DeepSeek-R1是由深度求索公司推出的模型,其在数学、代码和推理任务上的表现优异。本文以蒸馏模型DeepSeek-R1-Distill-Qwen-7B为例,为您介绍如何微调该系列模型。
支持的模型列表
PAI-Model Gallery支持对六个蒸馏模型进行LoRA监督微调(SFT)。下表展示了使用默认超参数和提供的数据集时推荐的最低计算配置:
蒸馏模型 | 基础模型 | 支持的训练方式 | 最低配置 |
DeepSeek-R1-Distill-Qwen-1.5B | LoRA 监督微调 | 1卡A10(24 GB显存) | |
DeepSeek-R1-Distill-Qwen-7B | 1卡A10(24 GB显存) | ||
DeepSeek-R1-Distill-Llama-8B | 1卡A10(24 GB显存) | ||
DeepSeek-R1-Distill-Qwen-14B | 1卡GU8IS(48 GB显存) | ||
DeepSeek-R1-Distill-Qwen-32B | 2卡GU8IS(48 GB显存) | ||
DeepSeek-R1-Distill-Llama-70B | 8卡GU100(80 GB显存) |
快速开始
进入Model Gallery页面。
登录PAI控制台,左侧导航栏选择并进入目标工作空间。
在左侧导航栏选择快速开始 > Model Gallery。
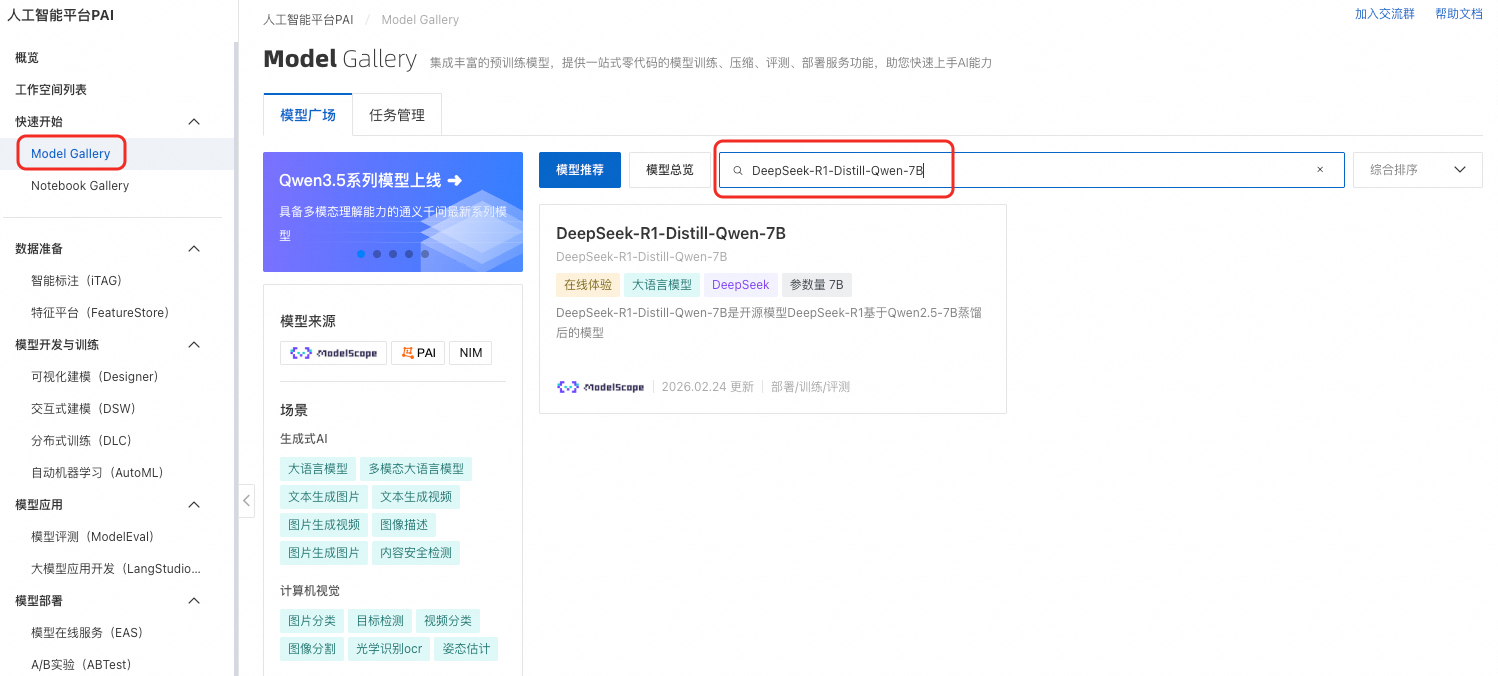
在Model Gallery页面,搜索并单击DeepSeek-R1-Distill-Qwen-7B模型卡片,进入模型详情页面。该页面包含模型训练、部署的详细信息,比如SFT监督微调数据格式的说明以及模型调用方式。

单击右上角训练。关键配置如下:
数据集配置:本例使用默认数据集。您也可以按照模型卡片详情页的数据格式要求准备自定义数据集,并上传到对象存储OSS Bucket中。
模型输出路径:用于存储微调训练后的模型,按需选择OSS路径。
计算资源配置:资源来源选择公共资源,资源规格选择
ecs.gn7i-c16g1.4xlarge。:LoRA监督微调支持的超参信息如下,可按需调整。具体操作,请参见大语言模型微调指引。
单击训练,Model Gallery自动跳转到模型训练页面,并开始进行训练。您可以查看训练任务状态和训练日志。
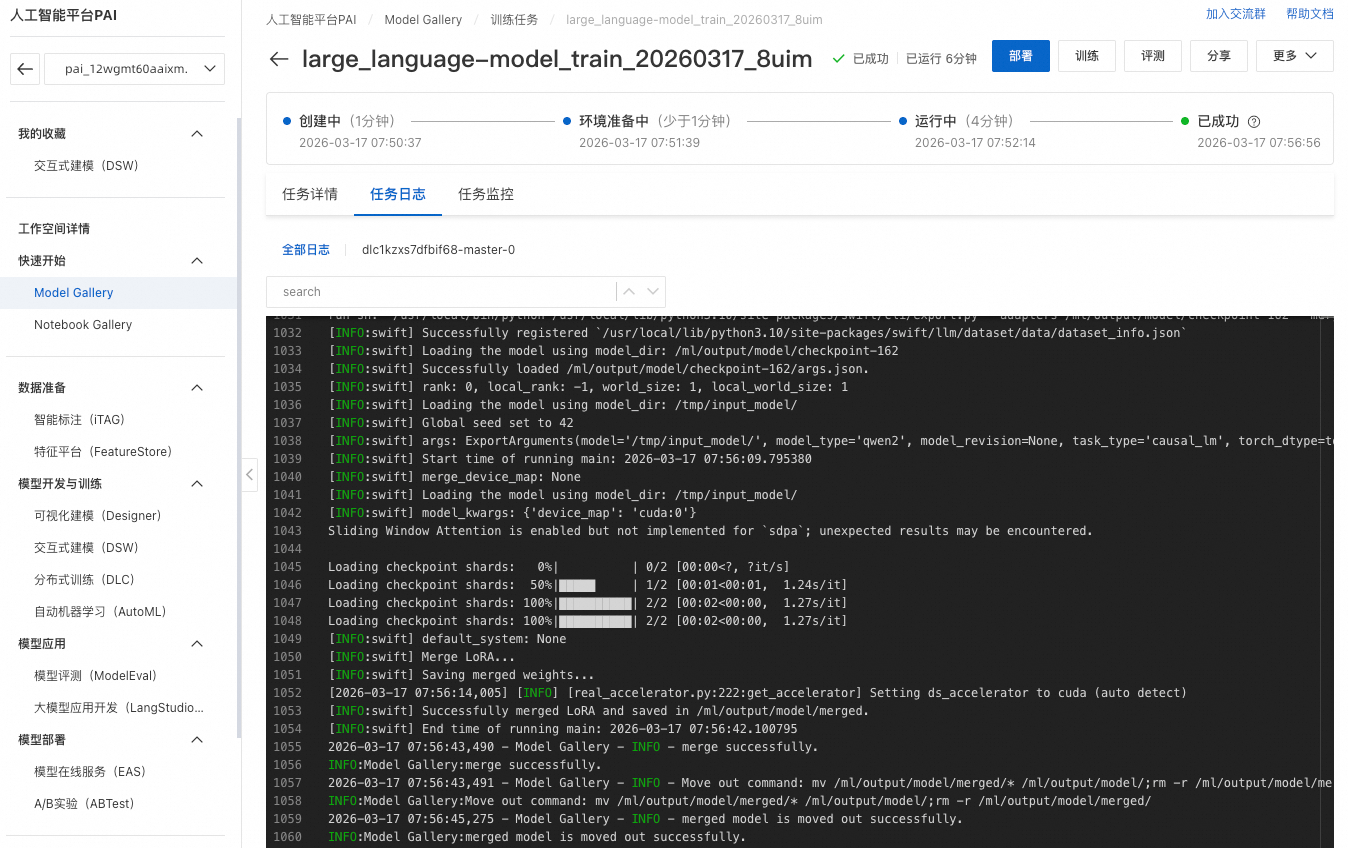
