component input port 4.") parser.add_argument("--output1", type=str, default=None, help="Output OSS port 1.") parser.add_argument("--output2", type=str, default=None, help="Output OSS port 2.") parser.add_argument("--output3", type=str, default=None, help="Output MaxComputeTable 1.") parser.add_argument("--output4", type=str, default=None, help="Output MaxComputeTable 2.") # 根据已配置的全局变量,新增代码。 parser.add_argument("--arg1", type=str, default=None, help="Argument 1.") parser.add_argument("--arg2", type=int, default=None, help="Argument 2.") args, _ = parser.parse_known_args() return args def write_table_example(args): output_table_uri = args.output3 o = init_odps() project_name, table_name, partition = parse_odps_url(output_table_uri) o.run_sql(f"create table {project_name}.{table_name} as select * from pai_online_project.heart_disease_prediction;") def write_output1(args): output_path = args.output1 os.makedirs(output_path, exist_ok=True) p = os.path.join(output_path, "result.text") with open(p, "w") as f: f.write("TestAccuracy=0.88") if __name__ == "__main__": args = parse_args() print("Input1={}".format(args.input1)) print("Output1={}".format(args.output1)) # 根据已配置的全局变量,新增代码。 print("Argument1={}".format(args.arg1)) print("Argument2={}".format(args.arg2)) # write_table_example(args) # write_output1(args)