训练任务成功,训练好的模型会自动注册到AI资产-模型管理中,您可以查看或部署对应的模型,详情请参见注册及管理模型。
待训练成功后,单击右上角部署,即可将训练好的模型部署为EAS服务。部署完毕的模型的调用方式与原来的蒸馏模型一致,可参考模型详情页或一键部署DeepSeek-V3、DeepSeek-R1模型。
计费说明
在Model Gallery中进行模型训练,是使用的DLC的训练能力。DLC按照任务训练时长来收费,计费详情请参见分布式训练(DLC)计费说明。
常见问题
Q:训练任务失败如何排查?
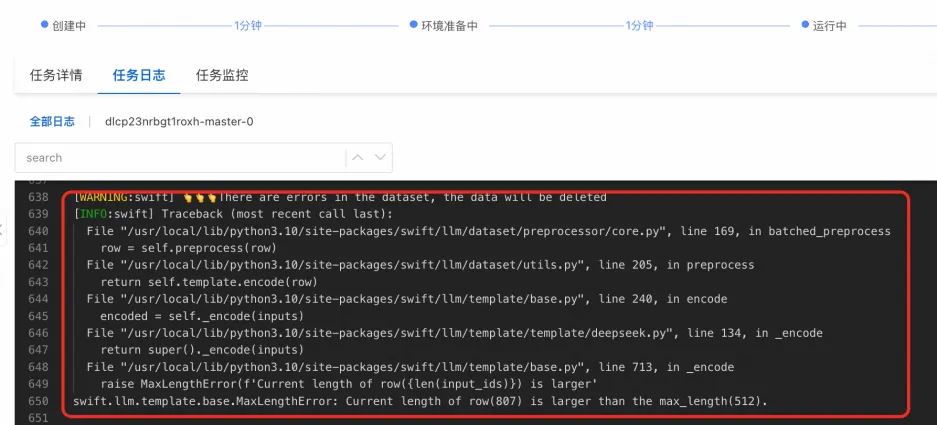
训练时请设置合适的 max_length(训练配置中的超参),训练算法中会对超过 max_length 的数据直接进行删除,并在任务日志中打印如下内容:
 有可能会出现删除数据过多导致训练/验证数据集为空,导致训练任务失败的情况:
有可能会出现删除数据过多导致训练/验证数据集为空,导致训练任务失败的情况: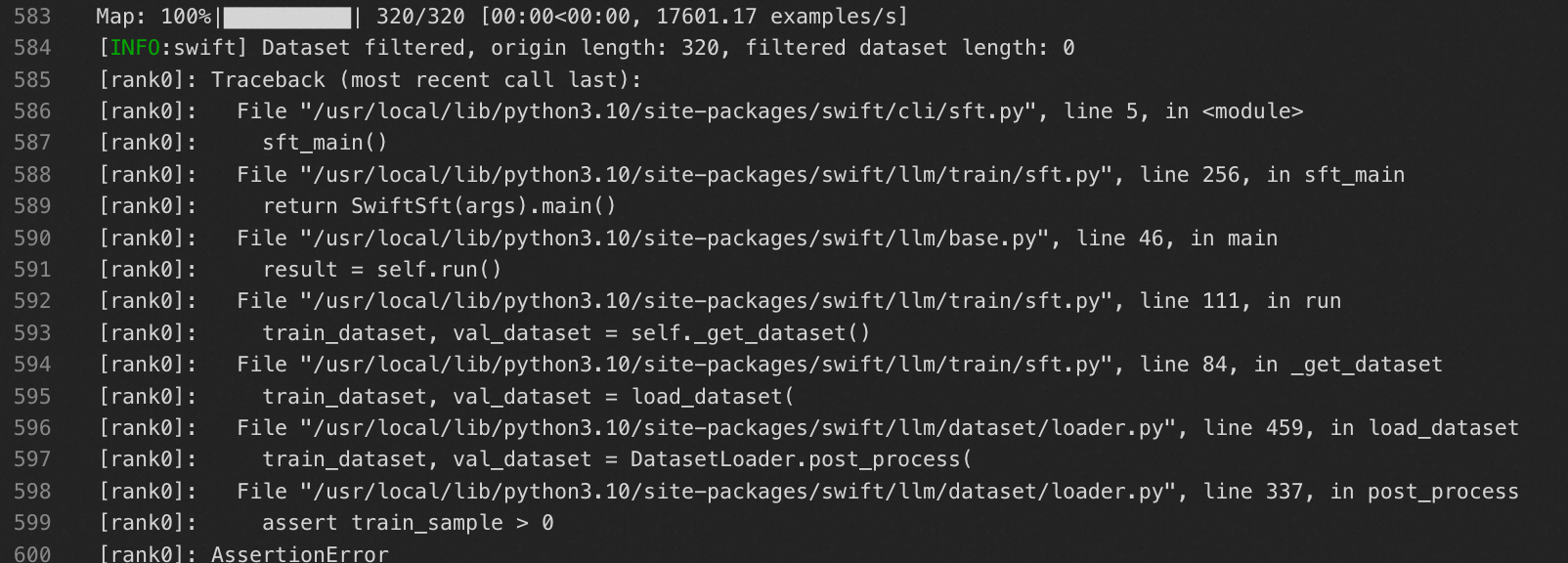
出现以下错误日志:
failed to compose dlc job specs, resource limiting triggered, you are trying to use more GPU resources than the threshold,是因为训练任务当前限制最多同时运行2*GPU,超过会触发资源限制。请等待正在运行中的训练任务完成再启动,或提交工单申请增加配额。出现以下错误日志:
the specified vswitch vsw-**** cannot create the required resource ecs.gn7i-c32g1.8xlarge, zone not match。这是因为部分规格在交换机所在可用区没有资源了。您可以尝试以下方式解决:1. 不选择交换机(DLC后端会自己根据库存选择对应可用区的交换机)2. 切换其他资源规格。
Q:训练后模型可以下载么?
创建训练任务时,支持设置模型输出路径到OSS目录,然后您可以从OSS下载到本地。

Q:模型效果不好怎么办?
可以考虑以下方案:
更换效果较好的模型,如deepseek或qwen3系列参数量较大的模型。
调整提示词。
增大max_tokens值。
拆分问题让模型分别完成。